首先,我将从这篇文章中讨论我的需求......
现在我需要从另一个excel csv文件更新现有的excel xlsm文件,因为这个csv文件是从Outlook邮箱收件箱导出的csv文件,而且这是我的Outlook邮件csv的模板。
|---------------------|------------------|------------------|------------|
| Subject | Body | From: (Name) | To: (Name) |
|---------------------|------------------|------------------|------------|
|blabla LCAIN5678 bla |bla bla bla bla |bla bla bla bla |bla bla bla |
|---------------------|------------------|------------------|------------|
在使用pandas读取csv文件后,我正在工作和分析这个文件,并使用str.extract来提取特定的数据。以下是我提取数据的代码,以从csv文件中提取特定的字符串,例如LCAIN5678,其中包含五个字符和五个数字,然后使用dropna()。
这是代码:
# this object extract 5 chars and 5 numbers from specific column in csv
replaced_sbj_value = myOutlook_inBox['Subject']
.str.extract(pat='(L(?:DEL|CAI|SIN).\d{5})').dropna()
这是我的xlsx文件,由pandas读取
gov_tracker_sheet = pd.read_excel(r'' + mydi
sheet_name
header=1)
这是我用 pandas 读取的
csv 文件。myOutlook_inBox = pd.read_csv(r'' + mydir + 'test.CSV
