最近我发现了一种替代Google的Protocol Buffers和JSON的二进制序列化格式,它叫做MessagePack,并且性能优于两者。
MongoDB用的BSON序列化格式也值得一提,因为它可以用来存储数据。
有人能具体说明下BSON与MessagePack的区别及其优缺点吗?
为了完整列出高性能的二进制序列化格式,还有Gobs。虽然与其他所有提到的格式相比,它们不是语言无关的,并依赖于Go的内置反射机制,但除了Go之外,至少还有一种语言也有Gobs库。
最近我发现了一种替代Google的Protocol Buffers和JSON的二进制序列化格式,它叫做MessagePack,并且性能优于两者。
MongoDB用的BSON序列化格式也值得一提,因为它可以用来存储数据。
有人能具体说明下BSON与MessagePack的区别及其优缺点吗?
为了完整列出高性能的二进制序列化格式,还有Gobs。虽然与其他所有提到的格式相比,它们不是语言无关的,并依赖于Go的内置反射机制,但除了Go之外,至少还有一种语言也有Gobs库。
// 请注意,我是MessagePack的作者,这个答案可能有偏见。
格式设计
与JSON兼容性
BSON的名称虽然与JSON类似,但与MessagePack相比,它与JSON的兼容性不太好。
BSON具有特殊类型,如“ObjectId”、“Min key”、“UUID”或“MD5”(我认为这些类型是MongoDB所需的)。这些类型与JSON不兼容。这意味着当您将对象从BSON转换为JSON时,某些类型信息可能会丢失,但当这些特殊类型在BSON源中时,当然只有这种情况才会发生。在单个服务中同时使用JSON和BSON可能是一个缺点。
MessagePack旨在能够透明地从/到JSON进行转换。
MessagePack比BSON更小
MessagePack的格式比BSON更简洁。因此,MessagePack可以序列化比BSON更小的对象。
例如,一个简单的映射{"a":1,"b":2}在MessagePack中序列化为7个字节,而BSON使用19个字节。
BSON支持原地更新
使用BSON,可以修改已存储对象的一部分,而无需重新对整个对象进行序列化。假设在文件中存储了一个映射{"a":1,"b":2},您想要将"a"的值从1更新为2000。
使用MessagePack,1仅使用1个字节,但2000使用3个字节。因此,“b”必须向后移动2个字节,而“b”未被修改。
使用BSON,1和2000都使用5个字节。由于这种冗余性,您不必移动“b”。
MessagePack具有RPC
MessagePack、Protocol Buffers、Thrift和Avro支持RPC。但是,BSON不支持。
这些差异意味着,MessagePack最初设计用于网络通信,而BSON设计用于存储。
实现和API设计
MessagePack具有类型检查API(Java、C++和D)
MessagePack支持静态类型。
用于JSON或BSON的动态类型对于像Ruby、Python或JavaScript这样的动态语言非常有用。但是对于静态语言来说很麻烦。您必须编写枯燥的类型检查代码。
MessagePack提供类型检查API。它将动态类型对象转换为静态类型对象。这里是一个简单的示例(C ++):
#include <msgpack.hpp>
class myclass {
private:
std::string str;
std::vector<int> vec;
public:
// This macro enables this class to be serialized/deserialized
MSGPACK_DEFINE(str, vec);
};
int main(void) {
// serialize
myclass m1 = ...;
msgpack::sbuffer buffer;
msgpack::pack(&buffer, m1);
// deserialize
msgpack::unpacked result;
msgpack::unpack(&result, buffer.data(), buffer.size());
// you get dynamically-typed object
msgpack::object obj = result.get();
// convert it to statically-typed object
myclass m2 = obj.as<myclass>();
}
MessagePack支持IDL
与类型检查API相关,MessagePack支持IDL。(规范可从以下链接获取:http://wiki.msgpack.org/display/MSGPACK/Design+of+IDL)
Protocol Buffers和Thrift需要IDL(不支持动态类型),并提供更成熟的IDL实现。
MessagePack具有流API(Ruby、Python、Java、C++等)
MessagePack支持流式反序列化器。这个功能对于网络通信很有用。以下是一个示例(Ruby):
require 'msgpack'
# write objects to stdout
$stdout.write [1,2,3].to_msgpack
$stdout.write [1,2,3].to_msgpack
# read objects from stdin using streaming deserializer
unpacker = MessagePack::Unpacker.new($stdin)
# use iterator
unpacker.each {|obj|
p obj
}
我认为重要的是要提到,这取决于您的客户端/服务器环境的样子。
如果您多次传递未经检查的字节,例如使用消息队列系统或将日志条目流式传输到磁盘,则可能更喜欢二进制编码以强调紧凑性。否则,不同环境下会有不同的情况。
某些环境可以非常快速地进行msgpack / protobuf的序列化和反序列化,而其他环境则不然。一般来说,语言/环境越低级,二进制序列化的效果就越好。在高级语言(node.js、.Net、JVM)中,您经常会看到JSON序列化实际上更快。那么问题就变成了您的网络开销是否比内存/CPU受限更少?
