我有一个整数数组:
[int1, int2, ..., intn]
我想要计算这些整数的二进制表示中有多少个非零位。
例如:
bin(123) -> 0b1111011, there are 6 non-zero bits
当然,我可以循环整数列表,并使用bin()和count('1')函数,但我正在寻找矢量化的方法来完成。
我有一个整数数组:
[int1, int2, ..., intn]
我想要计算这些整数的二进制表示中有多少个非零位。
例如:
bin(123) -> 0b1111011, there are 6 non-zero bits
当然,我可以循环整数列表,并使用bin()和count('1')函数,但我正在寻找矢量化的方法来完成。
由于numpy与python不同,具有有限的整数大小,因此您可以采用Óscar López提出的位操作解决方案来适应Fast way of counting non-zero bits in positive integer(最初来自here)以获得便携式、快速的解决方案:
def bit_count(arr):
# Make the values type-agnostic (as long as it's integers)
t = arr.dtype.type
mask = t(-1)
s55 = t(0x5555555555555555 & mask) # Add more digits for 128bit support
s33 = t(0x3333333333333333 & mask)
s0F = t(0x0F0F0F0F0F0F0F0F & mask)
s01 = t(0x0101010101010101 & mask)
arr = arr - ((arr >> 1) & s55)
arr = (arr & s33) + ((arr >> 2) & s33)
arr = (arr + (arr >> 4)) & s0F
return (arr * s01) >> (8 * (arr.itemsize - 1))
该函数的第一部分将数量0x5555...、0x3333...等截断为arr实际包含的整数类型。余下的部分只是进行一系列位操作。
对于100000个元素的数组,该函数比Ehsan的方法快约4.5倍,比Valdi Bo的方法快约60倍:
a = np.random.randint(0, 0xFFFFFFFF, size=100000, dtype=np.uint32)
%timeit bit_count(a).sum()
# 846 µs ± 16.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit m1(a)
# 3.81 ms ± 24 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit m2(a)
# 49.8 ms ± 97.5 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
m1和m2是从@Ehsan的答案中直接获取的。
_mm512_popcnt_epi64)。虽然它在numpy中没有实现,但最终应该会实现(也许另一个库有这样的实用程序?) - Guillaumea,您可以简单地执行以下操作:np.unpackbits(a.view('uint8')).sum()
例子:
a = np.array([123, 44], dtype=np.uint8)
#bin(a) is [0b1111011, 0b101100]
np.unpackbits(a.view('uint8')).sum()
#9
使用benchit进行比较:
#@Ehsan's solution
def m1(a):
return np.unpackbits(a.view('uint8')).sum()
#@Valdi_Bo's solution
def m2(a):
return sum([ bin(n).count('1') for n in a ])
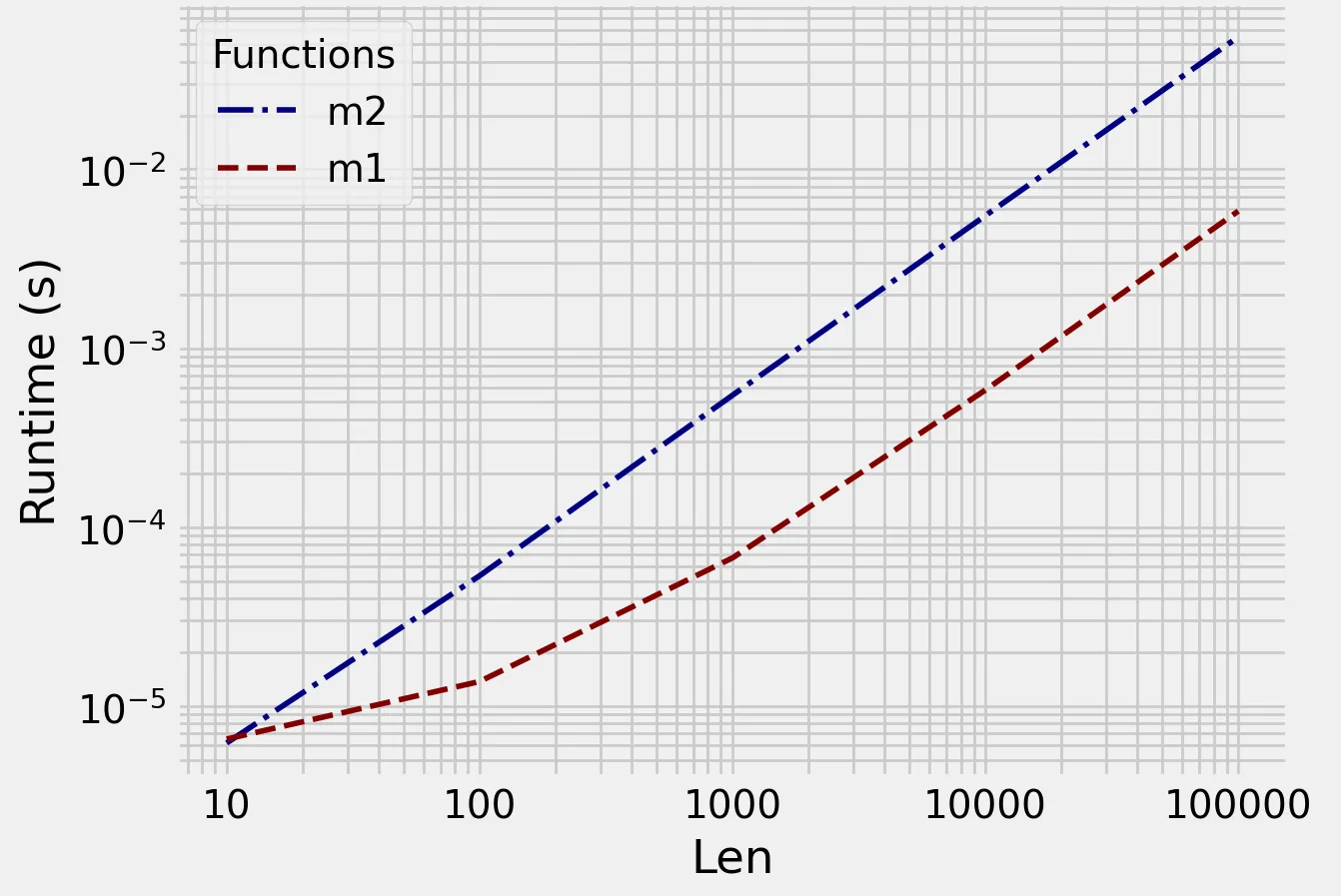
in_ = [np.random.randint(100000,size=(n)) for n in [10,100,1000,10000,100000]]
m1明显更快。
import numpy as np
def make_n_bit_lookup( bits = 8 ):
