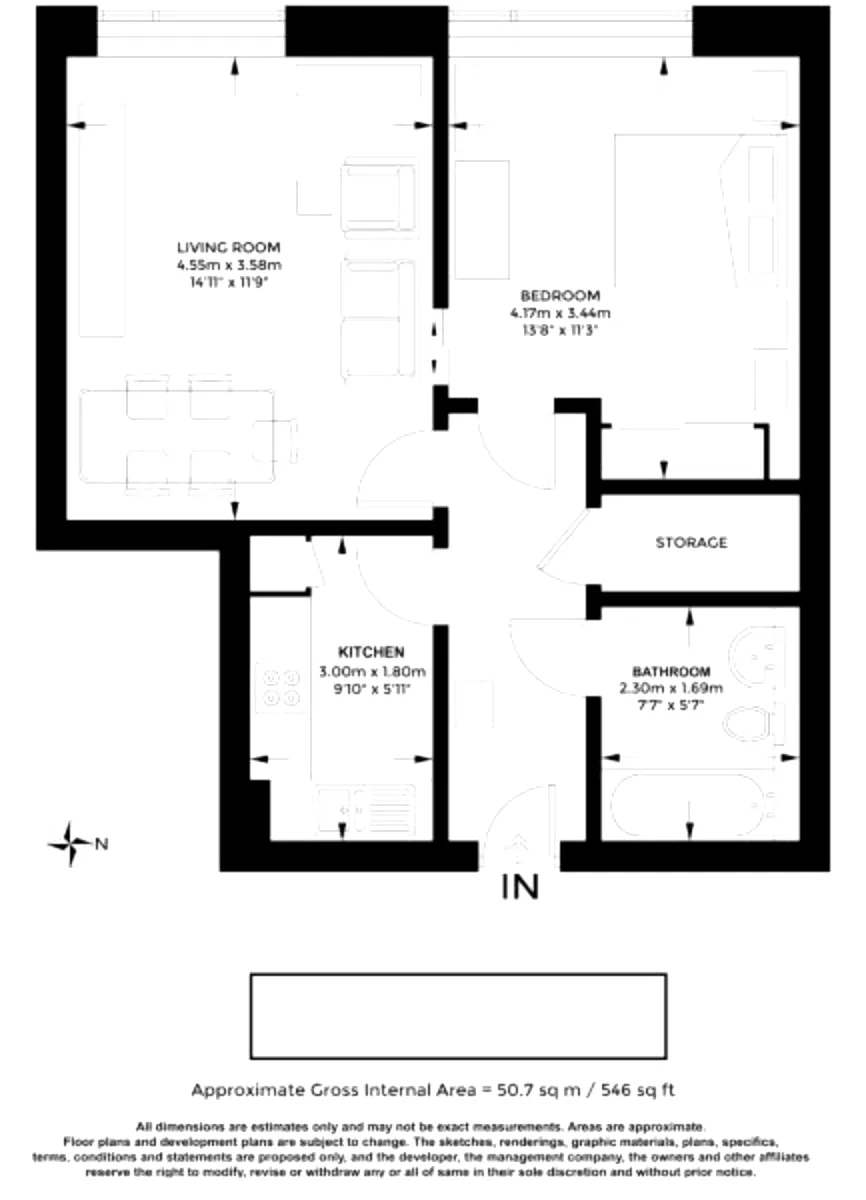
我正在尝试编写一个函数,它可以使用OCR从房屋平面图的jpg图像中提取书写在图片上的平方英尺数值。
import requests
from PIL import Image
import pytesseract
import pandas as pd
import numpy as np
import cv2
import io
def floorplan_ocr(url):
""" a row-wise function to use pytesseract to scrape the word data from the floorplan
images, requires tesseract
to be installed https://github.com/tesseract-ocr/tesseract/wiki"""
if pd.isna(url):
return np.nan
res = ''
response = requests.get(url, stream=True)
if response.status_code == 200:
img = response.raw
img = np.asarray(bytearray(img.read()), dtype="uint8")
img = cv2.imdecode(img, cv2.CV_8UC1)
img = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv2.THRESH_BINARY,11,2)
#img = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 2)
res = pytesseract.image_to_string(img, lang='eng', config='--remove-background')
del response
del img
else:
return np.nan
#print(res)
return res
但是我没有取得太多成功,只有大约四分之一的图像实际上输出包含平方英尺的文本。
例如目前floorplan_ocr(https://i.imgur.com/9qwozIb.jpg) 输出 'K\'Fréfiéfimmimmuuéé\n2|; apprnxx 135 max\nGArhaPpmxd1m max\n\n \n\n \n\n \n\n \n\n \n\n \n\n \n\n总APPaux中午区域523平方英尺,U.S.50, M )\nav .Wzms他 "a! m... mi unwary mmnmrmm mma y“ mum“;\n‘ wmduw: reams m wuhrmmm mm“ .m nanspmmmmy 3 mm :51\nmm" m mmm m; wan wmumw- mm my and mm mm as m by any\nwfmw PM” rmwm mm m .pwmwm m. mum mud ms nu mum.\n(.5 n: ma undammmw an we Ewen\nM vagw‘m Mewpkeem'(而且需要很长时间才能完成)
floorplan_ocr(https://i.imgur.com/sjxMpVp.jpg)则输出' '。
我觉得我面临的一些问题是:
- 文本可能是灰度的
- 图像低 DPI(似乎有一些争议,是否实际上很重要或者是否是总分辨率)
- 文本格式不一致
我被卡住了,而且我正在努力改善我的结果。 我想要提取的只是'XXX平方英尺'(以及可能写法的所有方式)
有更好的方法吗?
非常感谢。