我使用statsmodels包中的ARIMA来预测时间序列中的值:
plt.plot(ind, final_results.predict(start=0 ,end=26))
plt.plot(ind, forecast.values)
plt.show()
我以为这两种方法会得到相同的结果,但实际上,我得到了这个:
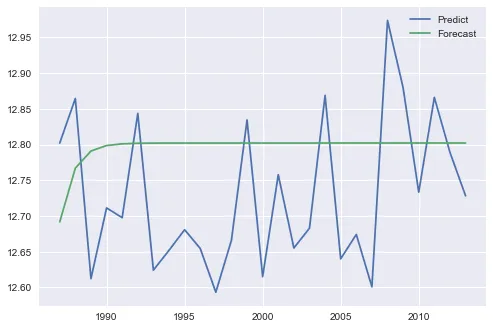
predict() 还是 forecast()。我使用statsmodels包中的ARIMA来预测时间序列中的值:
plt.plot(ind, final_results.predict(start=0 ,end=26))
plt.plot(ind, forecast.values)
plt.show()
我以为这两种方法会得到相同的结果,但实际上,我得到了这个:
predict() 还是 forecast()。forecast() 进行了样本外预测,但使用 predict 进行了样本内预测。基于 ARIMA 方程的性质,长期预测时,样本外预测往往会收敛到样本均值。forecast() 和 predict() 的工作方式,我系统地比较了 ARIMA_results 类中的各种模型。可以使用 此存储库 中的 statsmodels_arima_comparison.py 来重现比较结果。我研究了每个 order=(p,d,q) 组合,只限制 p, d, q 为 0 或 1。例如,可以使用 order=(1,0,0) 获得简单的自回归模型。
