为了解释上下文,我编写了这个算法来获取任意字符串的唯一子字符串数。它构建了该字符串的后缀树,计算它所包含的节点并将其作为答案返回。我想要解决的问题需要一个O(n)算法,因此这个问题只涉及此代码的行为,而不是它在处理上的问题有多糟糕。
struct node{
char value = ' ';
vector<node*> children;
~node()
{
for (node* child: children)
{
delete child;
}
}
};
int numberOfUniqueSubstrings(string aString, node*& root)
{
root = new node();
int substrings = 0;
for (int i = 0; i < aString.size(); ++i)
{
string tmp = aString.substr(i, aString.size());
node* currentNode = root;
char indexToNext = 0;
for (int j = 0; j < currentNode->children.size(); ++j)
{
if (currentNode->children[j]->value == tmp[indexToNext])
{
currentNode = currentNode->children[j];
j = -1;
indexToNext++;
}
}
for (int j = indexToNext; j < tmp.size(); ++j)
{
node* theNewNode = new node;
theNewNode->value = tmp[j];
currentNode->children.push_back(theNewNode);
currentNode = theNewNode;
substrings++;
}
}
return substrings;
}
我决定对这个算法进行基准测试,我只是循环遍历一个大字符串,在每次迭代中取一个更大的子字符串,并调用numberOfUniqueSusbstrings来测量结束所需的时间。
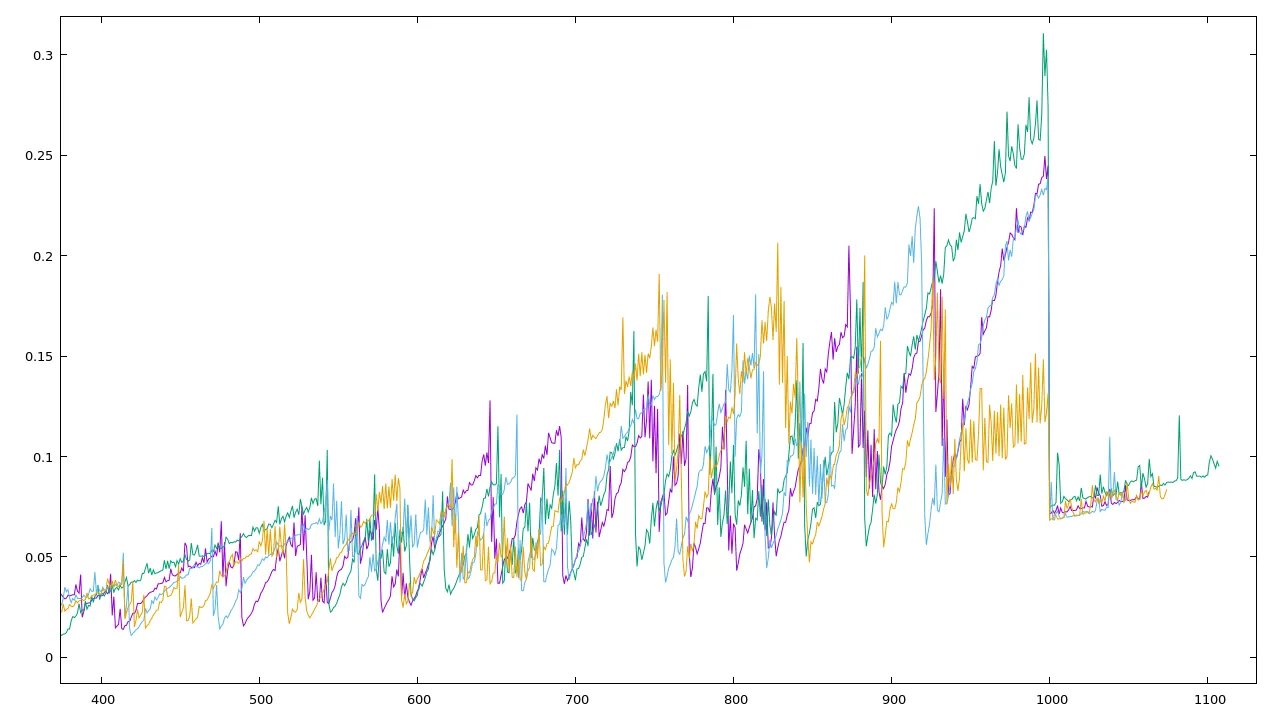
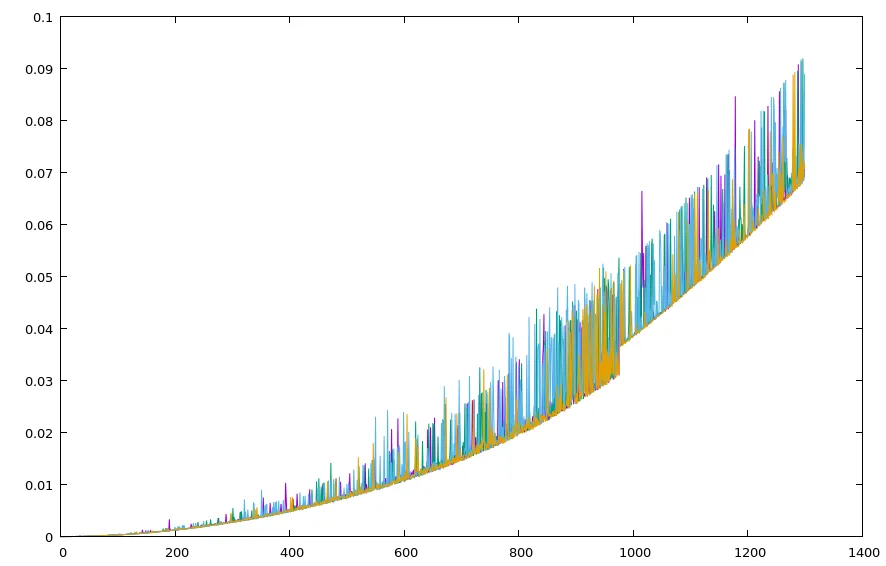
我在Octave中绘制了它,这就是我的结果(x是字符串长度,y是微秒级别的时间)。
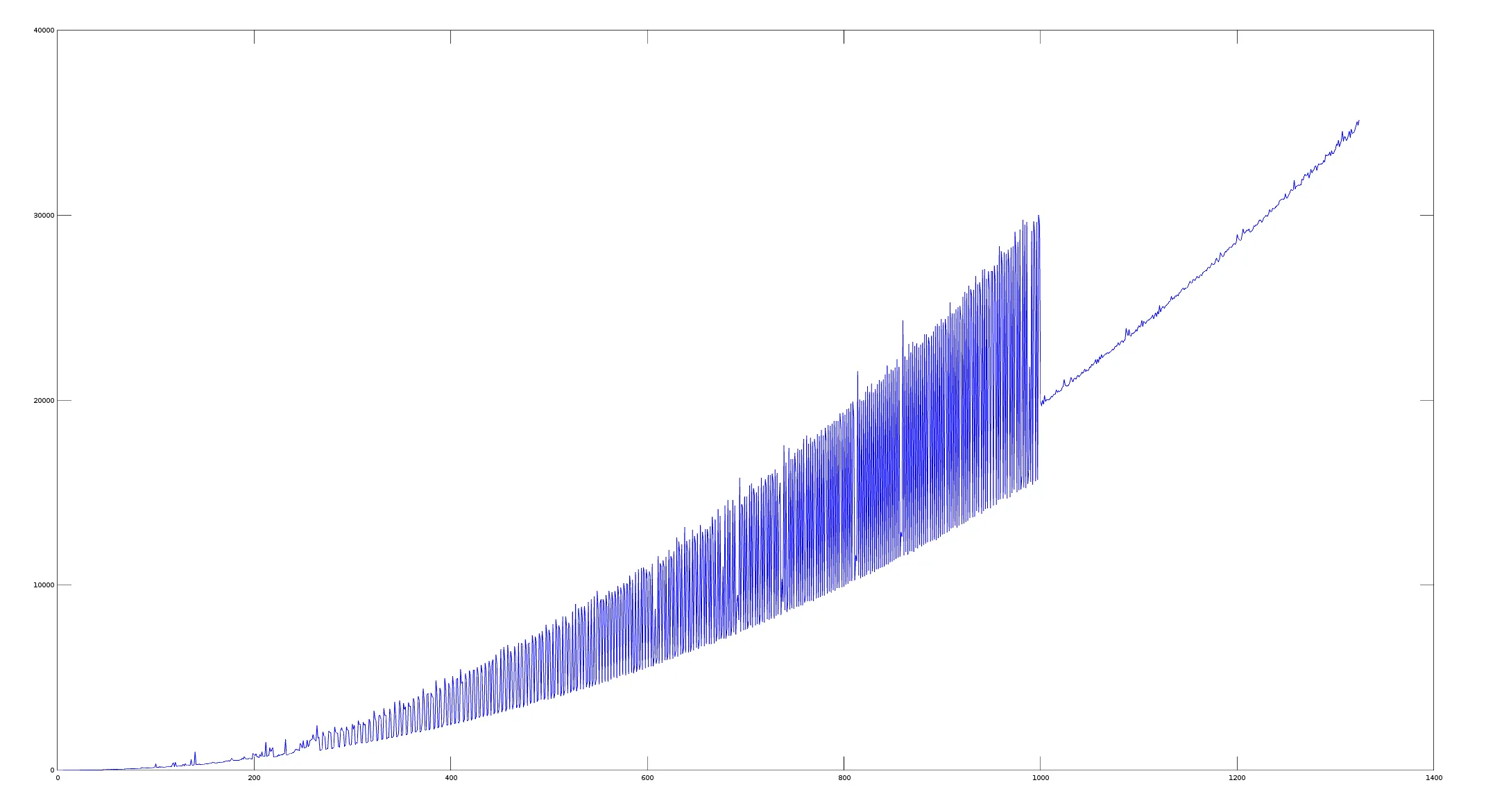
我一开始以为问题在输入字符串上,但它只是我从一本书中获取的字母数字字符串(任何其他文本都会表现得同样奇怪)。
我还尝试了对具有相同参数的函数进行多次调用的平均值,结果几乎相同。
这是使用g++ problem.cpp -std=c++14 -O3编译的,但似乎在-O2和-O0上也是如此。
编辑: 在@interjay的回答之后,我尝试做到这一点,最终函数如下:
int numberOfUniqueSubstrings(string aString, node*& root)
{
root = new node();
int substrings = 0;
for (int i = 0; i < aString.size(); ++i)
{
node* currentNode = root;
char indexToNext = i;
