我刚接触机器学习,正在按照这个教程学习如何基于一些期货进行加密货币预测。
以下是我的代码进行预测:
model = load_model("Path//myModel.model")
ready_x = preprocess_df(main_df) # the function returns array of price sequences and targets (0-buy,1-sells): return np.array(X), y
predictions = []
for x in ready_x:
l_p = model.predict_classes(x) #error occurs on this line
predictions.append(l_p[0])
plot_prediction(main_df, predictions)
但我遇到了以下错误:
我真的不太明白这个错误的意思,这是我在著名的猫和狗分类之后进行的第二个机器学习项目。因此,在调试方面并没有太多经验,我确实先学习了神经元的理论以及它们之间的关系,但将这些知识应用于实际项目仍然非常困难。因此,这个项目的想法是基于过去60分钟的价格(在其上进行训练)来预测未来3分钟的价格。ValueError:检查输入时出错:预期lstm_input有3个维度,但得到的数组形状为(69188,1)
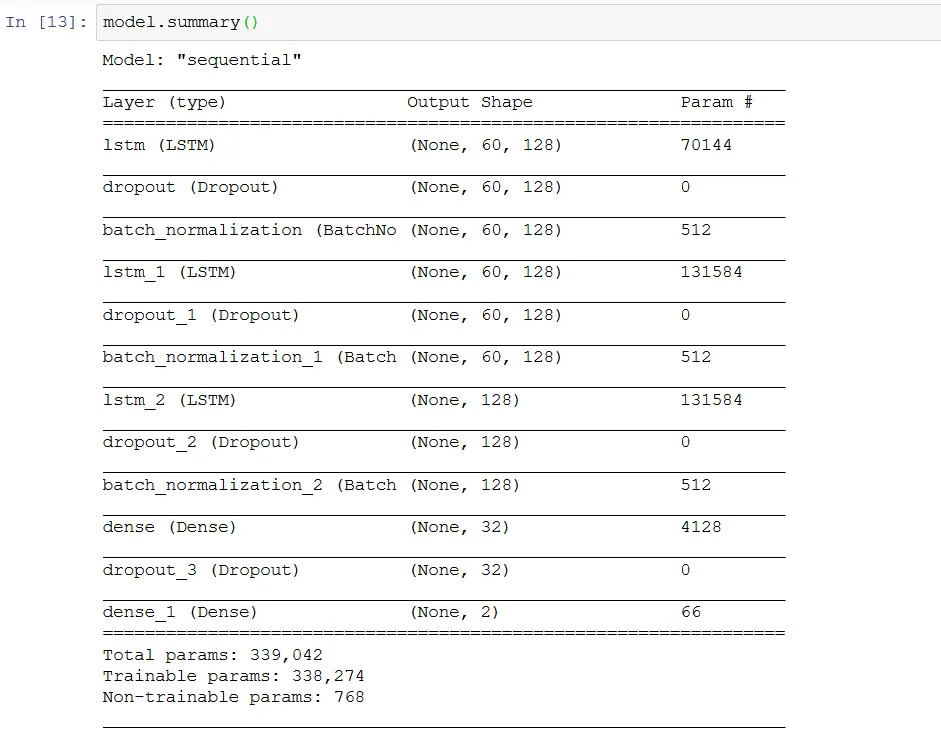
模型如下:
model = Sequential()
model.add(LSTM(128, input_shape=(train_x.shape[1:]),return_sequences=True))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(0.1))
model.add(BatchNormalization())
model.add(LSTM(128))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Dense(32, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(2, activation="softmax"))
opt = tf.keras.optimizers.Adam(lr=0.001, decay=1e-6)
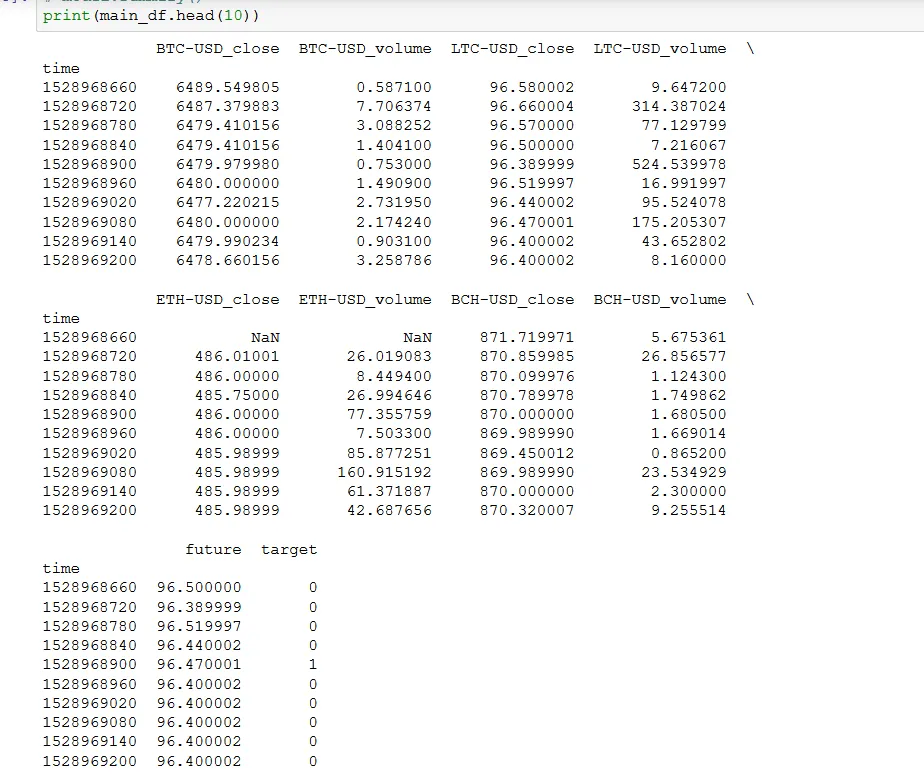
main_df是一个数据框,包括:
我的问题是,我应该如何为模型提供正确的数据输入来进行预测?
编辑:
preprocess函数:
def preprocess_df(df):
#scalling
df = df.drop('future', 1)
for col in df.columns:
if col!= "target":
df[col] = df[col].pct_change() # normalizes the data
df.dropna(inplace=True)
df[col] = preprocessing.scale(df[col].values) #scale the data between 0-1
df.dropna(inplace=True)
sequential_data = []
prev_days = deque(maxlen=SEQ_LEN)
for i in df.values:
prev_days.append([n for n in i[:-1]]) # append each column and not taking a target
if len(prev_days) == SEQ_LEN:
sequential_data.append([np.array(prev_days), i[-1]])
random.shuffle(sequential_data)
# BALANCING THE DATA
buys = []
sells = []
for seq, target in sequential_data:
if target == 0:
sells.append([seq, target])
elif target == 1:
buys.append([seq, target])
random.shuffle(buys)
random.shuffle(sells)
lower = min(len(buys), len(sells))
buys = buys[:lower]
sells = sells[:lower]
sequential_data = buys + sells
random.shuffle(sequential_data)
X = []
y = []
for seq, target in sequential_data:
X.append(seq)
y.append(target)
return np.array(X), y