我有一个pandas数据框,其中一列是字典类型。以下是示例数据框:
import pandas as pd
df = pd.DataFrame({'a': [1,2,3],
'b': [4,5,6],
'version': [{'major': 7, 'minor':1},
{'major':8, 'minor': 5},
{'major':7, 'minor':2}] })
df:
a b version
0 1 4 {'minor': 1, 'major': 7}
1 2 5 {'minor': 5, 'major': 8}
2 3 6 {'minor': 2, 'major': 7}
我正在寻找一种方法,通过字典中的一个键来对数据框进行分组; 在这种情况下,将 df 数据框按 version 标签中的 major 键分组。
我尝试了几种不同的方法,从将字典键传递给数据框 groupby 函数 `df.groupby(['version']['major'])`,但这并不起作用,因为 major 不是数据框标签的一部分,到将 version 分配给数据框索引,但目前仍然没有解决。我还尝试将字典展开为数据框本身的附加列,但这似乎有自己的问题。
有什么想法吗?
P.S. 抱歉格式不好,这是我的第一个stackoverflow问题。
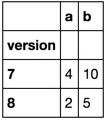
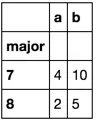
apply函数可以作为索引选择器来使用数据框。谢谢,@piRSquared! - RexIncognito