我有一个如下的pandas DataFrame:
id quantity cost type
2016-06-18 1700057817 2 2383 A
2016-06-18 1700057817 1 744 B
2016-06-19 1700057817 5 934 A
在这里,日期是
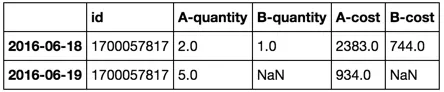
index。我需要将表格透视如下: id A-quantity A-cost B-quantity B-cost
2016-06-18 1700057817 2 2383 1 744
2016-06-19 1700057817 5 934 NA NA
目前我尝试过的方法:
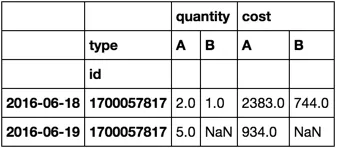
我尝试了很多次使用 pivot。这是我最接近成功的尝试:
>>> df.pivot(index='id', columns='type')
quantity cost
type A B A B
id
1700057817 2 1 2383 744
以下是问题:
date索引已经消失- 我需要每个
date-id组合的一行
我也阅读了几篇关于SO和其他地方的文章,包括这篇文章。
pivot_table(index, columns, aggfunc = lambda x: x.values[0])将获取字符串。 - jf328