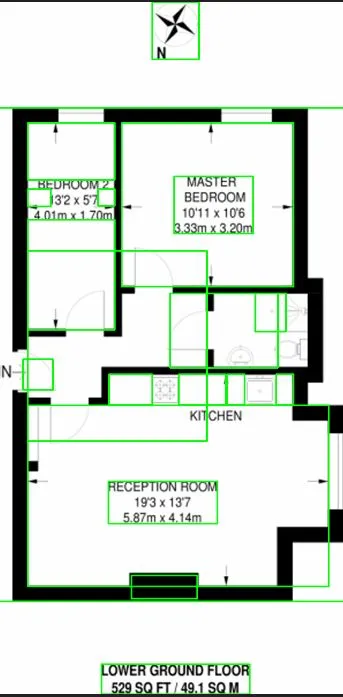
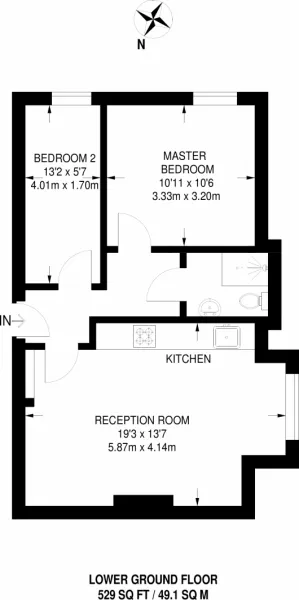
这个答案基于图像相似(如大小、墙壁厚度、字母等)的假设。如果不是这样,这种方法就不好用,因为你需要为每个图像更改阈值器。话虽如此,我建议将图像转换为二进制并搜索轮廓。之后,您可以添加诸如高度、重量等条件来过滤墙壁。然后,您可以在掩模上绘制轮廓,然后膨胀图像。这将将彼此靠近的字母合并成一个轮廓。然后,您可以为所有轮廓创建边界框,这是您的ROI。然后,您可以在该区域使用任何OCR。希望能对您有所帮助。干杯!
import cv2
import numpy as np
img = cv2.imread('floor.png')
mask = np.zeros(img.shape, dtype=np.uint8)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, threshold = cv2.threshold(gray,150,255,cv2.THRESH_BINARY_INV)
_, contours, hierarchy = cv2.findContours(threshold,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
ROI = []
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
if h < 20:
cv2.drawContours(mask, [cnt], 0, (255,255,255), 1)
kernel = np.ones((7,7),np.uint8)
dilation = cv2.dilate(mask,kernel,iterations = 1)
gray_d = cv2.cvtColor(dilation, cv2.COLOR_BGR2GRAY)
_, threshold_d = cv2.threshold(gray_d,150,255,cv2.THRESH_BINARY)
_, contours_d, hierarchy = cv2.findContours(threshold_d,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
for cnt in contours_d:
x,y,w,h = cv2.boundingRect(cnt)
if w > 35:
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
roi_c = img[y:y+h, x:x+w]
ROI.append(roi_c)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
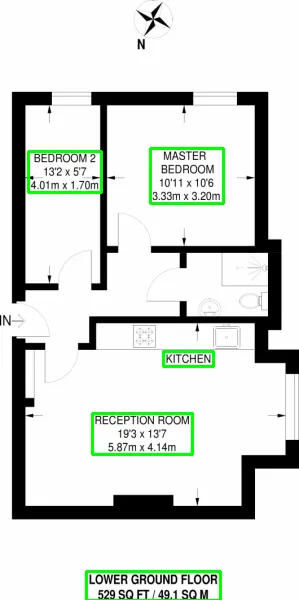
结果:
(翻译者说明:此段内容为HTML代码,无需翻译,只需要保留原有格式即可)