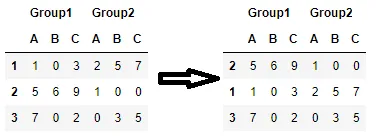
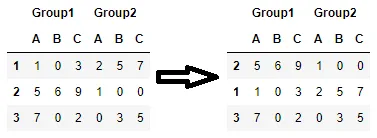
我有一个带有多级索引的 Pandas 数据框,我想根据特定列中的值对其进行排序。我的数据集如下:
Group1 Group2
A B C A B C
1 1 0 3 2 5 7
2 5 6 9 1 0 0
3 7 0 2 0 3 5
我想按照Group 1列中的C值,将所有数据和索引降序排序,使我的结果如下:
Group1 Group2
A B C A B C
2 5 6 9 1 0 0
1 1 0 3 2 5 7
3 7 0 2 0 3 5
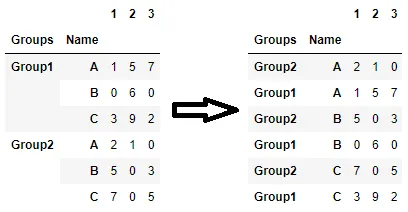
使用我现有数据的结构,是否可能进行此排序操作?或者应该将 Group1 转移到索引侧边进行操作?