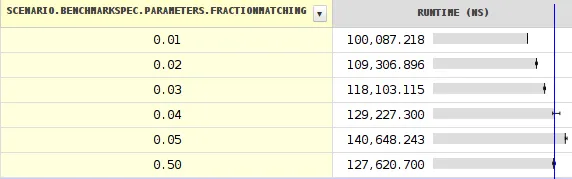
我的基准测试 结果 表明,在分支概率为15%(或85%)时性能最差,而非50%。
有任何解释吗?
它计算给定字符串中BREAKING_WHITESPACE字符的数量。当分支概率达到约0.20时,结果显示了突然的时间下降(性能增加)。
有关下降的详细信息。 改变种子显示更多奇怪的事情发生。请注意,表示最小和最大值的黑线非常短,除了靠近悬崖的地方。
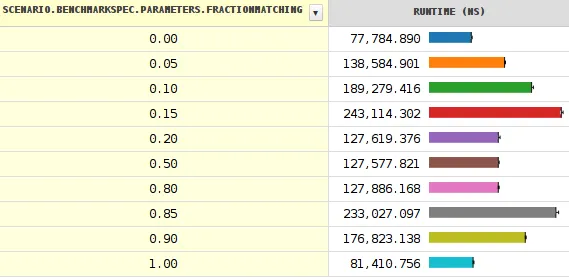
有任何解释吗?
这段代码太长了,但相关部分在这里:
private int diff(char c) {
return TABLE[(145538857 * c) >>> 27] - c;
}
@Benchmark int timeBranching(int reps) {
int result = 0;
while (reps-->0) {
for (final char c : queries) {
if (diff(c) == 0) {
++result;
}
}
}
return result;
}
它计算给定字符串中BREAKING_WHITESPACE字符的数量。当分支概率达到约0.20时,结果显示了突然的时间下降(性能增加)。
有关下降的详细信息。 改变种子显示更多奇怪的事情发生。请注意,表示最小和最大值的黑线非常短,除了靠近悬崖的地方。