看起来可以使用
fastparquet将行组附加到已存在的parquet文件中。这是一个非常独特的功能,因为大多数库都没有这个实现。
以下是来自
pandas doc的内容:
DataFrame.to_parquet(path, engine='auto', compression='snappy', index=None, partition_cols=None, **kwargs)
我们需要同时传递引擎和**kwargs。
引擎{‘auto’, ‘pyarrow’, ‘fastparquet’}
**kwargs - 传递给parquet库的额外参数。
**kwargs - 在这里我们需要传递的是:append=True (来自
fastparquet)
import pandas as pd
from pathlib import Path
df = pd.DataFrame({'col1': [1, 2,], 'col2': [3, 4]})
file_path = Path("D:\\dev\\output.parquet")
if file_path.exists():
df.to_parquet(file_path, engine='fastparquet', append=True)
else:
df.to_parquet(file_path, engine='fastparquet')
如果将append设置为True并且文件不存在,则会显示以下错误。
AttributeError: 'ParquetFile' object has no attribute 'fmd'
运行以上脚本3次后,我在parquet文件中得到以下数据。
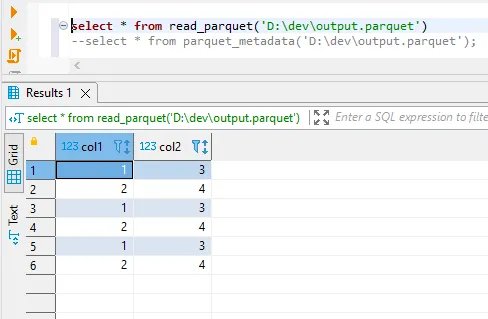
如果我检查元数据,我可以看到这导致了3个行组。
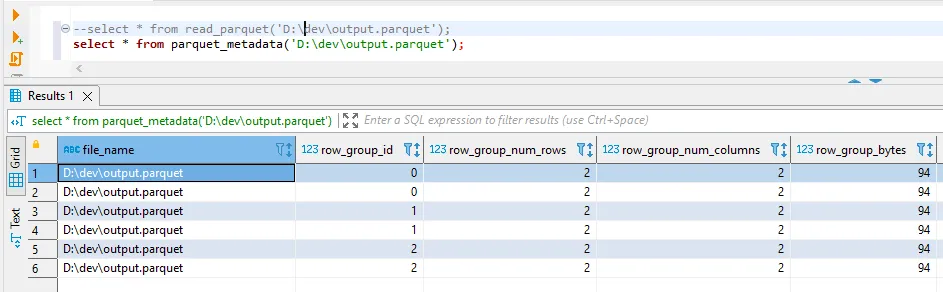
注意:
如果你写太多小的行组,追加可能会效率低下。通常建议的行组大小接近于100,000或1,000,000行。这对于非常小的行组有一些好处。压缩效果会更好,因为压缩仅在行组内进行。存储统计信息的开销也会更少,因为每个行组都存储自己的统计信息。
to_parquet()API没有append模式。如果您想要追加到一个文件中,可以使用文件的append模式。这就是我之前试图表达的内容。 - Shihe Zhang