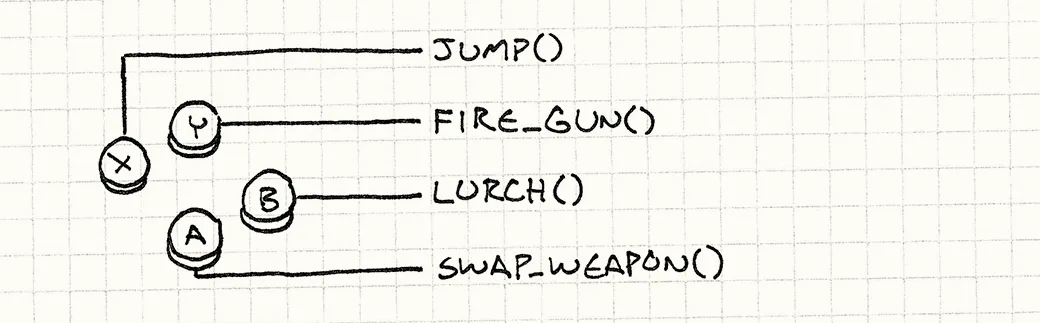
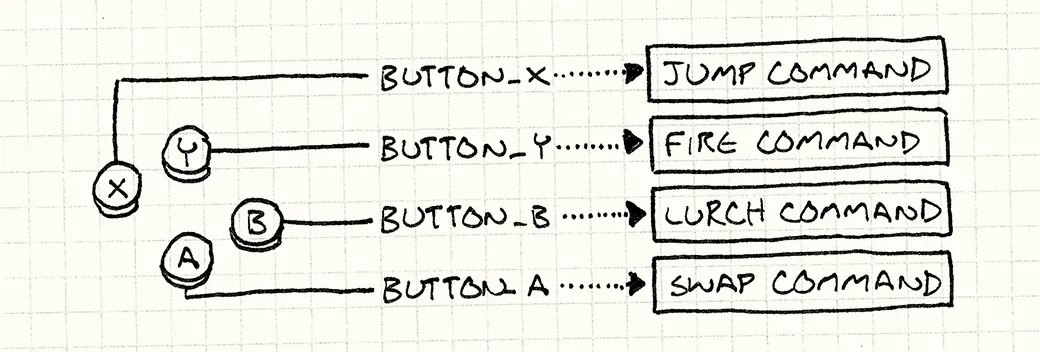
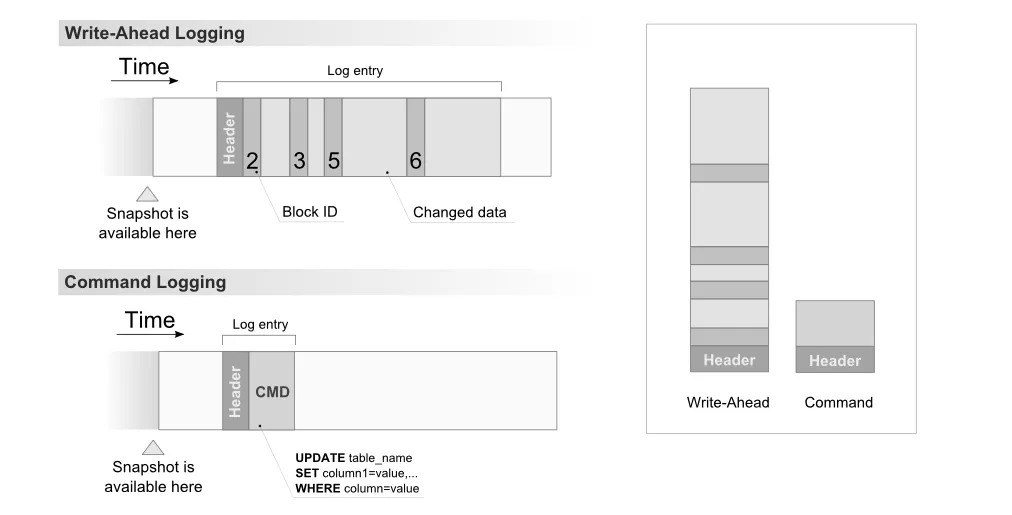
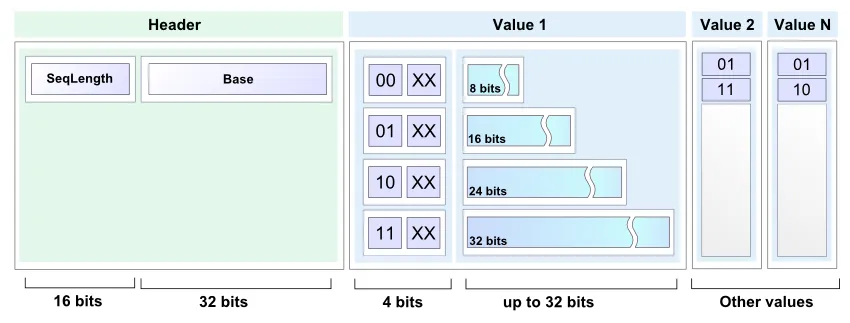
我对探索实时多人客户端服务器游戏开发和相关算法感兴趣。许多著名的多人游戏,例如Quake 3或Half-Life 2使用增量压缩技术来节省带宽。
服务器必须不断向所有客户端发送最新的游戏状态快照。总是发送完整快照将非常昂贵,因此服务器只发送上一个快照与当前快照之间的差异。
...很容易,对吧?嗯,我觉得非常难想的部分是如何实际计算两个游戏状态之间的差异。
游戏状态可以非常复杂,并且具有在堆上分配的实体,通过指针相互引用,可能具有数值,其表示因架构而异,等等。
我认为不太可能每种游戏对象类型都有手写的序列化/反序列化/差异计算函数。
让我们回到基础知识。假设我有两个用位表示的状态,并且我想计算它们之间的差异:
如果这样的事情是可能的,那么避免架构相关问题和手写差异计算函数将变得相对容易。
给定两个类似的字符串 A 和 B,是否可能计算出一个字符串 C,它比 A 和 B 都要小,用于表示 A 和 B 之间的差异,并且可以应用于 A 上,得到 B 的结果?
服务器必须不断向所有客户端发送最新的游戏状态快照。总是发送完整快照将非常昂贵,因此服务器只发送上一个快照与当前快照之间的差异。
...很容易,对吧?嗯,我觉得非常难想的部分是如何实际计算两个游戏状态之间的差异。
游戏状态可以非常复杂,并且具有在堆上分配的实体,通过指针相互引用,可能具有数值,其表示因架构而异,等等。
我认为不太可能每种游戏对象类型都有手写的序列化/反序列化/差异计算函数。
让我们回到基础知识。假设我有两个用位表示的状态,并且我想计算它们之间的差异:
state0: 00001000100 // state at time=0
