我在pandas中有一个数据框,我想将其写入CSV文件。
我正在使用以下方法:
我正在使用以下方法:
df.to_csv('out.csv')
并且出现了以下错误:
UnicodeEncodeError: 'ascii' codec can't encode character u'\u03b1' in position 20: ordinal not in range(128)
- 有没有简单的方法可以解决这个问题?(例如,我的数据框中有 Unicode 字符)?
- 是否有一种方法可以使用“to-tab”方法将数据写入制表符分隔文件而不是 CSV(我认为并不存在该方法)?
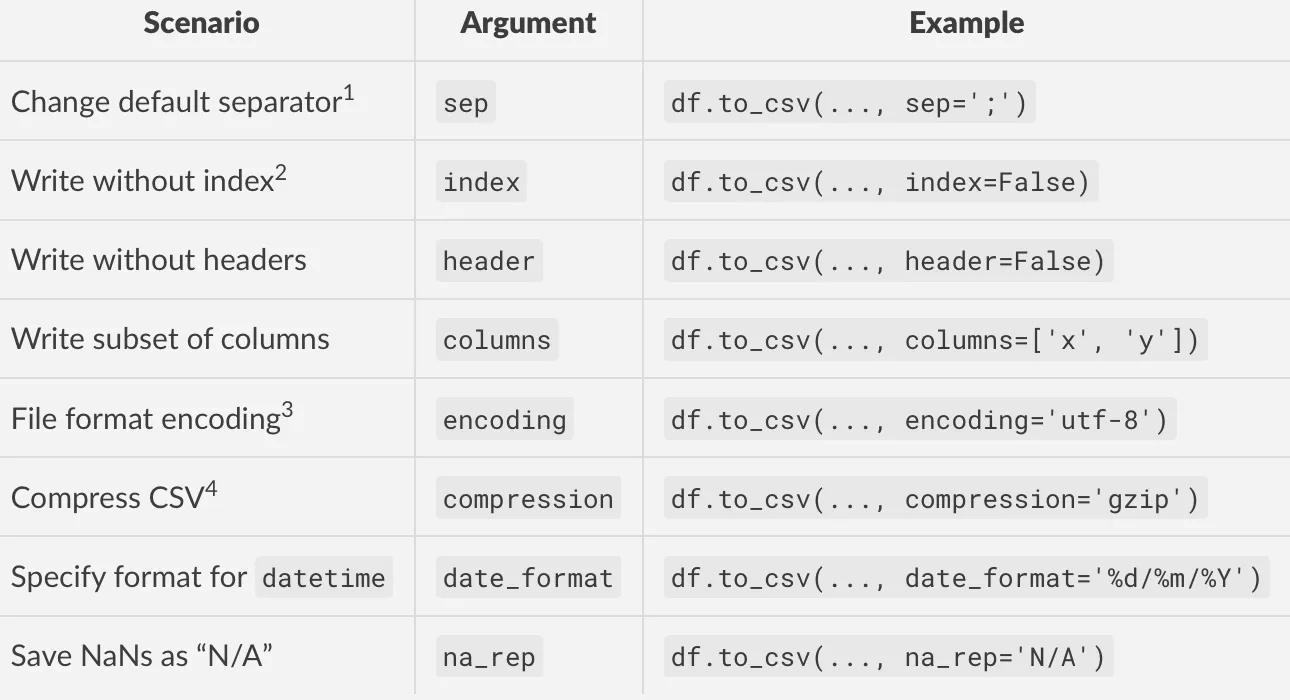
index=False以去除索引。 - Medhatto_csv写入制表符分隔文件的特定原因吗? - DryLabRebel