我的数据框长这样:
star_rating actors_list
0 9.3 [u'Tim Robbins', u'Morgan Freeman']
1 9.2 [u'Marlon Brando', u'Al Pacino', u'James Caan']
2 9.1 [u'Al Pacino', u'Robert De Niro']
3 9.0 [u'Christian Bale', u'Heath Ledger']
4 8.9 [u'John Travolta', u'Uma Thurman']
我想提取演员列表列中最常见的姓名。我发现了这段代码,你有更好的建议吗?尤其是针对大数据。
import pandas as pd
df= pd.read_table (r'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/imdb_1000.csv',sep=',')
df.actors_list.str.replace("(u\'|[\[\]]|\')",'').str.lower().str.split(',',expand=True).stack().value_counts()
(这个数据)的预期输出为:
robert de niro 13
tom hanks 12
clint eastwood 11
johnny depp 10
al pacino 10
james stewart 9
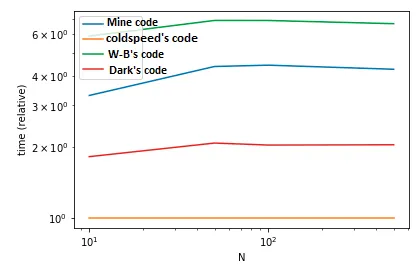
expand=True会让你的系统崩溃。 - Bharath M Shettyexpand=True,.stack()将无法工作。 - Reza energy