for (int j = 0; j < currentNode->children.size(); ++j)
{
if (currentNode->children[j]->value == aString[indexToNext])
{
currentNode = currentNode->children[j];
j = -1;
indexToNext++;
}
}
for (int j = indexToNext; j < aString.size(); ++j)
{
node* theNewNode = new node;
theNewNode->value = aString[j];
currentNode->children.push_back(theNewNode);
currentNode = theNewNode;
substrings++;
}
}
return substrings;
}
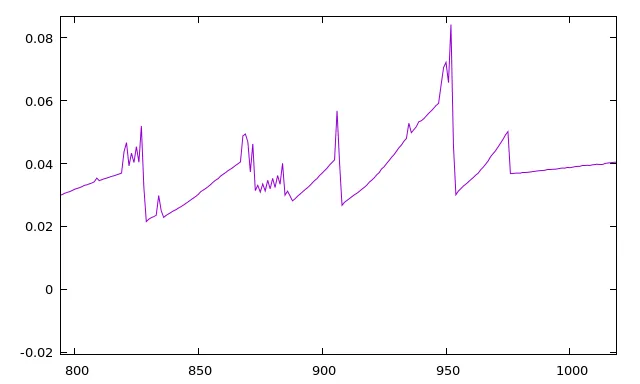
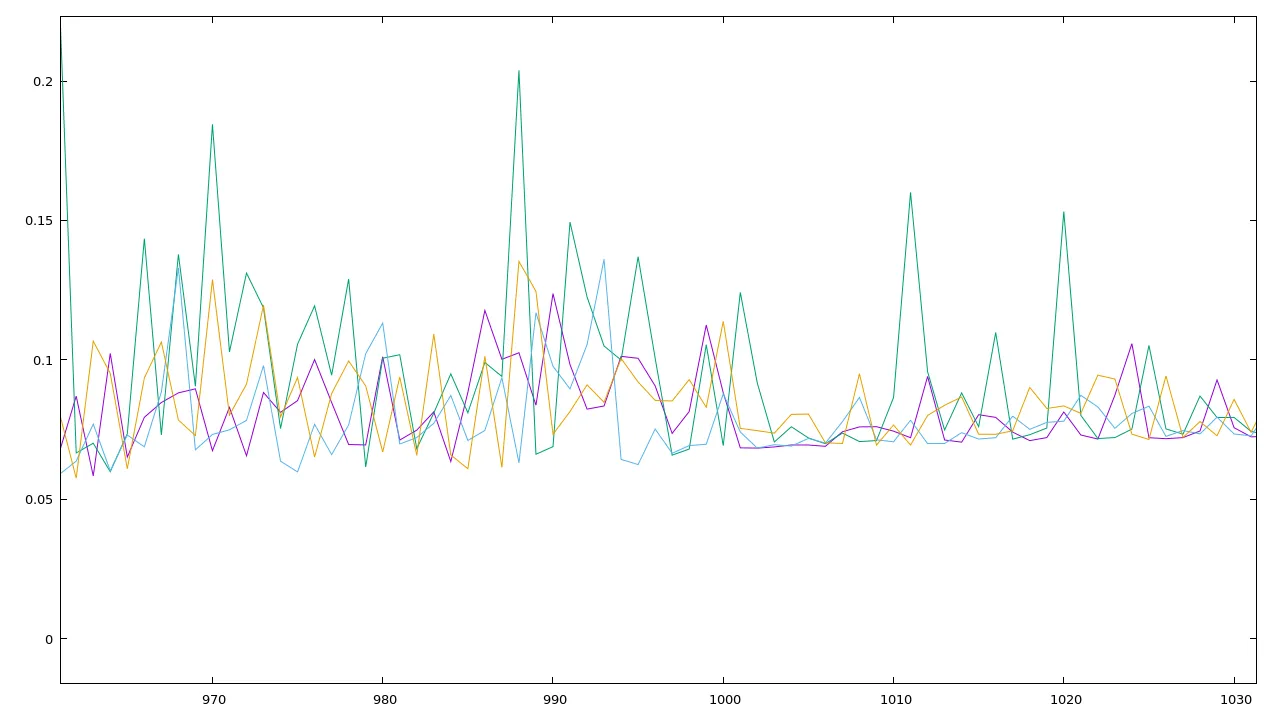
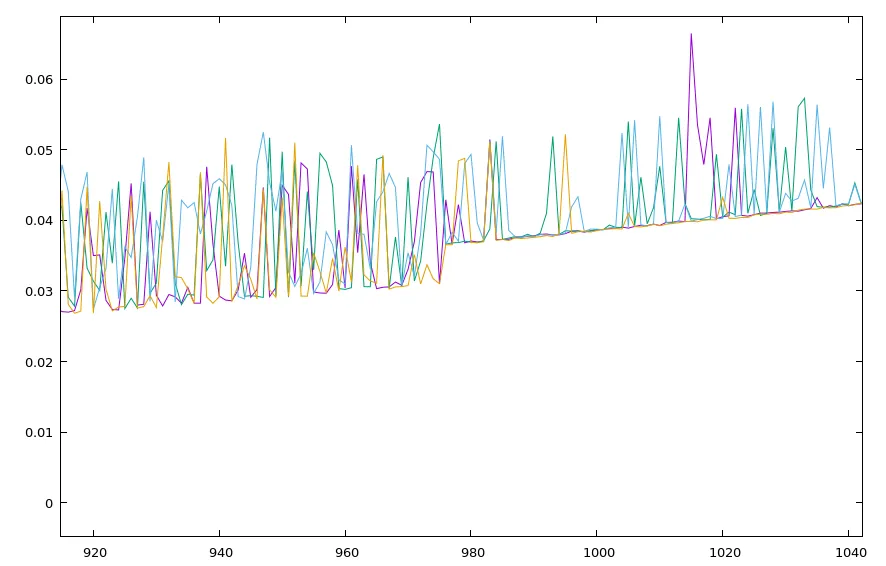
它确实使其变得更快。但是,对我来说这并不奇怪,因为我绘制了这个图:
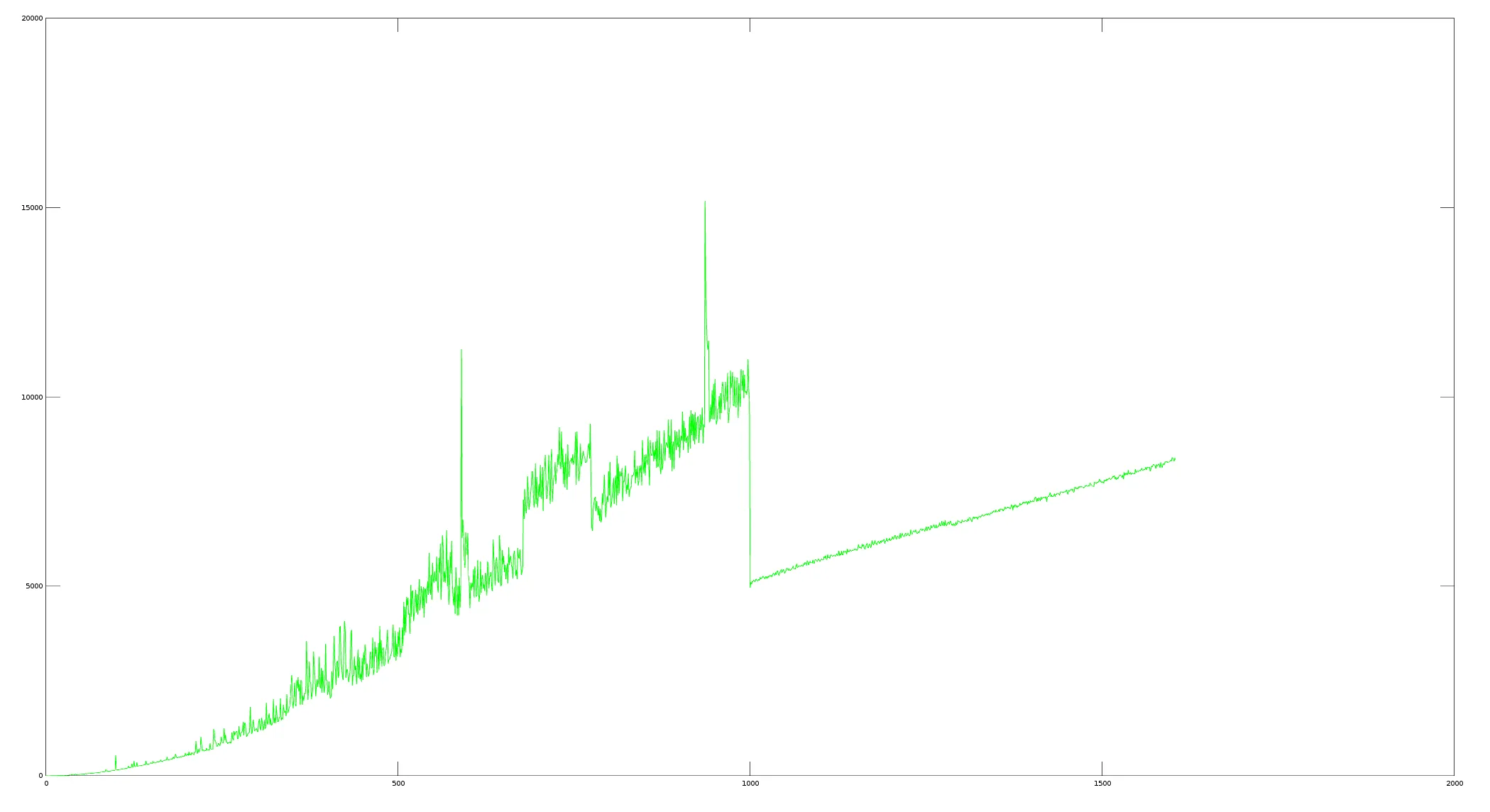
在 x = 1000 处发生了某些事情,我不知道可能是什么。
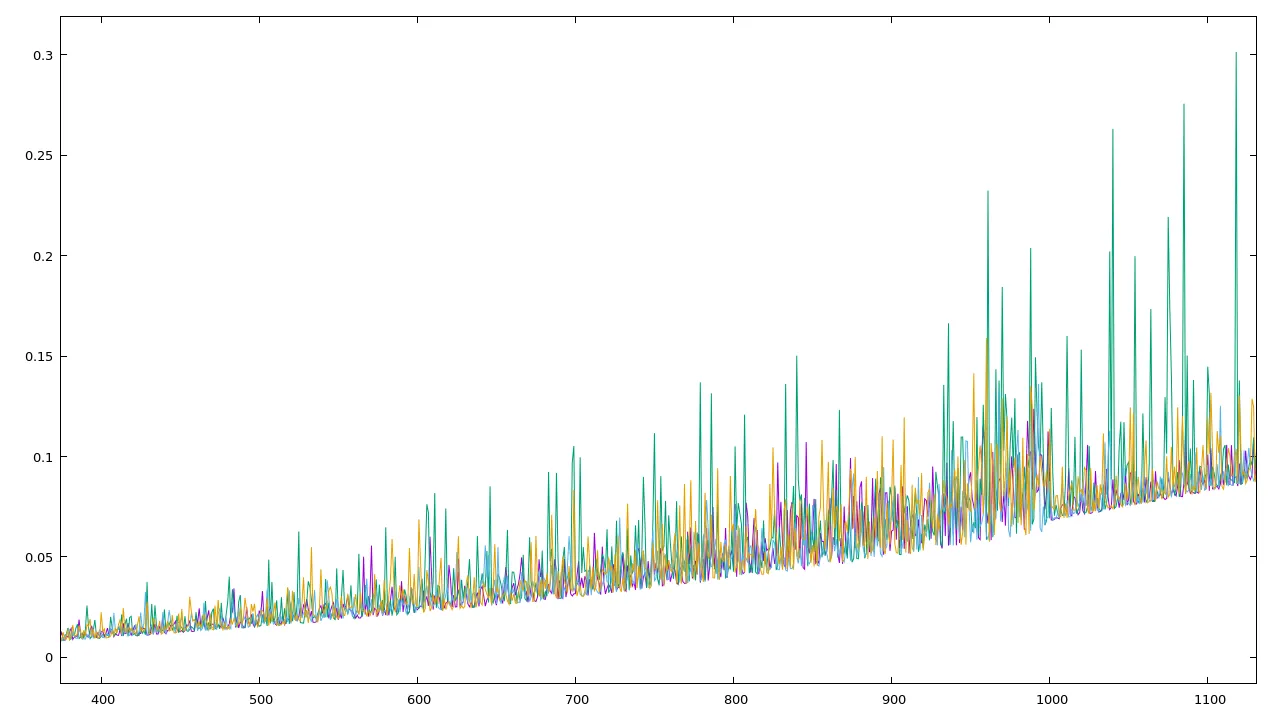
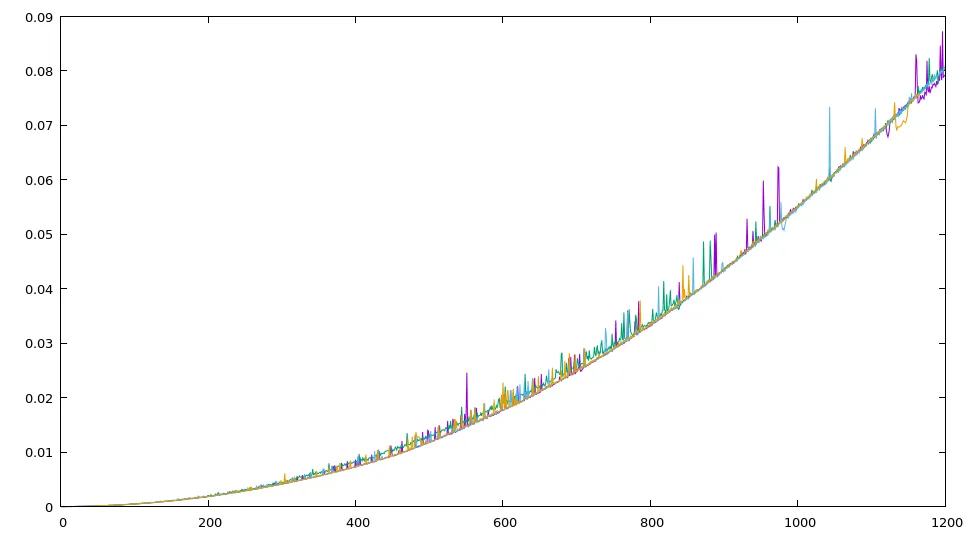
另一个重要的绘图:
