我会尝试编写一个A*算法来解决这个问题。当您扩展一个节点时,每个出边都会有两个子节点;一个是喝咖啡的,另一个是不喝咖啡的。如果您在算法中先运行Dijkstra算法(因此您已经预先计算了最短路径),那么您可以使用Dijkstra的最短路径+喝咖啡的最短时间(如果已经喝了咖啡,则为+0)来通知A*搜索的启发式函数。
当您不仅到达目标节点,而且还喝了咖啡时,A*搜索终止。
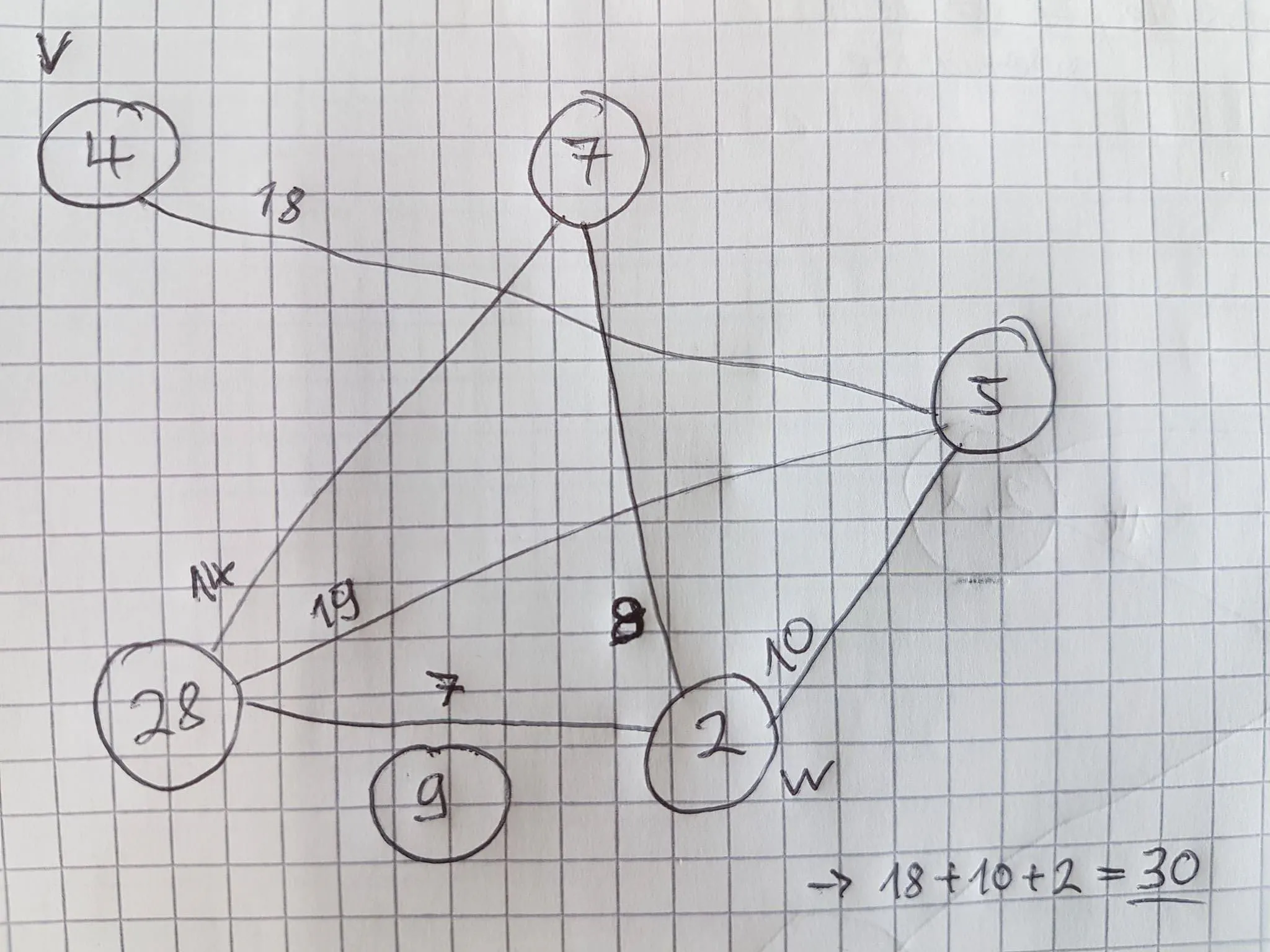
第二种情况的示例搜索:
Want: A --> C
A(10) -- 1 -- B(10) -- 1 -- C(10)
\ /
\ /
2 -------- D(2) ------- 2
Expand A
A*(cost so far: 10, heuristic: 2) total est cost: 12
B (cost so far: 1, heuristic: 1 + 2) total est cost: 3
B*(cost so far: 11, heuristic: 1) total est cost: 12
D (cost so far: 2, heuristic: 2 + 2) total est cost: 6
D*(cost so far: 14, heuristic: 2) total est cost: 16
Expand B
A*(cost so far: 12, heuristic: 2) total est cost: 14
B*(cost so far: 11, heuristic: 1) total est cost: 12
C(cost so far: 2, heuristic: 2) total est cost: 4
