在计算机视觉和物体检测中,常见的评估方法是mAP。它是什么,如何计算?
6个回答
54
- Ankitp
3
2目标检测模型的最低 mAP 分数应该是多少? - Hamza
实际上存在一篇原始论文提出了mAP吗? - Jürgen K.
@JürgenK - 这是来自牛津大学Zisserman小组的原始论文,他们最初在2009年提出了PASCAL VOC。mAP的定义在第11页上。http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf - rayryeng
53
引文摘自上述Zisserman论文-4.2结果评估(第11页):
首先定义一个“重叠标准”,即交集比大于0.5。 (例如,如果预测框相对于地面实况框满足此标准,则视为检测)。然后使用这种“贪婪”方法在GT框和预测框之间进行匹配:
由方法输出的检测结果被分配给以置信度输出为排序条件的满足重叠标准的实况对象。 在图像中同一对象的多个检测结果被认为是误检,例如,单个对象的5个检测结果计为1次正确检测和4次误检
因此,每个预测框要么是真阳性,要么是假阳性。 每个实况框都是真阳性。 没有真阴性。
然后通过对精确率-召回率曲线上精确率值进行平均来计算平均精度,其中召回率在范围内[0、0.1、…,1] (例如,11个精度值的平均值)。 更精确地说,我们考虑了一个稍作修正的PR曲线,在该曲线点(p,r)处,如果存在不同的曲线点(p',r')使得p' > p且r' > = r,则将p替换为这些点中最大的p'。
对我来说仍然不清楚的是,对于那些从未检测到的GT框会发生什么情况(即使置信度为0)。 这意味着某些召回值永远无法到达精确率-召回率曲线,这使得上述平均精度计算未定义。
编辑:
简短回答:在召回率无法到达的区域,精确率下降至0。
解释这个问题的一种方式是假设当置信度阈值接近0时,无限数量的预测边界框在图像上随处点亮。此时,精确度立即降为0(因为只有有限数量的GT边界框),而召回率在这条平坦曲线上不断增长,直到达到100%。
- Jonathan
12
3还有其他不清楚的地方。考虑这样一种情况,有两个预测框(P1、P2)和两个真实框(T1、T2),其中P2的置信度比P1高。P1和P2都与T1重叠。由于P2的置信度更高,因此明显应该将P2视为与T1匹配的预测框。但未说明的是,如果P1也与T2有一些IOU重叠,但低于与T1的重叠,是否应给予P1“第二次机会”来尝试将其与T2匹配? - Martin
有人能澄清未检测到的GT盒子问题吗? - Jonathan
@Alex
你的情况下精度为[1, 0, 0.5, 0.666],对应的召回率为[0, 0, 0.333, 0.666]。然而,“修正后”的精度召回率图是:[1, 0.666, 0.666, 0.666],对应相同的召回率。“平均”精度是从这条曲线插值得到的11个精度值的平均值,分别在召回率[0, 0.1, .... 1.0]处进行插值。我们将精度0设置为无法达到的召回率大于0.666。因此,它是avg([1, 0.666, 0.666, 0.666, 0.666, 0.666, 0.666, 0, 0, 0, 0]) = 0.394。 - Jonathan
@Jonathan:如果有多个物体的预测怎么办?如果有4个物体的1个预测,会被算作1个tp和3个fp吗? - Alex
显示剩余7条评论
38
检测时,确定一个对象提议是否正确的常见方法是交集联合(IoU, IU)。它采用所提出的对象像素集合
A和真实对象像素集合B,并计算以下结果:
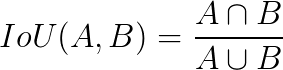
通常,IoU > 0.5 意味着命中,否则是失败的。对于每个类别,可以计算出:
- 真正例 TP(c):针对类别 c 进行了提议,而实际上存在一个类别为 c 的对象
- 假正例 FP(c):针对类别 c 进行了提议,但不存在类别为 c 的对象
- 类别 c 的平均精度:
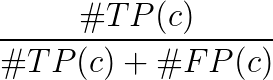
mAP(平均精度)是:

注意: 如果想要更好的建议,可以将IoU从0.5增加到更高的值(最高可达1.0,这将是完美的)。可以用mAP@p表示,其中p \in (0, 1)是IoU。
mAP@[.5:.95]表示mAP是通过多个阈值计算后再平均得出的。
编辑: 更详细的信息请参见COCO 评估指标。
- mrk
3
实际上,是否存在一篇提出mAP的原始论文?或者你是从哪里得到这个信息的? - Jürgen K.