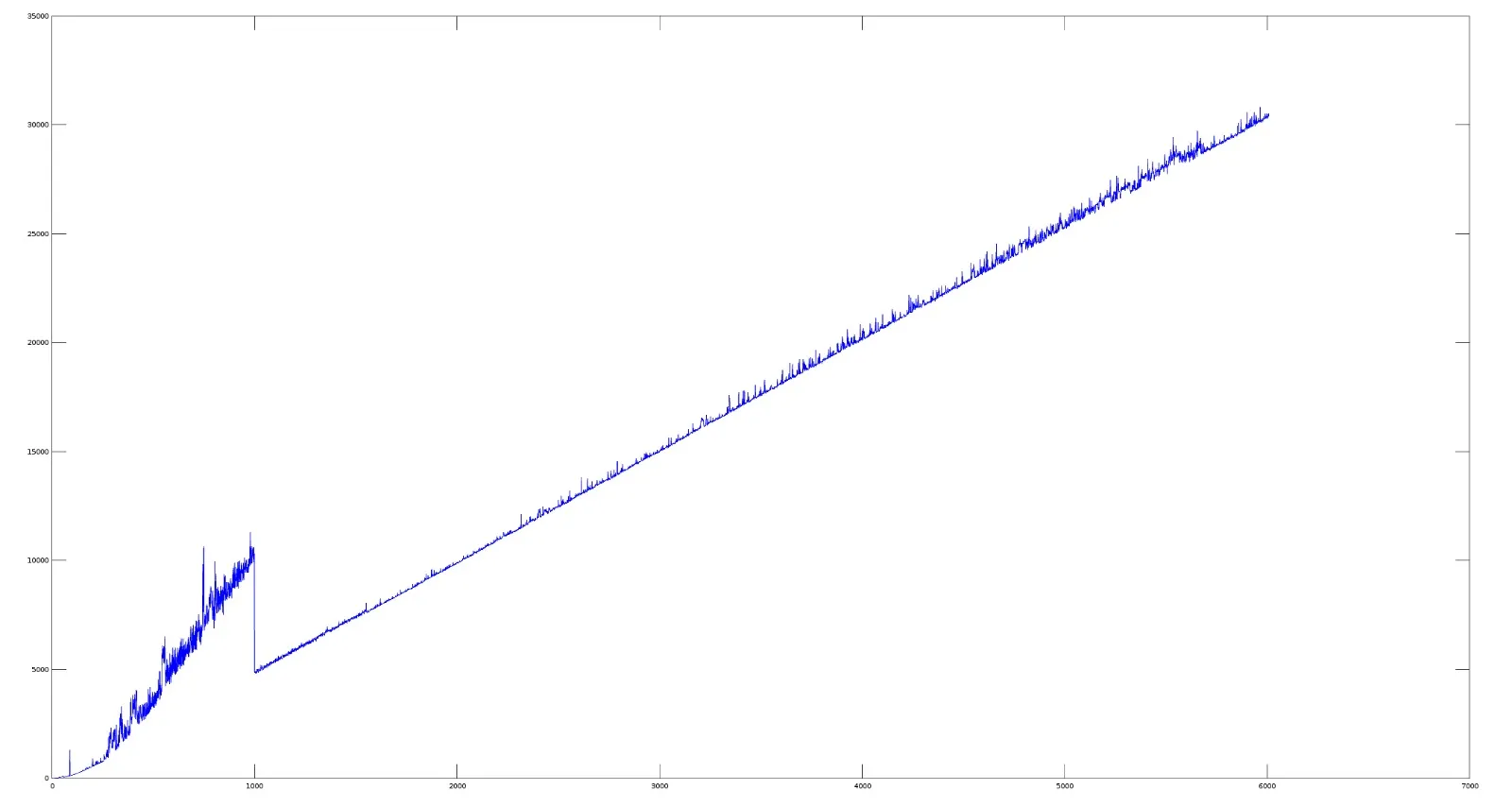
我现在对长度为999的字符串运行了gprof:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
100.15 0.02 0.02 974 20.56 20.56 node::~node()
0.00 0.02 0.00 498688 0.00 0.00 void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&)
0.00 0.02 0.00 1 0.00 0.00 _GLOBAL__sub_I__Z7imprimePK4node
0.00 0.02 0.00 1 0.00 0.00 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&)
^L
Call graph
granularity: each sample hit covers 2 byte(s) for 49.93% of 0.02 seconds
index % time self children called name
54285 node::~node() [1]
0.02 0.00 974/974 test(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
[1] 100.0 0.02 0.00 974+54285 node::~node() [1]
54285 node::~node() [1]
-----------------------------------------------
<spontaneous>