""" Creates a lookup table of bits per byte ( or per 2 bytes for bits = 16).
returns a count function that uses the table generated.
"""
try:
dtype = { 8: np.uint8, 16: np.uint16 }[ bits ]
except KeyError:
raise ValueError( 'Parameter bits must be 8, 16.')
bits_per_byte = np.zeros( 2**bits, dtype = np.uint8 )
i = 1
while i < 2**bits:
bits_per_byte[ i: i*2 ] = bits_per_byte[ : i ] + 1
i += i
# Each power of two adds one bit set to the bit count in the
# corresponding index from zero.
# n bits ct derived from i
# 0 0000 0
# 1 0001 1 = bits[0] + 1 1
# 2 0010 1 = bits[0] + 1 2
# 3 0011 2 = bits[1] + 1 2
# 4 0100 1 = bits[0] + 1 4
# 5 0101 2 = bits[1] + 1 4
# 6 0110 2 = bits[2] + 1 4
# 7 0111 3 = bits[3] + 1 4
# 8 1000 1 = bits[0] + 1 8
# 9 1001 2 = bits[1] + 1 8
# etc...
def count_bits_set( arr ):
""" The function using the lookup table. """
a = arr.view( dtype )
return bits_per_byte[ a ].sum()
return count_bits_set
count_bits_set8 = make_n_bit_lookup( 8 )
count_bits_set16 = make_n_bit_lookup( 16 )
# The two original answers as functions.
def text_count( arr ):
return sum([ bin(n).count('1') for n in arr ])
def unpack_count( arr ):
return np.unpackbits(arr.view('uint8')).sum()
np.random.seed( 1234 )
max64 = 2**64
arr = np.random.randint( max64, size = 100000, dtype = np.uint64 )
count_bits_set8( arr ), count_bits_set16( arr ), text_count( arr ), unpack_count( arr )
# (3199885, 3199885, 3199885, 3199885) - All the same result
%timeit n_bits_set8( arr )
# 3.63 ms ± 17.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit n_bits_set16( arr )
# 1.78 ms ± 15.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit text_count( arr )
# 83.9 ms ± 1.05 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit unpack_count( arr )
# 8.73 ms ± 87.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
看起来 np.unpackbits 运行速度比在源数组的每个元素上计算 bin(n).count('1') 的总和要慢。
通过%timeit测量的执行时间如下:
np.unpackbits(a.view('uint8')).sum(),sum([ bin(n).count('1') for n in a ])(快了3倍以上)。因此,也许您应该坚持原始概念。
a 有多大? - juanpa.arrivillaga