简短回答:可能。
详细回答:
如果deleted_at中有非常少的不同值,MySQL将不会使用INDEX(deleted_at)。
如果deleted_at中有许多不同的非空日期,则MySQL将使用INDEX(deleted_at)。
到目前为止,大部分讨论都没有考虑到这个单列索引的基数。
注意:这与类似于is_deleted的2个值标志不同。在这种情况下,对于单列索引是无用的。
更多讨论(从MySQL的角度)
https://laravel.com/docs/5.2/eloquent#soft-deleting中提到
现在,当您在模型上调用delete方法时,deleted_at列将设置为当前日期和时间。并且,在查询使用软删除的模型时,软删除模型将自动从所有查询结果中排除。
据此,我假设这是表定义中发生的事情:
deleted_at DATETIME NULL
而且这个值被初始化(显式或隐式)为NULL。
情况1:有很多新的行,但没有“删除”:所有deleted_at的值都是NULL。在这种情况下,优化器会避开INDEX(deleted_at)因为它没有帮助。实际上,使用索引会浪费更多时间去遍历整个索引和数据。忽略索引并假定所有行都是可能被SELECTed的候选行,这样更便宜。
情况2:少数行(其中之一)已被删除:现在deleted_at有多个值。尽管Laravel只关心IS NULL与IS NOT NULL,但MySQL将其视为一个多值列。但是,由于测试是用于IS NULL,而大多数行仍然是NULL,因此优化器的反应与情况1相同。