[2] 100.0 0.00 0.02 test(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
0.02 0.00 974/974 node::~node() [1]
0.00 0.00 1/1 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [12]
-----------------------------------------------
0.00 0.00 498688/498688 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [12]
[10] 0.0 0.00 0.00 498688 void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&) [10]
-----------------------------------------------
0.00 0.00 1/1 __libc_csu_init [21]
[11] 0.0 0.00 0.00 1 _GLOBAL__sub_I__Z7imprimePK4node [11]
-----------------------------------------------
0.00 0.00 1/1 test(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
[12] 0.0 0.00 0.00 1 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [12]
0.00 0.00 498688/498688 void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&) [10]
-----------------------------------------------
对于一个大小为1001的字符串:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
100.15 0.02 0.02 974 20.56 20.56 node::~node()
0.00 0.02 0.00 498688 0.00 0.00 void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&)
0.00 0.02 0.00 1 0.00 0.00 _GLOBAL__sub_I__Z7imprimePK4node
0.00 0.02 0.00 1 0.00 0.00 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&)
Call graph
granularity: each sample hit covers 2 byte(s) for 49.93% of 0.02 seconds
index % time self children called name
54285 node::~node() [1]
0.02 0.00 974/974 test(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
[1] 100.0 0.02 0.00 974+54285 node::~node() [1]
