这里有一张来自维基百科的非常有见地的图表,它说明了如何对一个点进行双线性插值:
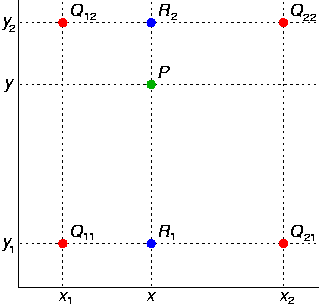
来源:Wikipedia
正如您所看到的,四个红色点是已知的。在插值之前,这些点是已知的,P是我们要插值的点。因此,我们要分两步(如您在帖子中所示)来处理。首先,对于x坐标(水平方向),我们必须针对红色点的上下两行分别计算出每行的插值点,这将得到两个蓝色的点R1和R2。接着,对于y坐标(垂直方向),我们使用两个蓝色点进行插值,得到最终的P点。
当您调整图像大小时,尽管我们无法从视觉上看到我接下来要说的内容,但请想象一下,这个图像实际上是一个三维信号f。矩阵中的每个点实际上都是一个三维坐标,其中列位置是x值,行位置是y值,而z值则是矩阵本身的量/灰度值。因此,执行z = f(x,y)将得到矩阵中位置为(x,y)的值。在我们的情况下,因为您处理的是图像,每个(x,y)的值都是从1开始的整数,最高可达到矩阵有多少行/列,具体取决于您所查看的维度。
因此,给定您要进行插值的坐标(x,y),并给定上述图像中的红色坐标,我们称之为x1,y1,x2,y2按照图表的约定,并参考了如何访问图像: x1 = 1,x2 = 2,y1 = 2,y2 = 1。蓝色坐标R1和R2使用同一行进行一维插值计算来获得:
R1 = f(x1,y1) + (x - x1)/(x2 - x1)*(f(x2,y1) - f(x1,y1))
R2 = f(x1,y2) + (x - x1)/(x2 - x1)*(f(x2,y2) - f(x1,y2))
重要提示:在计算输出混合比例时,
(x-x1)/(x2-x1)是两个值在
f(x1,y1)和
f(x2,y1)(用于
R1)或
f(x1,y2)和
f(x2,y2)(用于
R2)处的混合程度/比例。具体而言,
x1是起点,
(x2-x1)是
x值的差异。当将
x1替换为
x时,可以验证该权重为0,当将
x2替换为
x时,该权重为1。这个权重在
[0,1]之间波动,这是必须的计算工作。
需要注意的是,图像的原点位于左上角,并且(1,1)在左上角。找到R1和R2后,可以通过逐行插值来找到P:
P = R2 + (y - y2)/(y2 - y1)*(R1 - R2)
再次说明,
(y-y2)/(y2-y1)表示
R1和
R2对最终输出
P的贡献比例/混合。因此,你正确地计算了
f5,因为你使用了四个已知点:左上角是100,右上角是50,左下角是70,右下角是20。具体来说,如果您想计算
f5,这意味着
(x,y)=(1.5,1.5),因为我们在100和50之间取中间值,由于您将图像缩放了两倍。如果您将这些值代入上述计算中,您将得到60的值,正如您所预期的那样。两个计算的权重也将导致
0.5的结果,这就是您在计算中得到的,并且这就是我们所期望的。
如果您计算
f1,则相应于
(x,y)=(1.5,1),如果您将其代入上述方程中,您将看到
(y-y2)/(y2-y1)给出0或权重为0,因此计算的仅是
R2,相当于沿顶部行的线性插值。类似地,如果我们计算
f7,这意味着我们想要在
(x,y)=(1.5,2)处进行插值。在这种情况下,您将看到
(y-y2)/(y2-y1)为1或权重为1,因此
P=R2+(R1-R2),简化为
R1,并且是沿底部行的线性插值。
现在有
f3和
f5的情况。它们都对应于
(x,y)=(1,1.5)和
(x,y)=(2,1.5)。将这些值代替
R1和
R2以及
P的两种情况分别为:
R1 = f(1,2) + (1 - 1)/(2 - 1)*(f(2,2) - f(1,2)) = f(1,2)
R2 = f(1,1) + (1 - 1)/(2 - 1)*(f(1,2) - f(1,1)) = f(1,1)
P = R1 + (1.5 - 1)*(R1 - R2) = f(1,2) + 0.5*(f(1,2) - f(1,1))
P = 70 + 0.5*(100 - 70) = 85
f5
R1 = f(1,2) + (2 - 1)/(2 - 1)*(f(2,2) - f(1,2)) = f(2,2)
R2 = f(1,1) + (2 - 1)/(2 - 1)*(f(1,2) - f(1,1)) = f(1,2)
P = R1 + (1.5 - 1)*(R1 - R2) = f(2,2) + 0.5*(f(2,2) - f(1,2))
P = 20 + 0.5*(50 - 20) = 35
那么,这告诉我们什么?这意味着您仅在y方向上进行插值。当我们查看P时,这是显而易见的。对于每个f3和f5的计算进行更彻底的检查,您会发现我们仅考虑沿垂直方向的值。
因此,如果您想得到明确的答案,请通过沿同一行仅在x/列方向上进行插值来找到f1和f7。通过沿同一列的y /行方向进行插值来查找f3和f5。f4使用f1和f7的混合来计算最终值,正如您已经看到的。
回答您的最后一个问题,基于个人喜好填写f2、f6和f8。这些值被认为是超出边界范围的,其中x和y的值都为2.5,超出了(x,y)的[1,2]网格范围。在MATLAB中,默认实现是将定义边界之外的任何值填充为非数字(NaN),但有时人们使用线性插值进行外推,复制边框值或执行一些精心设计的填充(例如对称或循环填充)。这取决于您所处的情况,但填写f2、f6和f8没有正确和确定的答案-它完全取决于您的应用程序以及对您来说最有意义的方法。
作为奖励,我们可以在MATLAB中验证我的计算是否正确。首先,在[1,2]范围内定义一个(x,y)点的网格,然后调整图像大小使其扩大两倍,其中我们指定每个点的分辨率为0.5而不是1。我将称您定义的矩阵为A:
A = [100 50; 70 20];
[X,Y] = meshgrid(1:2,1:2);
[X2,Y2] = meshgrid(1:0.5:2.5,1:0.5:2.5)
B = interp2(X,Y,A,X2,Y2,'linear');
原始的(x,y)点网格如下:
>> X
X =
1 2
1 2
>> Y
Y =
1 1
2 2
扩展网格将矩阵的大小扩大了一倍,外观如下:
>> X2
X2 =
1.0000 1.5000 2.0000 2.5000
1.0000 1.5000 2.0000 2.5000
1.0000 1.5000 2.0000 2.5000
1.0000 1.5000 2.0000 2.5000
>> Y2
Y2 =
1.0000 1.0000 1.0000 1.0000
1.5000 1.5000 1.5000 1.5000
2.0000 2.0000 2.0000 2.0000
2.5000 2.5000 2.5000 2.5000
B是使用X和Y作为原始网格点,X2和Y2是我们要进行插值的点时得到的输出。
我们得到:
>> B
B =
100 75 50 NaN
85 60 35 NaN
70 45 20 NaN
NaN NaN NaN NaN