encoding='latin-1')
然后我像这样初始化它:
myOutlook_inBox["Subject"] = replaced_sbj_value
print (replaced_sbj_value)
要达到这种效果
|-----------------|
| Subject |
|-----------------|
| LCAIN5678 |
|-----------------|
然后我使用一些函数(例如loc和str.contains)创建一个条件。
这个条件是用于在csv中过滤一些文本的筛选器。
# Condition 1: any mail from mowafy to te
frm_mwfy_to_te = myOutlook_inBox.loc[myOutlook_inBox['From:
(Name)'].str.contains("mowafy", na=False) \
& myOutlook_inBox['To:
(Name)'].str.contains("te", na=False)] \
.drop_duplicates(keep=False)
然后,我使用join方法创建一个变量,将变量frm_mwfy_to_te与要更新的Excel xlsm文件进行join
filtered_data_cond1 = gov_tracker_sheet.loc[
gov_tracker_sheet['SiteCode']
.str.contains('|'.join(frm_mwfy_to_te.Subject))]
print(filtered_data_cond1)
从 xlsm Excel 文件中获取需要更新的行。
最后,我创建了一个元组变量用于更新 Dataframe。
以下为我的 tuple 变量。
values = tuple(filtered_data_cond1['Pending '].values.tolist())
这是我的 `tuple` 值的输出结果。
(u'TE', u'PP', u'TE', u'TE', u'TE', u'TE', u'TE', u'TE', u'TE')
