我将尝试使用
考虑以下数据框
但是它返回以下错误:
我知道我可以用几行额外的代码来解决这个问题,例如创建一个辅助变量的子集数据,重新排序它,然后将级别顺序带到原始数据集中的因子。我仍然希望有一个更漂亮的解决方案,因为我经常面临这个非常相同的任务。
forcats::fct_reorder()函数来重新排列数据框的一个子集中的因子,该子集由另一个因子定义。考虑以下数据框
df:set.seed(12)
df <- data.frame(fct1 = as.factor(rep(c("A", "B", 'C'), each = 200)),
fct2 = as.factor(rep(c("j", "k"), each = 100)),
val = c(rnorm(100, 2), # A - j
rnorm(100, 1), # A - k
rnorm(100, 1), # B - j
rnorm(100, 6), # B - k
rnorm(100, 8), # C - j
rnorm(100, 4)))# C - k
我想使用ggridges包绘制分面组密度图。例如:
ggplot(data = df, aes(y = fct2, x = val)) +
stat_density_ridges(geom = "density_ridges_gradient",
calc_ecdf = T,
quantile_fun = median,
quantile_lines = T) +
facet_wrap(~fct1, ncol = 1)
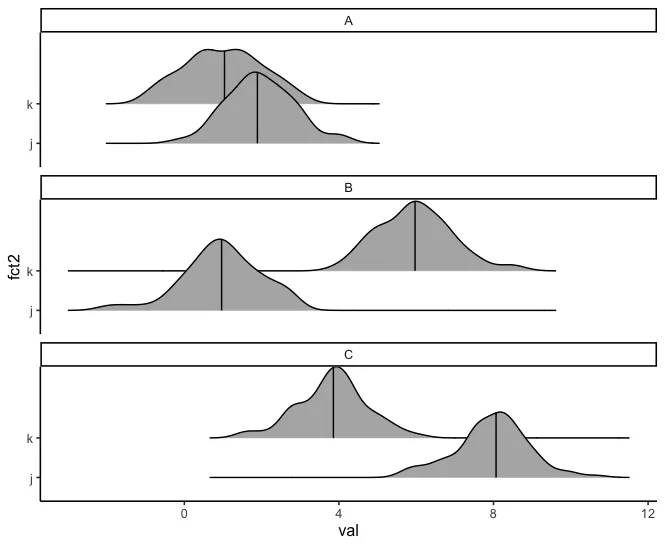
fct_reorder()中默认)来订购fct1,即fct2 ==“k”的地方。因此,在这个例子中的目标是出现的分面顺序为B-C-A。
这似乎与 这里的问题非常相似,不同之处在于我不想先对数据进行汇总,因为我需要原始数据来绘制密度图。
我试图改编链接问题答案中的代码:df <- df %>% mutate(fct1 = forcats::fct_reorder(fct1, filter(., fct2 == 'k') %>% pull(val)))
但是它返回以下错误:
很明显它们的长度不同,但我不太明白为什么这个错误是必要的。我猜测通常不能保证所有在 forcats::fct_reorder(fct1, filter(., fct2 == "k") %>% pull(val)) 中出现错误:
length(f) == length(.x) 不为 TRUE
fct1 的水平都存在于子集中,这肯定会有问题。然而,在我的例子中并非如此。是否有一种方法可以解决这个错误或者我更普遍地做错了什么?我知道我可以用几行额外的代码来解决这个问题,例如创建一个辅助变量的子集数据,重新排序它,然后将级别顺序带到原始数据集中的因子。我仍然希望有一个更漂亮的解决方案,因为我经常面临这个非常相同的任务。
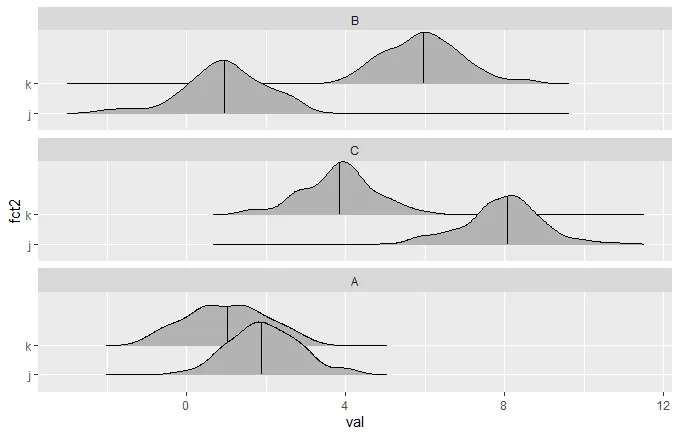
ggridges只是一个例子,但在分组条形图、箱线图等中也经常出现。另外,离题一点:代码的美妙之处不就在于它通常需要比解释你正在做什么的文字更少的字符吗? :) - PRZ