关于msgpack vs bson vs protocol buffers... msgpack是三者中所需字节数最小的,protocol buffers大约相同。BSON定义的本机类型比其他两种类型更广泛,可能更符合您的对象模型,但这使其更冗长。Protocol buffers具有流设计,这使其成为二进制传输/存储格式的更自然格式。
个人而言,除非存在更轻量级的数据传输的明显需求,否则我会倾向于直接使用JSON提供的透明度。通过使用压缩的数据传输HTTP,格式间的网络开销差异甚至更小。
正如作者所说,MessagePack最初是为网络通信设计的,而BSON则是为数据存储设计的。
MessagePack很紧凑,而BSON则比较冗长。MessagePack旨在提高空间效率,而BSON则是为CURD(时间效率)而设计的。
最重要的是,MessagePack的类型系统(前缀)遵循Huffman编码,这里我画了一个MessagePack的Huffman树(点击链接查看图像):
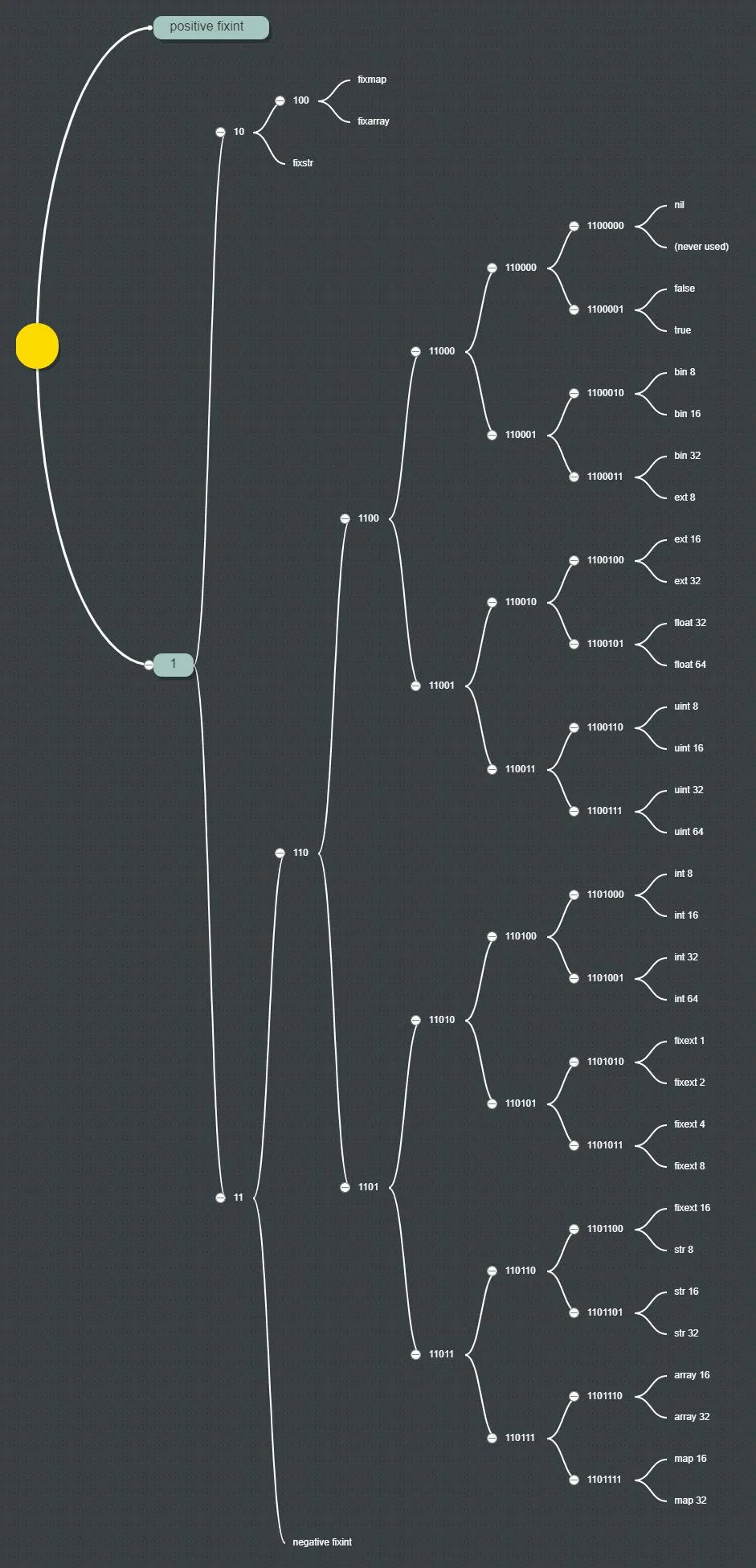
一个尚未被提及的关键区别是,BSON包含整个文档以及进一步嵌套的子文档的字节大小信息。
document ::= int32 e_list
//test_mp.js
var msg = require('msgpack');
var fs = require('fs');
var article = fs.readFileSync('Article.mpack');
for (var i = 0; i < 10000; i++) {
msg.unpack(article);
}
JSON:
// test_json.js
var msg = require('msgpack');
var fs = require('fs');
var article = fs.readFileSync('Article.json', 'utf-8');
for (var i = 0; i < 10000; i++) {
JSON.parse(article);
}
有时候是这样的:
Anarki:Downloads oleksii$ time node test_mp.js
real 2m45.042s
user 2m44.662s
sys 0m2.034s
Anarki:Downloads oleksii$ time node test_json.js
real 2m15.497s
user 2m15.458s
sys 0m0.824s
那么节省空间了,但速度快吗?不是的。
测试版本:
Anarki:Downloads oleksii$ node --version
v0.8.12
Anarki:Downloads oleksii$ npm list msgpack
/Users/oleksii
└── msgpack@0.1.7
simplejson 2.6.2需要66.7秒,而msgpack 0.2.2只需要28.8秒。 - Day我进行了一个简单的基准测试,比较了MessagePack和BSON的编码和解码速度。如果你有大型二进制数组,BSON的速度会更快:
BSON writer: 2296 ms (243487 bytes)
BSON reader: 435 ms
MESSAGEPACK writer: 5472 ms (243510 bytes)
MESSAGEPACK reader: 1364 ms
public class TestData
{
public byte[] buffer;
public bool foobar;
public int x, y, w, h;
}
static void Main(string[] args)
{
try
{
int loop = 10000;
var buffer = new TestData();
TestData data2;
byte[] data = null;