所以我从这里开始使用 Regex,使用replace方法。
这是我创建的替换变量:
updated_gov_tracker = gov_tracker_sheet.replace(to_replace=values,
value='xxxxxxxxxxxx',
regex=False)
这段代码可以运行,但它只是替换了包含“TE”文本的整个
xlsm文件中的所有行,我需要仅更新需要的行。我尝试了另一种方法,类似于这样的方式,但它并没有正常工作。
updated_gov_tracker=re.sub(values,"xxxxxxxxx",gov_tracker_sheet)
第二件事,我想要用新的
Dataframe 替换旧的 xlsm 表格,但不想丢失 Excel 中的 macros。
编辑后
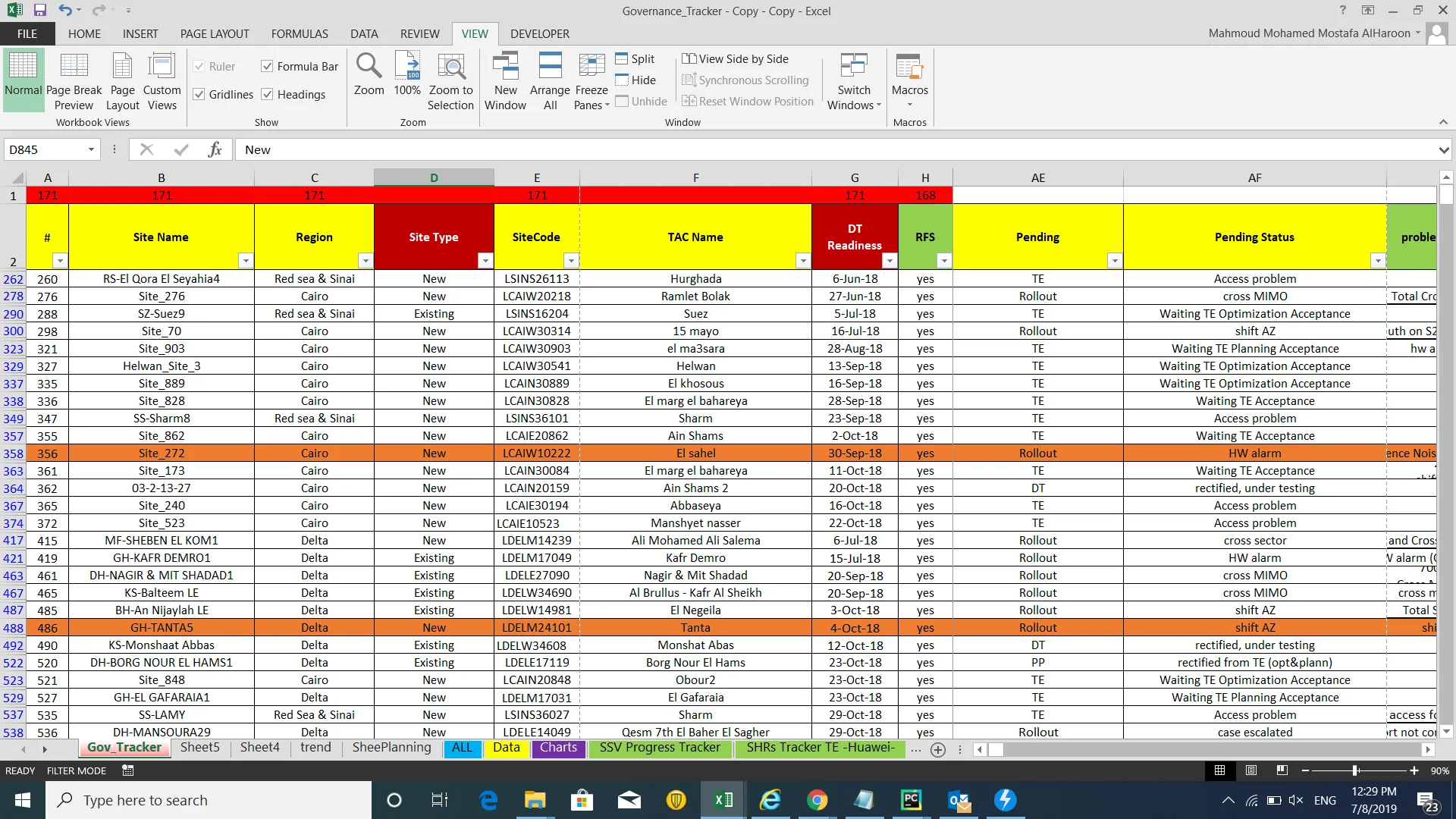
这是我想要更新的现有 Excel 文件的外观
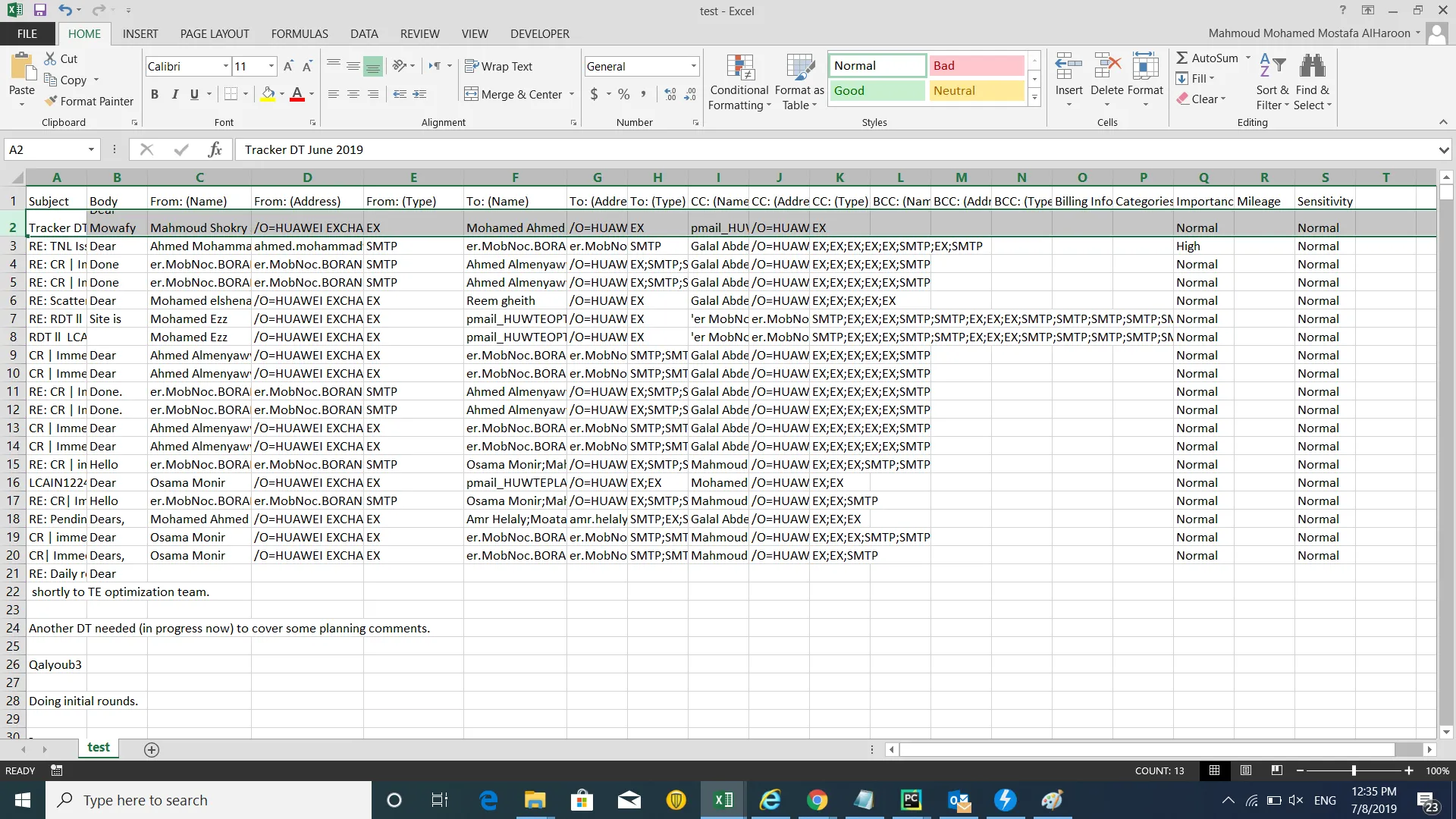
这是我的 Outlook 电子邮件中的 csv 文件的外观
现在,经过搜索,我发现 xlwings 可以帮助我选择行的范围并写入新的 updatedvalue。因此,我现在需要获取 tuple 变量,该变量包含称为站点代码的列的字符串,最后我现在需要根据元组中的值行来更新 Excel xlsm 第一张表
示例
我有一个类似于以下内容的元组值 LCAIN12345 LCAIN54632 LCAIN78965 blablabla
现在,这些值已经存在于称为 Gov_Tracker 的表格的名为 SiteCode 的列中,我想要根据这些值更新某些列中的 rows,例如我想要更新称为 Pending、Pending Status 和 blablabla 的列。
现在,我想要修改这些列的行值,如将 Pending、Pending Status、blablabla 中的旧值更改为新值 TE、等待 TE 接受 blablabla 的值。
希望这些信息足够清楚明了。
gov_tracker_sheet只是我在xlsm中的主表格,请检查我的帖子编辑。 - user11630968