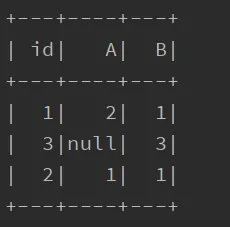
我正在处理一个类似如下的pyspark dataframe:
我想要将分类列进行展开,然后计算它们的出现次数。所以我想要的结果如下所示:
我尝试在互联网上找到可以帮助我的东西,但我找不到能给我这个特定结果的任何信息。
| id | category |
|---|---|
| 1 | A |
| 1 | A |
| 1 | B |
| 2 | B |
| 2 | A |
| 3 | B |
| 3 | B |
| 3 | B |
| id | A | B |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 1 | 1 |
| 3 | Null | 3 |