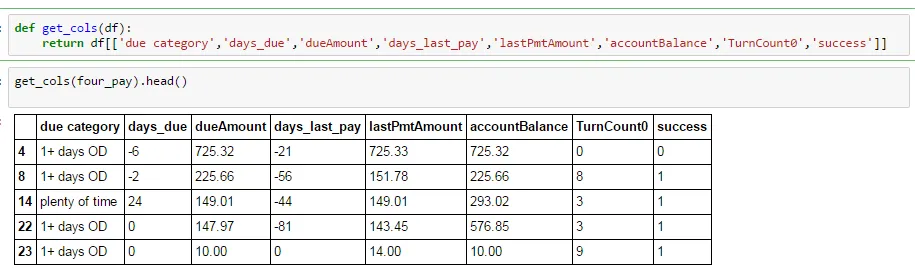
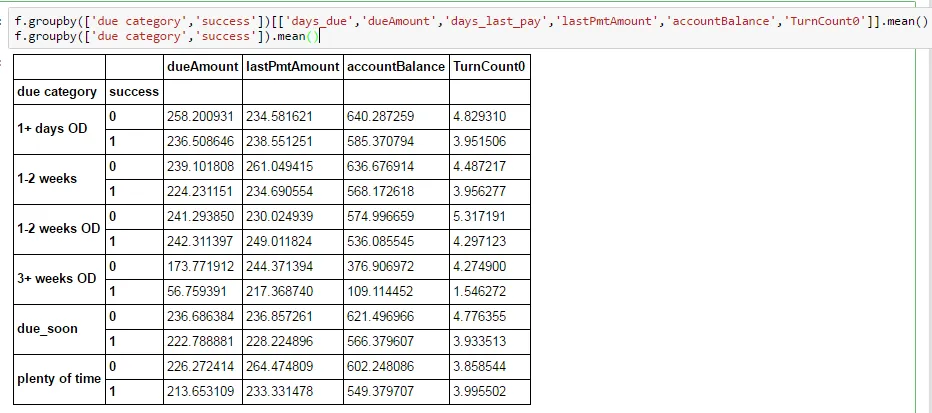
我正在进行一个简单的分组操作,试图比较分组均值。如下所示,我从一个较大的数据框中选择了特定的列,其中所有缺失值都已被删除。
我在使用pandas时从未遇到过这种情况,而且在stackoverflow上也没有找到类似的解决方案。有人能提供一些见解吗?
我在使用pandas时从未遇到过这种情况,而且在stackoverflow上也没有找到类似的解决方案。有人能提供一些见解吗?
我认为这是'nuisance'列的自动排除,在这里进行了描述。
示例:
df = pd.DataFrame({'C': {0: -0.91985400000000006, 1: -0.042379, 2: 1.2476419999999999, 3: -0.00992, 4: 0.290213, 5: 0.49576700000000001, 6: 0.36294899999999997, 7: 1.548106}, 'A': {0: 'foo', 1: 'bar', 2: 'foo', 3: 'bar', 4: 'foo', 5: 'bar', 6: 'foo', 7: 'foo'}, 'B': {0: 'one', 1: 'one', 2: 'two', 3: 'three', 4: 'two', 5: 'two', 6: 'one', 7: 'three'}, 'D': {0: -1.131345, 1: -0.089328999999999992, 2: 0.33786300000000002, 3: -0.94586700000000001, 4: -0.93213199999999996, 5: 1.9560299999999999, 6: 0.017587000000000002, 7: -0.016691999999999999}})
print (df)
A B C D
0 foo one -0.919854 -1.131345
1 bar one -0.042379 -0.089329
2 foo two 1.247642 0.337863
3 bar three -0.009920 -0.945867
4 foo two 0.290213 -0.932132
5 bar two 0.495767 1.956030
6 foo one 0.362949 0.017587
7 foo three 1.548106 -0.016692
print( df.groupby('A').mean())
C D
A
bar 0.147823 0.306945
foo 0.505811 -0.344944
我认为你可以查看DataFrame.dtypes。
df.groupby(['col_1','col_2'],as_index=False).mean()。
使用as_index=False保留列名。默认为True。上面的评论已经回答了这个问题,但将其发布为答案。df.column.dtypes
df.dtypes。 - Foggy
df.groupby('A', as_index=False).mean()或者df.groupby('A').mean().reset_index()哪一个更好? - jezraeldf.mycols.fillna('')、分组,然后df.problem_col.replace('^;|;$','')。 - Sosobject类型的列上执行数值分组操作。您可以使用DataFrame.dtypes检查列的数据类型。从 SQL 数据库提取数据时,有时空值会作为None存在,因此您需要使用df.fillna(np.nan)或等效代码将None值替换为np.nan。 - Foggy