情况3:被软删除的行比仍处于活动状态的行要多得多:现在索引突然变得有用了,因为表中只有小部分IS NULL。
情况2和情况3之间没有确切的分界线。20%是一个方便的经验法则。
现在,从执行的角度来看。
INDEX(deleted_at)用于deleted_at IS NULL:
- 钻取索引BTree以获取第一个具有
NULL的行。
- 扫描直到
IS NULL失败为止。
- 对于每个匹配的行,到达数据B树以获取该行。
INDEX(deleted_at)未使用:
- 扫描数据BTree(或使用其他索引)
- 对于每个data行,请检查
deleted_at IS NULL,否则过滤掉该行。
复合索引:
拥有以deleted_at开头的“复合”(多列)索引可能非常有益。例如:
INDEX(deleted_at, foo)
WHERE deleted_at IS NULL
AND foo BETWEEN 111 AND 222
无论表中有多少百分比的内容被删除,都很可能有效地使用索引。
- 钻取到第一行具有
NULL和foo >= 111的索引BTree。
- 扫描直到
IS NULL或foo <= 222失败。
- 对于每个匹配的行,进入数据 BTree 获取该行。
请注意,在INDEX中,NULL非常类似于任何其他单个值。 (并且NULLs存储在其他值之前。)
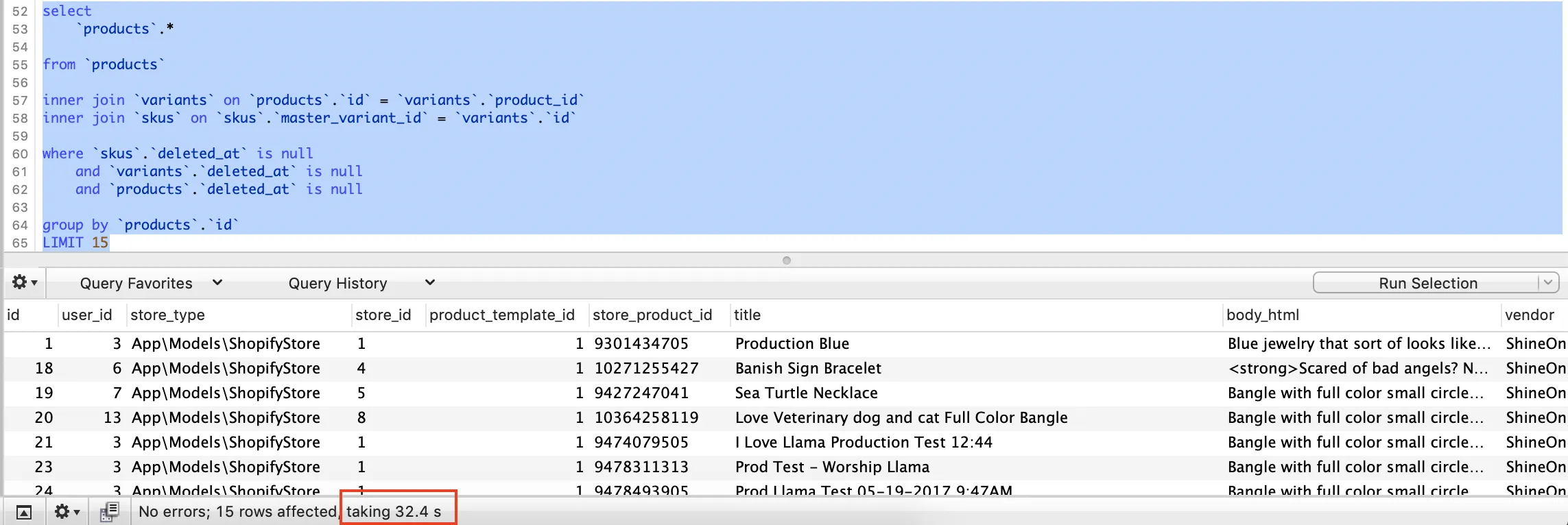



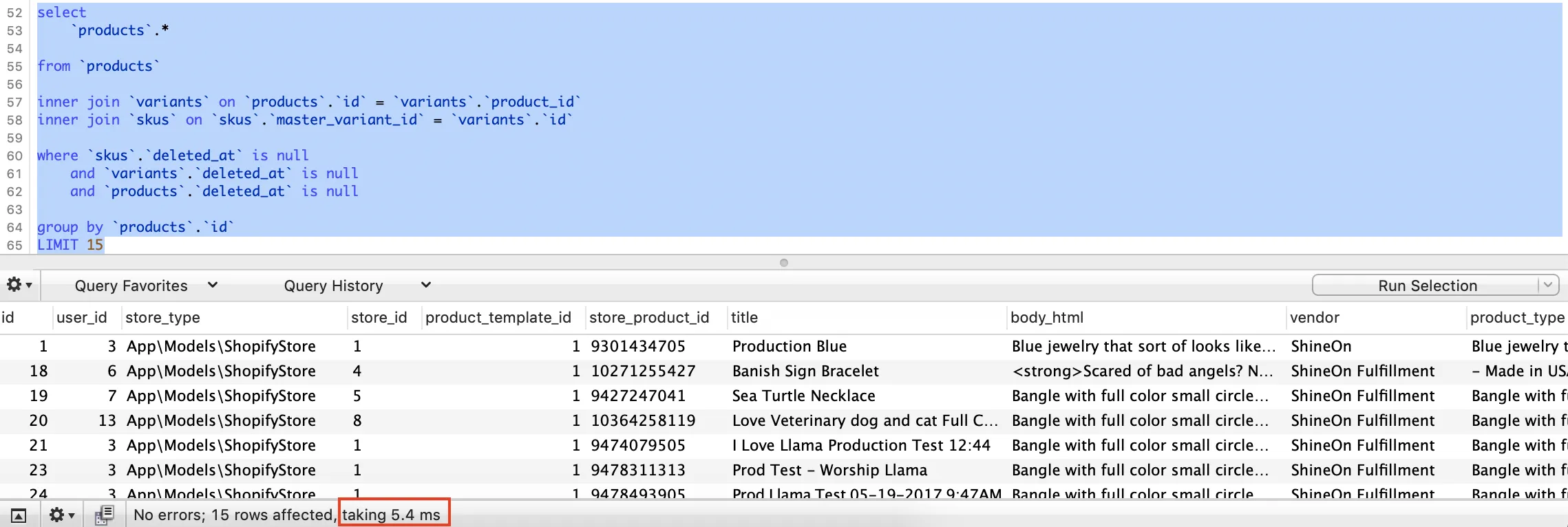
where子句都需要建立索引。如果您愿意,可以将您的评论发布为答案。 - rap-2-h