state1: 10000000101 // state at time=1
-----------
added: 10000000001 // bits that were 0 in state0 and are 1 in state1
removed: 00001000000 // bits that were 1 in state0 and are 1 in state1
太好了,我现在有了添加和删除的差异位集,但是...
...差异的大小仍然与状态的大小完全相同。而且我实际上必须通过网络发送两个差异!
从这些差异位集中构建某种稀疏数据结构是否是一种有效的策略?例如:
// (bit index, added/removed)
// added = 0
// removed 1
(0,0)(4,1)(10,0)
// ^
// bit 0 was added, bit 4 was removed, bit 10 was added
这是一种可行的方法吗?
假设我已经为我的所有游戏对象类型编写了从/到JSON的序列化/反序列化函数。
我能否以某种方式,自动计算两个JSON值之间的差异,以位为单位?
例如:
// state0
{
"hp": 10,
"atk": 5
}
// state1
{
"hp": 4,
"atk": 5
}
// diff
{
"hp": -6
}
// state0 as bits (example, random bits)
010001000110001
// state1 as bits (example, random bits)
000001011110000
// desired diff bits (example, random bits)
100101
如果这样的事情是可能的,那么避免架构相关问题和手写差异计算函数将变得相对容易。
给定两个类似的字符串 A 和 B,是否可能计算出一个字符串 C,它比 A 和 B 都要小,用于表示 A 和 B 之间的差异,并且可以应用于 A 上,得到 B 的结果?