我创建了这个数据框:
import pandas as pd
columns = pd.MultiIndex.from_tuples([("x", "", ""), ("values", "a", "a.b"), ("values", "c", "")])
df0 = pd.DataFrame([(0,10,20),(1,100,200)], columns=columns)
df0
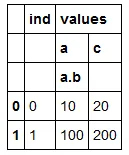
我将 df0 导出到 Excel 文件:
df0.to_excel("test.xlsx")
然后重新加载它:
df1 = pd.read_excel("test.xlsx", header=[0,1,2])
df1
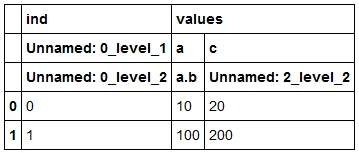
同时我有未命名的列名 Unnamed :....
为了使df1看起来像初始的df0,我运行了以下命令:
def rename_unnamed(df, label=""):
for i, columns in enumerate(df.columns.levels):
columns = columns.tolist()
for j, row in enumerate(columns):
if "Unnamed: " in row:
columns[j] = ""
df.columns.set_levels(columns, level=i, inplace=True)
return df
rename_unnamed(df1)
做得好。但是否有任何Pandas的方法可以从箱形图中实现这一点?