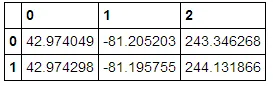
我想要做的是从谷歌地图API中提取沿着由纬度和经度坐标指定的路径的高程数据,如下所示:
这给我提供了一个类似于以下的数据:
from urllib2 import Request, urlopen
import json
path1 = '42.974049,-81.205203|42.974298,-81.195755'
request=Request('http://maps.googleapis.com/maps/api/elevation/json?locations='+path1+'&sensor=false')
response = urlopen(request)
elevations = response.read()
这给我提供了一个类似于以下的数据:
elevations.splitlines()
['{',
' "results" : [',
' {',
' "elevation" : 243.3462677001953,',
' "location" : {',
' "lat" : 42.974049,',
' "lng" : -81.205203',
' },',
' "resolution" : 19.08790397644043',
' },',
' {',
' "elevation" : 244.1318664550781,',
' "location" : {',
' "lat" : 42.974298,',
' "lng" : -81.19575500000001',
' },',
' "resolution" : 19.08790397644043',
' }',
' ],',
' "status" : "OK"',
'}']
当将其放入DataFrame中时,我得到以下内容:

pd.read_json(elevations)
以下是我想要的内容:
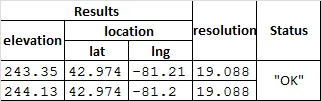
我不确定是否可行,但主要是想找一种将高程、纬度和经度数据放入pandas dataframe中的方法(不需要花哨的多行标题)。
如果有人能提供帮助或关于处理这些数据的建议,那就太好了!如果你还没看出来,我之前并没有接触过json数据...
编辑:
这种方法并不太吸引人,但似乎很有效:
data = json.loads(elevations)
lat,lng,el = [],[],[]
for result in data['results']:
lat.append(result[u'location'][u'lat'])
lng.append(result[u'location'][u'lng'])
el.append(result[u'elevation'])
df = pd.DataFrame([lat,lng,el]).T
最终得到的数据框将具有纬度、经度和海拔列。