我有以下数据框:
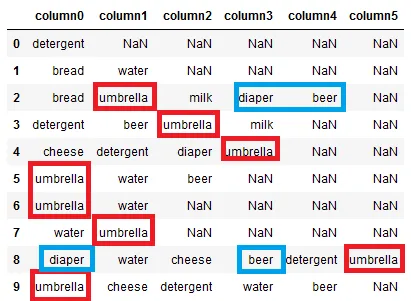
- 整个数据集中出现了8次伞
- 洗涤剂出现了5次
- (啤酒,尿布)出现了2次
- (啤酒,牛奶)出现了2次
- (伞,牛奶,啤酒)出现了2次
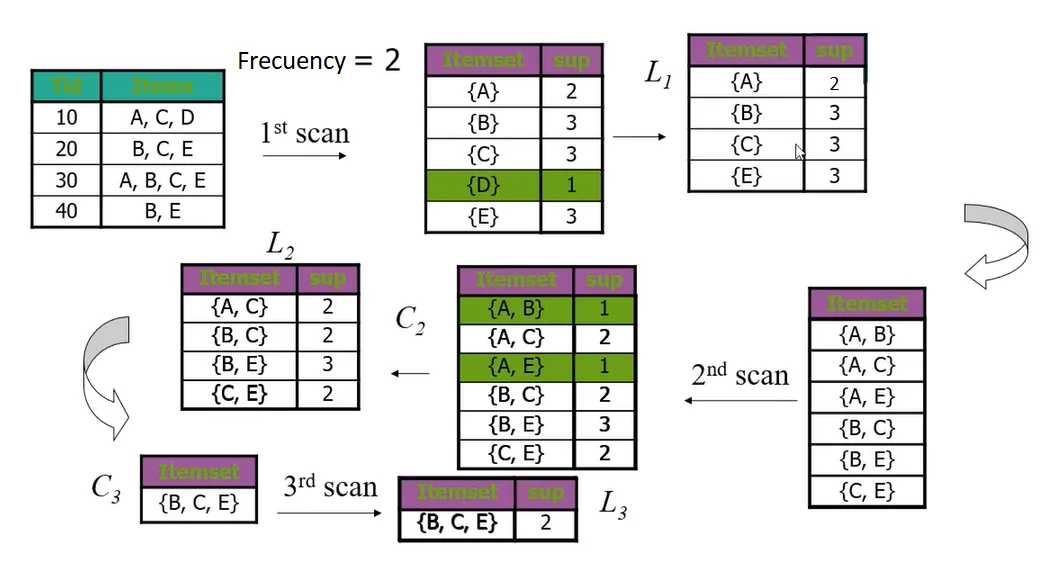 统计所有单个和组合项的频率,并仅保留那些频率>=n的单个和组合项,其中n是任何正整数。对于此示例,假设n->{1,2,3,4}。
统计所有单个和组合项的频率,并仅保留那些频率>=n的单个和组合项,其中n是任何正整数。对于此示例,假设n->{1,2,3,4}。我一直在尝试使用以下代码:
# candidates itemsets
records = []
# generates a list of lists of products that were bought together (convert df to list of lists)
for i in range(0, num_records):
records.append([str(data.values[i,j]) for j in range(0, len(data.columns))])
# clean list (delete NaN values)
records = [[x for x in y if str(x) != 'nan'] for y in records]
OUTPUT:
[['detergent'],
['bread', 'water'],
['bread', 'umbrella', 'milk', 'diaper', 'beer'],
['detergent', 'beer', 'umbrella', 'milk'],
['cheese', 'detergent', 'diaper', 'umbrella'],
['umbrella', 'water', 'beer'],
['umbrella', 'water'],
['water', 'umbrella'],
['diaper', 'water', 'cheese', 'beer', 'detergent', 'umbrella'],
['umbrella', 'cheese', 'detergent', 'water', 'beer']]
然后:
setOfItems = []
newListOfItems = []
for item in records:
if item in setOfItems:
continue
setOfItems.append(item)
temp = list(item)
occurence = records.count(item)
temp.append(occurence)
newListOfItems.append(temp)
OUTPUT:
['detergent', 1]
['bread', 'water', 1]
['bread', 'umbrella', 'milk', 'diaper', 'beer', 1]
['detergent', 'beer', 'umbrella', 'milk', 1]
['cheese', 'detergent', 'diaper', 'umbrella', 1]
['umbrella', 'water', 'beer', 1]
['umbrella', 'water', 1]
['water', 'umbrella', 1]
['diaper', 'water', 'cheese', 'beer', 'detergent', 'umbrella', 1]
['umbrella', 'cheese', 'detergent', 'water', 'beer', 1]
正如您所看到的,它只计算整行(来自图像1)的频率,然而我的期望输出是出现在第二个图像中的输出。
item是一个条目列表而不是单个的条目,你可能需要使用两个for循环。先尝试将其正确运行在一个元素上,然后再逐步增加到更高层次。 - Shaido