我读到了关于Voltdb的命令日志。命令日志记录事务调用,而不是像预写式日志中每行更改那样。通过仅记录调用,命令日志被保持到最小限度,限制磁盘I/O对性能的影响。
有人可以解释一下为什么Voltdb使用命令日志以及标准的SQL数据库(如Postgres、MySQL、SQLServer、Oracle)为什么使用预写式日志吗?请阐述背后的数据库理论。
有人可以解释一下为什么Voltdb使用命令日志以及标准的SQL数据库(如Postgres、MySQL、SQLServer、Oracle)为什么使用预写式日志吗?请阐述背后的数据库理论。


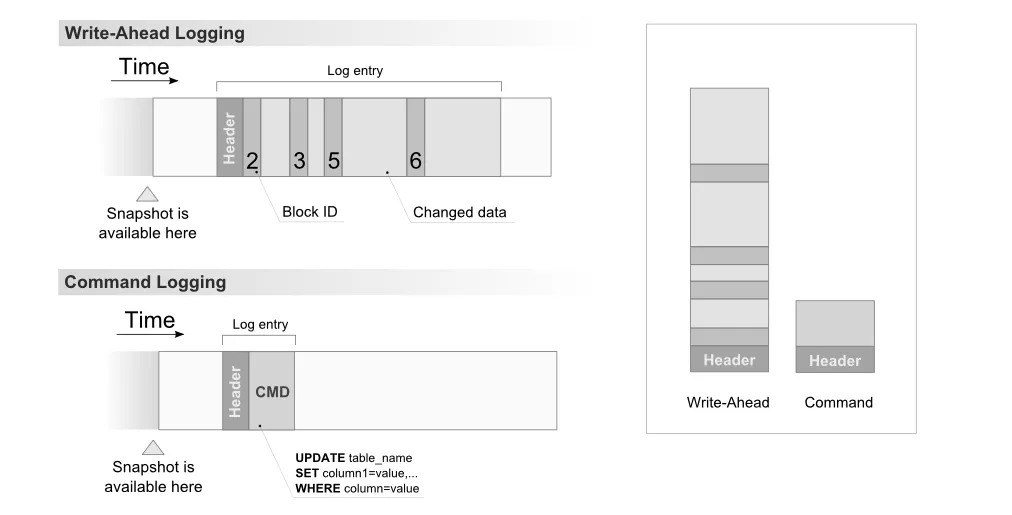

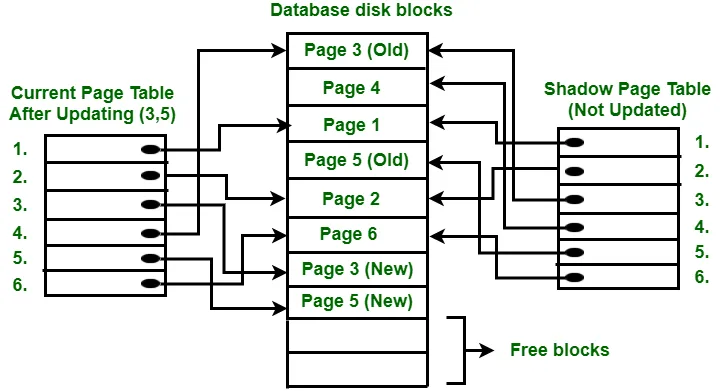
Voltdb如何实现“撤销”功能?如果我执行UPDATE some_table SET some_column=2,那么仅仅知道这个命令是不允许我回滚更改的吗? - Martin Smith