1不确定COCO论文是否是原始来源,但至少在我看来,这篇论文目前设置了mAP的定义。您可以在我的帖子底部点击“评估指标”链接以获取更多信息。此外,这是有关COCO的论文https://arxiv.org/pdf/1405.0312.pdf,但他们没有花太多时间详细说明评估。尽管如此,他们提到了他们在此处提供的Python评估代码:https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py - mrk
谢谢@mrk,我有一个问题:模型为每个边界框生成置信度值。这个置信度值如何影响您上面解释的这些公式? - Francesco Taioli
10
我认为这里的重要部分是将物体检测与标准信息检索问题联系起来,为此至少存在一个优秀的平均精度描述。
某些物体检测算法的输出是一组提议的边界框,对于每个边界框,有置信度和分类分数(每类一个分数)。现在先忽略分类分数,使用置信度作为阈值二元分类的输入。从直觉上讲,平均精度是对于所有阈值/截止值选择的聚合。但是等等; 为了计算精度,我们需要知道边界框是否正确!
这是让人感到困惑/困难的地方;与典型的信息检索问题相反,我们实际上在这里有额外的分类级别。也就是说,我们不能在盒子之间进行精确匹配,因此我们需要分类判断边界框是否正确。解决方案是基本上对盒子尺寸进行硬编码分类; 我们检查它是否与任何基本事实足够重叠以被视为“正确”。这部分的阈值是由常识选择的。您正在处理的数据集可能会定义什么是“正确”边界框的阈值。大多数数据集只将其设置为0.5 IoU,并将其保留在那里(我建议做一些手动IoU计算[它们不难],以了解0.5 IoU实际上有多严格)。
现在我们已经定义了什么是“正确”的,我们可以使用与信息检索相同的过程来查找平均精度(mAP)。为此,您只需根据与这些框相关的分类分数的最大值对您提出的框进行分层,然后对类别上的平均精度(AP)取平均值(求平均)即可。简而言之,要区分边界框预测是否“正确”(额外的分类级别),以及评估框置信度如何通知您“正确”的边界框预测(与信息检索案例完全类似),并且典型的mAP描述将变得有意义。
值得注意的是,精确率/召回率曲线下面积就是平均精度,我们基本上是用梯形法则或右手法则来近似计算这个区域的积分。
- Multihunter
3
定义:mAP → 平均精度均值。
在大多数目标检测比赛中,有许多需要检测的类别。每次评估模型时,都是针对特定类别进行评估,其结果为该类别的AP。
当所有类别都被评估后,将所有AP的平均值计算出来作为模型的最终结果,即mAP。
- 刘洪宇
1
目标检测模型的最低 mAp 分数应该是多少? - Hamza
-2
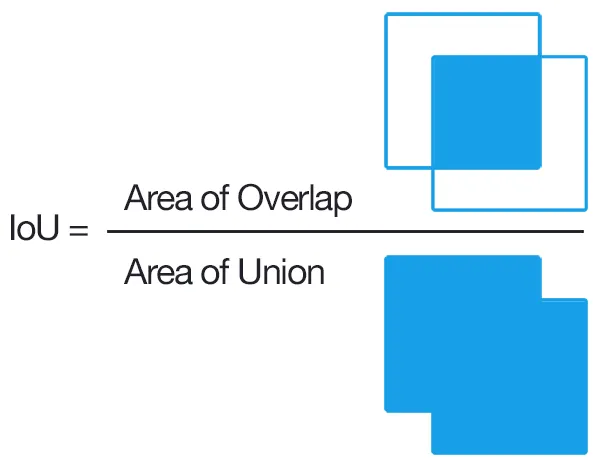
交并比(IOU)是一种基于Jaccard指数的度量方法,用于评估两个边界框之间的重叠。它需要一个真实的边界框和一个预测的边界框。通过应用IOU,我们可以判断检测结果是否有效(真正例)或无效(假正例)。IOU由预测边界框与真实边界框之间的重叠面积除以它们的并集面积得出。
- Harsh
1
这个问题是关于mAP而不是IoU的。因此,您至少应该澄清IoU如何与mAP相关。 - nbro
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接