我会尽力帮忙翻译。以下是需要翻译的内容:
以下是我用于此的代码:
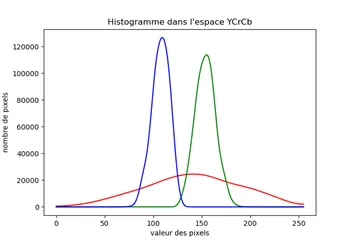
在从不同的皮肤中提取所有颜色之后,我正在创建一个直方图,以便我可以看到哪些颜色更常见。代码太长了,无法创建直方图,但这是结果:
我不断地更改间隔,测试和计算准确性,以找到每个颜色空间最佳间隔。这种更改是通过将距离乘以介于0和2之间的数字来完成的。例如:
我正在尝试找到一组适合颜色掩码的间隔,以便从图像中提取皮肤。
我有一个包含图像和掩模的数据库,可以从这些图像中提取皮肤。以下是一个示例:

我正在对每张图片应用掩模,以便获得类似于这样的效果:

以下是我用于此的代码:
for i, (img_color, img_mask) in enumerate ( zip(COLORED_IMAGES, MASKS) ) :
# masking
img_masked = cv2.bitwise_and(img_color, img_mask)
# transforming into pixels array
img_masked_pixels = img_masked.reshape(len(img_masked) * len(img_masked[0]), len(img_masked[0][0]))
# merging all pixels from all samples
if i == 0:
all_pixels = img_masked_pixels
else:
all_pixels = np.concatenate((all_pixels, img_masked_pixels), axis = 0)
# removing black
all_pixels = all_pixels[ ~ (all_pixels == 0).all(axis = 1) ]
# sorting pixels
all_pixels = np.sort(all_pixels)
# reshape into 1 NB_PIXELSx1 image in order to create histogram
all_pixels = all_pixels.reshape(len(all_pixels), 1, 3)
# creating image NB_PIXELSx1 image containing all skin colors from dataset samples
all_pixels = cv2.cvtColor(all_pixels, cv2.COLOR_BGR2YCR_CB)
在从不同的皮肤中提取所有颜色之后,我正在创建一个直方图,以便我可以看到哪些颜色更常见。代码太长了,无法创建直方图,但这是结果:
然后,我为每个颜色空间图选择一个转折点,并选择该颜色空间的距离,比如20。该颜色空间的区间是通过计算 [ 转折点 - 20,转折点 + 20 ] 得到的。
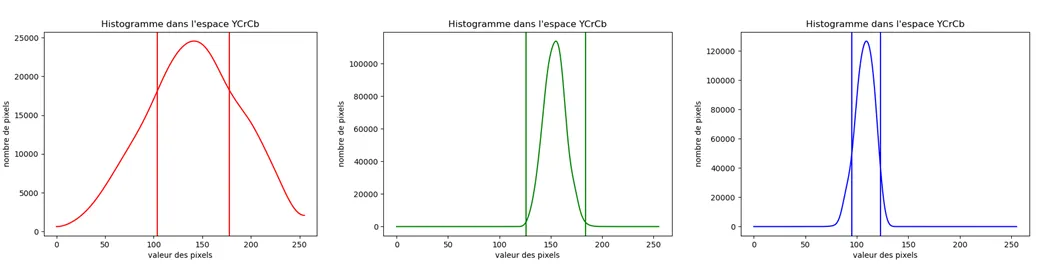
假设我们得到了以下内容:
R :
- 转折点: 142
- 距离: 61
- 间隔: [81, 203]
G :
- 转折点: 155
- 距离: 10
- 间隔: [145, 165]
B :
- 转折点: 109
- 距离: 14
- 间隔: [95, 123]
我会使用这些间隔来创建数据集中彩色图像的蒙版,以提取皮肤(左侧:我的蒙版,右侧:真实蒙版):

precision_moy = 0
accuracy_moy = 0
for i, (image, img) in enumerate ( zip(COLORED, GROUND_TRUTH) ) :
Min = np.array([81, 145, 95], np.uint8)
Max = np.array([203, 165, 123], np.uint8)
mask = cv2.inRange (image, Min, Max)
TP = 0 # True Positive
TN = 0 # True Negative
FP = 0 # False Positive
FN = 0 # False Negative
for i in range(mask.shape[0]) :
for j in range(mask.shape[1]) :
if mask[i,j] == 255 and img[i,j,0] == 255:
TP = TP + 1
if mask[i,j] == 0 and img[i,j,0] == 0:
TN = TN+1
if mask[i,j] == 255 and img[i,j,0] == 0:
FP = FP+1
if mask[i,j] == 0 and img[i,j,0] == 255:
FN = FN+1
precision = TP/(TP+FP)
accuracy = (TP+TN)/(TP+TN+FP+FN)
precision_moy = precision_moy + precision
accuracy_moy = accuracy_moy + accuracy
precision_moy = precision_moy / len(COLORED)
accuracy_moy = accuracy_moy / len(COLORED)
我不断地更改间隔,测试和计算准确性,以找到每个颜色空间最佳间隔。这种更改是通过将距离乘以介于0和2之间的数字来完成的。例如:
旧R:
- 转折点:142
- 距离:61
- 间隔:[81, 203]
新距离=旧距离*0.7=61*0.7=43
新R:
- 转折点:142
- 距离:43
- 间隔:[99, 185]
- 为了获得更高的间隔,我会乘以1到2之间的数字
- 为了获得较小的间隔,我会乘以0到1之间的数字
现在,我的问题是:
我想使用优化方法而不是手动和随机更改间隔来找到每个颜色空间的最佳可能间隔。我应该使用什么优化方法,如何使用它?
感谢您花费时间。感谢您的帮助。