简而言之,我研究了三个选项,使用以下(平稳)时间序列:for t in range(len(test)):
model = ARIMA(history, order=order)
model_fit = model.fit(disp=-1)
yhat_f = model_fit.forecast()[0][0]
yhat_p = model_fit.predict(start=len(history), end=len(history))[0]
predictions_f.append(yhat_f)
predictions_p.append(yhat_p)
history.append(test[t])
B. 接下来,我研究了通过迭代预测测试序列的下一个点,并将此预测附加到历史记录中的样本外预测。
for t in range(len(test)):
model_f = ARIMA(history_f, order=order)
model_p = ARIMA(history_p, order=order)
model_fit_f = model_f.fit(disp=-1)
model_fit_p = model_p.fit(disp=-1)
yhat_f = model_fit_f.forecast()[0][0]
yhat_p = model_fit_p.predict(start=len(history_p), end=len(history_p))[0]
predictions_f.append(yhat_f)
predictions_p.append(yhat_p)
history_f.append(yhat_f)
history_f.append(yhat_p)
C. 我使用了forecast(step=n)参数和predict(start, end)参数来进行内部多步预测。
model = ARIMA(history, order=order)
model_fit = model.fit(disp=-1)
predictions_f_ms = model_fit.forecast(steps=len(test))[0]
predictions_p_ms = model_fit.predict(start=len(history), end=len(history)+len(test)-1)
结果表明:
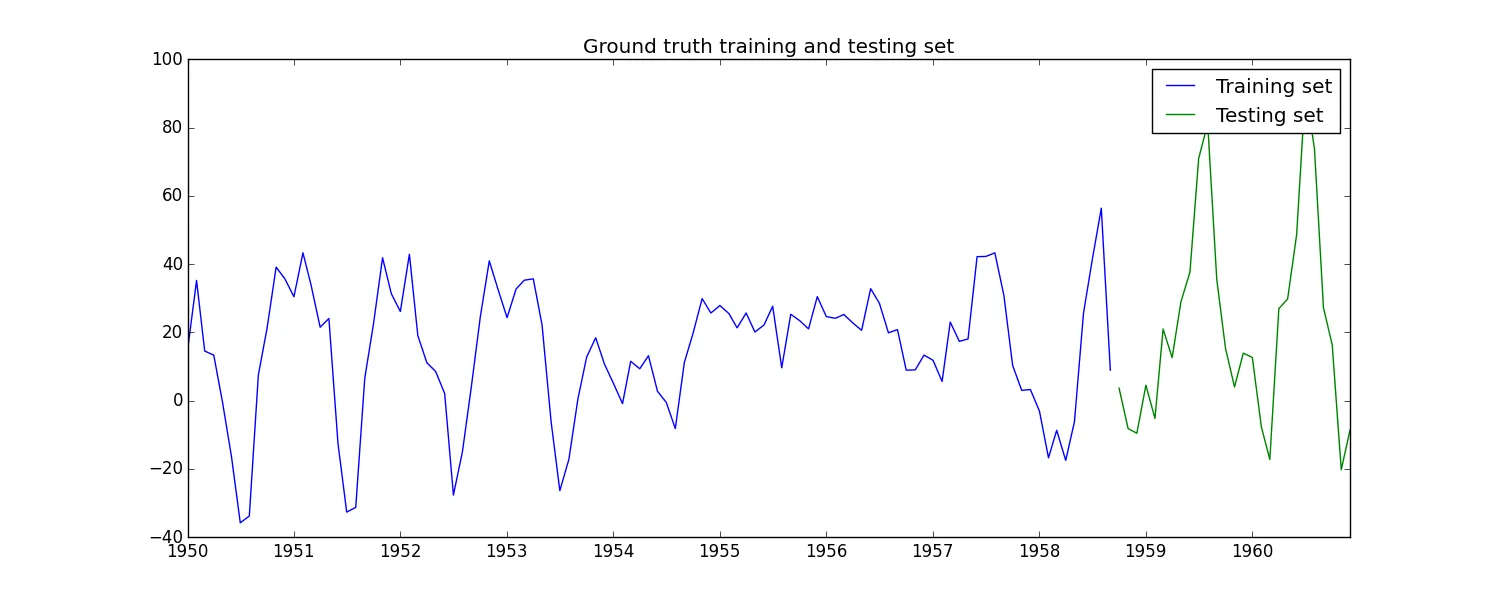
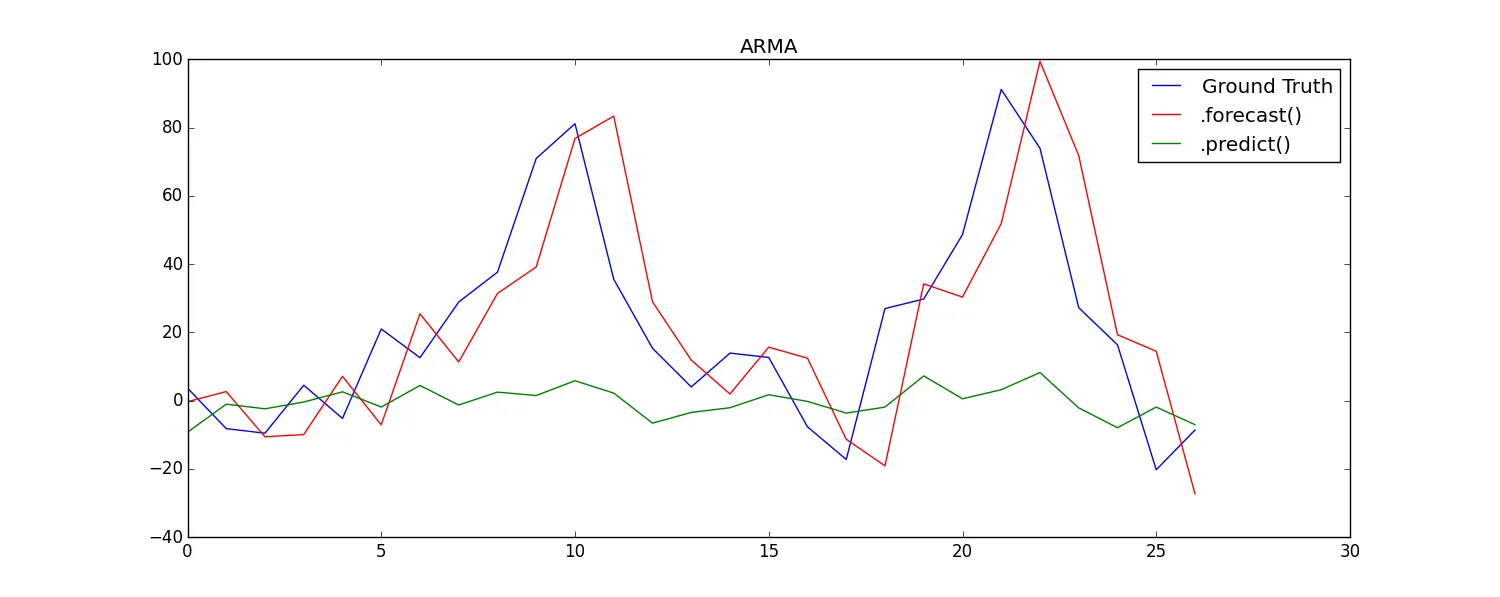
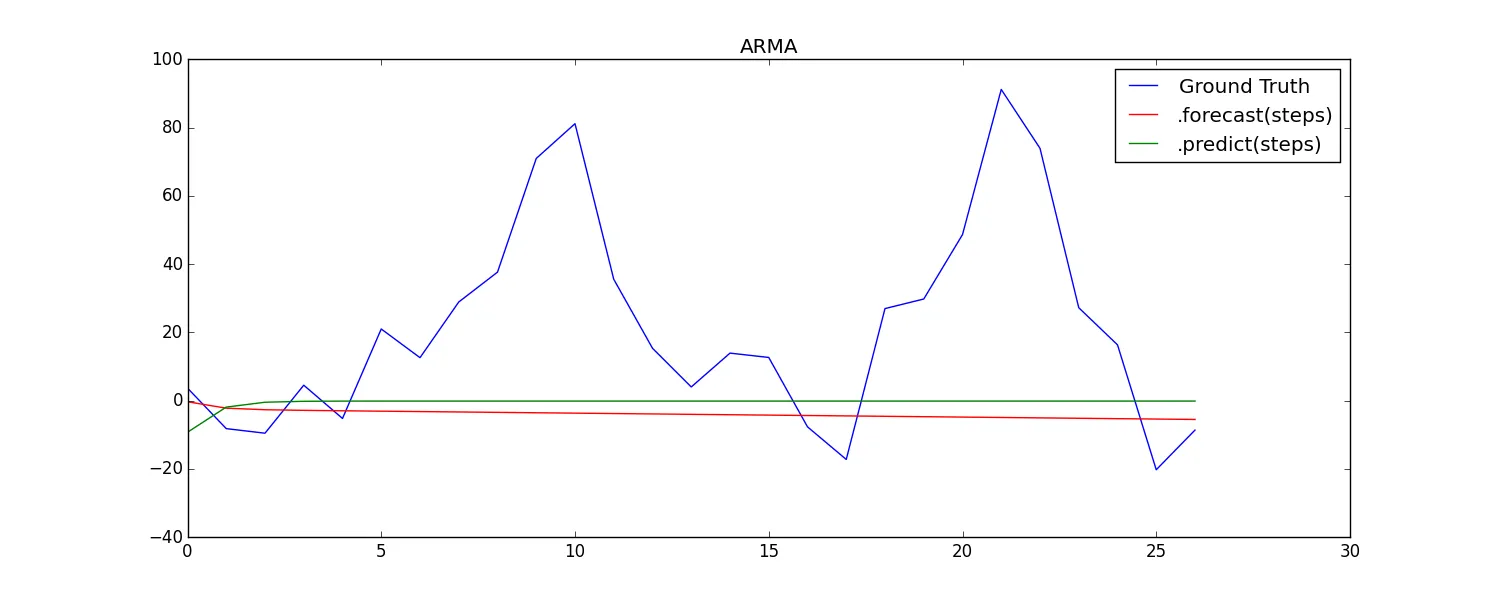
A. 对于AR,预测和预测会产生相同的结果,但对于ARMA,会产生不同的结果:测试时间序列图
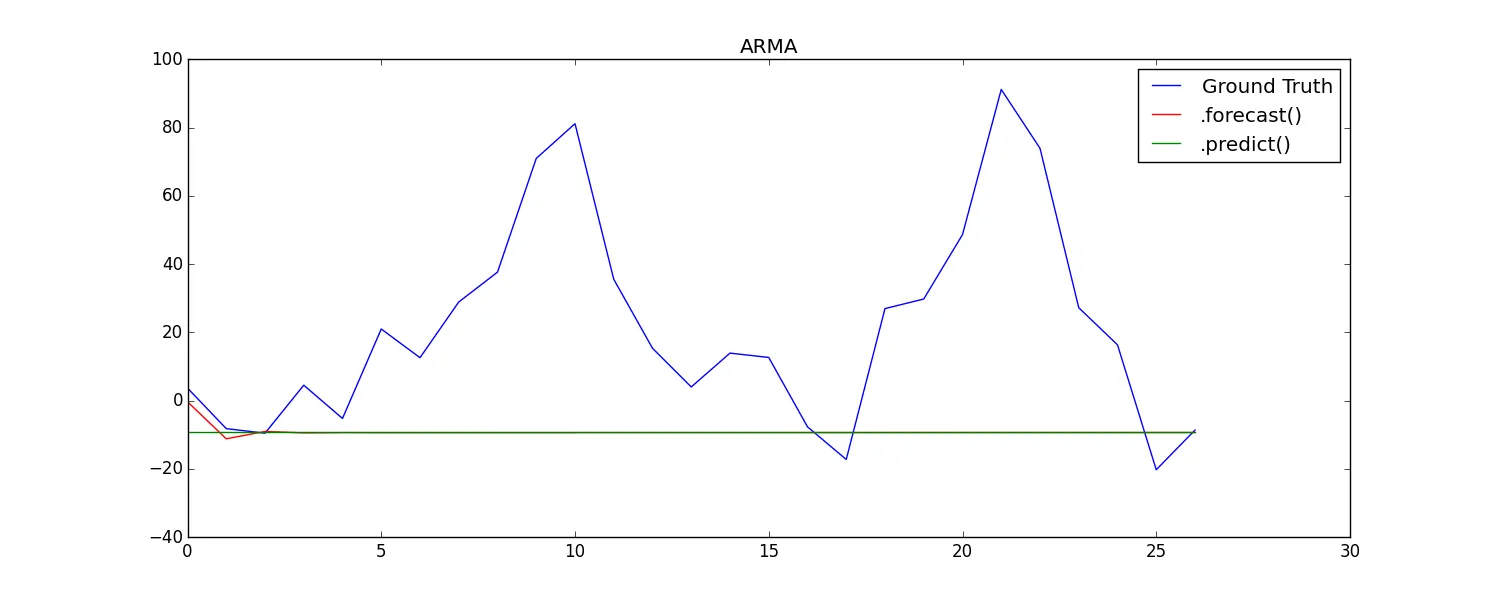
B. 对于AR和ARMA,预测和预测会产生不同的结果:测试时间序列图
C. 对于AR,预测和预测会产生相同的结果,但对于ARMA,会产生不同的结果:测试时间序列图
此外,在比较B和C中看似相同的方法时,我发现结果存在微妙但明显的差异。
我建议这些差异主要来自于在forecast()和predict()中“预测是在原始内生变量的级别上完成”的事实,会产生水平差异的预测(比较API参考)。
此外,鉴于我更信任statsmodels函数的内部功能而不是我的简单迭代预测循环(这是主观的),我建议使用forecast(step)或predict(start, end)。
继续noteven2degrees的回复,我提交了一个拉取请求来更正B方法中的history_f.append(yhat_p)为history_p.append(yhat_p)。
另外,就像noteven2degrees建议的那样,与forecast()不同,predict()需要一个参数typ='levels'来输出预测结果,而不是差分预测。
在进行以上两个更改后,方法B产生了与方法C相同的结果,而方法C所需时间远少于方法B,这是合理的。并且这两种方法都收敛到趋势,因为我认为这与模型本身的平稳性有关。
无论采用哪种方法,无论p、d、q的配置如何,forecast()和predict()都会产生相同的结果。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
statsmodel文档的建议,predict用于样本内预测,而forecast仅用于样本外预测。predict,forecast。 - Ehsan Tabatabaei