有没有可能使用pandas.drop_duplicates与比较运算符一起使用,以便比较特定列中的两个对象以识别重复项?如果不行,那么有什么替代方法?
这是一个可以使用它的示例:
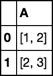
我有一个 pandas DataFrame,其中某一列的值为列表,并希望基于列 A 删除重复项。
import pandas as pd
df = pd.DataFrame( {'A': [[1,2],[2,3],[1,2]]} )
print df
给我
A
0 [1, 2]
1 [2, 3]
2 [1, 2]
使用 pandas.drop_duplicates。
df.drop_duplicates( 'A' )
给我一个 TypeError
[...]
TypeError: type object argument after * must be a sequence, not itertools.imap
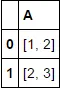
然而,我的期望结果是
A
0 [1, 2]
1 [2, 3]
我的比较函数会在这里:
def cmp(x,y):
return x==y
但原则上它可能是其他东西,例如,
def cmp(x,y):
return x==y and len(x)>1
如何以高效的方式基于比较函数去除重复项?
更进一步,如果我有更多列需要使用不同的比较函数进行比较,我该怎么办呢?
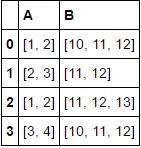
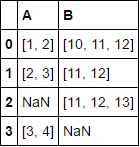
df.A.apply(sum)- 如果在其中加入[0, 3]和[10, -5],你会感到困惑... - Jon Clementssum作为示例有些误导人,因为根据OP的数据,[0, 3]并不直观地重复了[1, 2]...但是重新阅读后,我明白你的意思是要演示groupby/first - 我个人认为在这种情况下,使用tuple或frozenset可能会更好一些... - Jon Clements