54285 node::~node() [1]
-----------------------------------------------
<spontaneous>
[2] 100.0 0.00 0.02 test(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
0.02 0.00 974/974 node::~node() [1]
0.00 0.00 1/1 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [12]
-----------------------------------------------
0.00 0.00 498688/498688 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [12]
[10] 0.0 0.00 0.00 498688 void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&) [10]
-----------------------------------------------
0.00 0.00 1/1 __libc_csu_init [21]
[11] 0.0 0.00 0.00 1 _GLOBAL__sub_I__Z7imprimePK4node [11]
-----------------------------------------------
0.00 0.00 1/1 test(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) [2]
[12] 0.0 0.00 0.00 1 numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [12]
0.00 0.00 498688/498688 void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&) [10]
-----------------------------------------------
Index by function name
[11] _GLOBAL__sub_I__Z7imprimePK4node [1] node::~node()
[12] numberOfUniqueSubstrings(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, node*&) [10] void std::vector<node*, std::allocator<node*> >::_M_emplace_back_aux<node* const&>(node* const&)
然而,似乎运行分析器会消除这种影响,两种情况下的时间几乎相同。
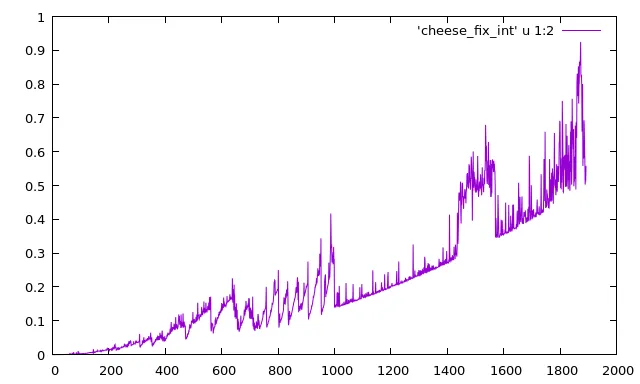
vector或string)使用另一种算法,如果它包含的元素超过1000个。 - Denis Sologubchar indexToNext = i;应该改为int indexToNext = i;。一旦indexToNext达到了128,这个函数就开始访问aString中的负位置。 - Anton