int val = 0, val2 = 0, val3 = 0;
buffer.buffer = new byte[243432];
var sw = new Stopwatch();
sw.Start();
for (int i = 0; i < loop; i++)
{
data = SerializeBson(buffer);
val2 = data.Length;
}
var rc1 = sw.ElapsedMilliseconds;
sw.Restart();
for (int i = 0; i < loop; i++)
{
data2 = DeserializeBson(data);
val += data2.buffer[0];
}
var rc2 = sw.ElapsedMilliseconds;
sw.Restart();
for (int i = 0; i < loop; i++)
{
data = SerializeMP(buffer);
val3 = data.Length;
val += data[0];
}
var rc3 = sw.ElapsedMilliseconds;
sw.Restart();
for (int i = 0; i < loop; i++)
{
data2 = DeserializeMP(data);
val += data2.buffer[0];
}
var rc4 = sw.ElapsedMilliseconds;
Console.WriteLine("Results:", val);
Console.WriteLine("BSON writer: {0} ms ({1} bytes)", rc1, val2);
Console.WriteLine("BSON reader: {0} ms", rc2);
Console.WriteLine("MESSAGEPACK writer: {0} ms ({1} bytes)", rc3, val3);
Console.WriteLine("MESSAGEPACK reader: {0} ms", rc4);
}
catch (Exception e)
{
Console.WriteLine(e);
}
Console.ReadLine();
}
static private byte[] SerializeBson(TestData data)
{
var ms = new MemoryStream();
using (var writer = new Newtonsoft.Json.Bson.BsonWriter(ms))
{
var s = new Newtonsoft.Json.JsonSerializer();
s.Serialize(writer, data);
return ms.ToArray();
}
}
static private TestData DeserializeBson(byte[] data)
{
var ms = new MemoryStream(data);
using (var reader = new Newtonsoft.Json.Bson.BsonReader(ms))
{
var s = new Newtonsoft.Json.JsonSerializer();
return s.Deserialize<TestData>(reader);
}
}
static private byte[] SerializeMP(TestData data)
{
return MessagePackSerializer.Typeless.Serialize(data);
}
static private TestData DeserializeMP(byte[] data)
{
return (TestData)MessagePackSerializer.Typeless.Deserialize(data);
}