C*(cost so far: 12, heuristic: 0) total est cost: 12
Expand C
B*(cost so far: 13, heuristic: 1) total est cost: 14
C*(cost so far: 12, heuristic: 0) total est cost: 12
Expand D
A* (cost so far: 14, heuristic: 2) total est cost: 16
D* (cost so far: 4, heuristic: 2) total est cost: 6
C (cost so far: 4, heuristic: 0 + 2) total est cost: 6
C* (cost so far: 6, heuristic: 0) total est cost: 6
Expand C*
goal reached. total cost: 6
Key:
* = Coffee from parent was drunk
因此,您可以看到这个算法首先试图沿着Dijkstra的最短路径前进(不喝咖啡)。然后当它到达终点时,它会看到一个物理目标状态,但还需要喝咖啡。当它展开物理目标状态以喝咖啡时,它将发现到达的成本是次优的,因此它会从另一个分支继续搜索。
请注意,在上述示例中,A和A*是不同的节点,因此在某种程度上,您可以重新访问父节点(但仅在咖啡饮用状态不同时)。
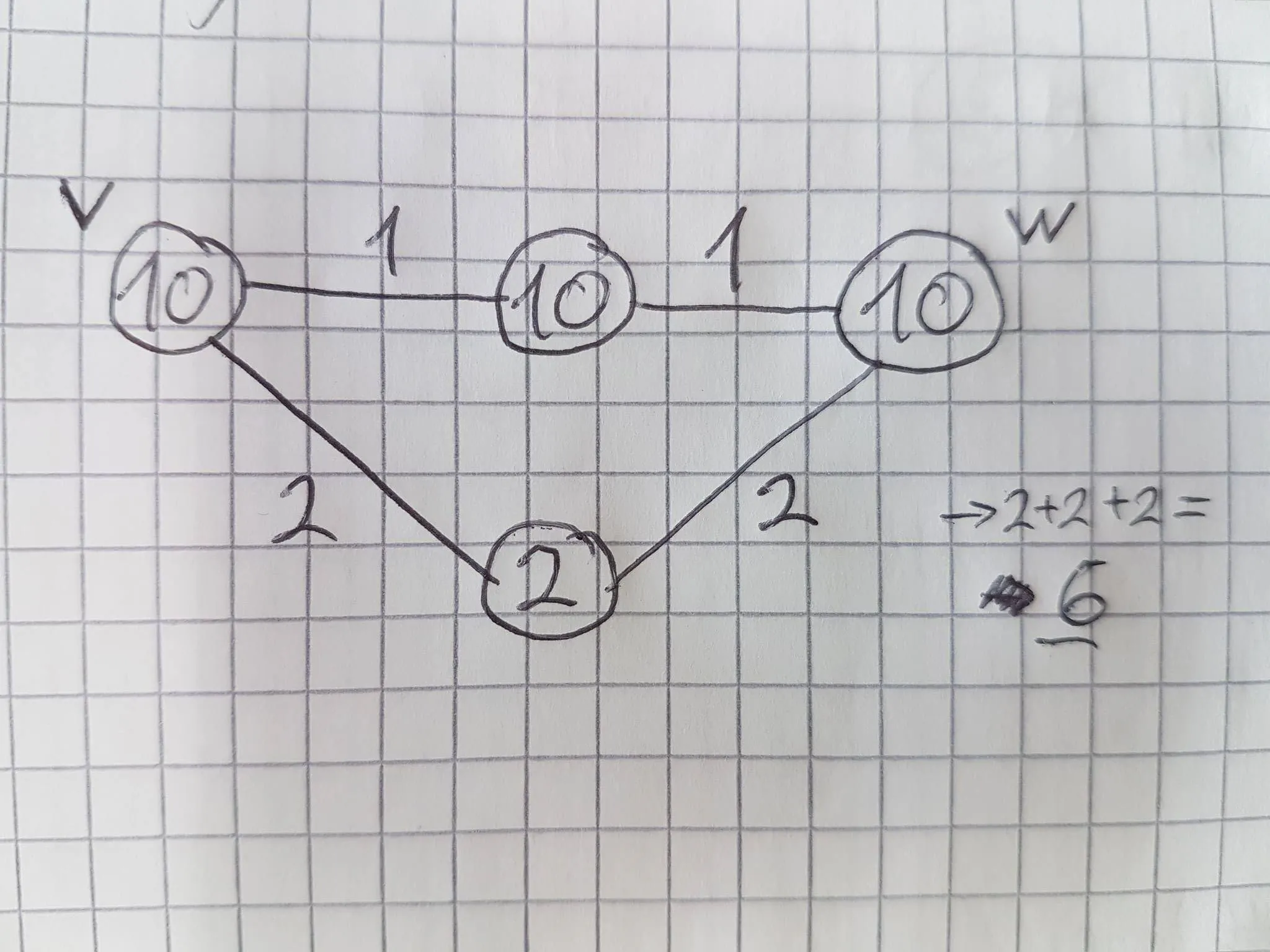
这是为了解决以下类似图形的问题:
Want A
A(20)
\
2
\
C(1)
在从A到C到C*再到A*最后到B*的路径中,这种走法是有意义的。
我还不确定我们是否需要通过喝咖啡的节点来区分“喝掉的咖啡”状态,但我倾向于不需要。