我正在尝试获取numpy数组中所有重复元素的索引,但我目前找到的解决方案对于大型(>20000个元素)输入数组非常低效(需要大约9秒钟)。这里的思路很简单:
records_array是一个包含时间戳(datetime)的numpy数组,我们想要提取出其中重复时间戳的索引。time_array是一个numpy数组,包含在records_array中重复的所有时间戳。records是一个django QuerySet(可以轻松转换为列表),其中包含一些Record对象。我们想要创建一个由所有可能的Record的tagId属性组成的二元组列表,这些属性对应于从records_array中发现的重复时间戳。
tag_couples = [];
for t in time_array:
users_inter = np.nonzero(records_array == t)[0] # Get all repeated timestamps in records_array for time t
l = [str(records[i].tagId) for i in users_inter] # Create a temporary list containing all tagIds recorded at time t
if l.count(l[0]) != len(l): #remove tuples formed by the first tag repeated
tag_couples +=[x for x in itertools.combinations(list(set(l)),2)] # Remove duplicates with list(set(l)) and append all possible couple combinations to tag_couples
我相信可以通过使用Numpy进行优化,但是我找不到一种方法来比较records_array和time_array中的每个元素而不使用for循环(不能只使用==比较,因为它们都是数组)。
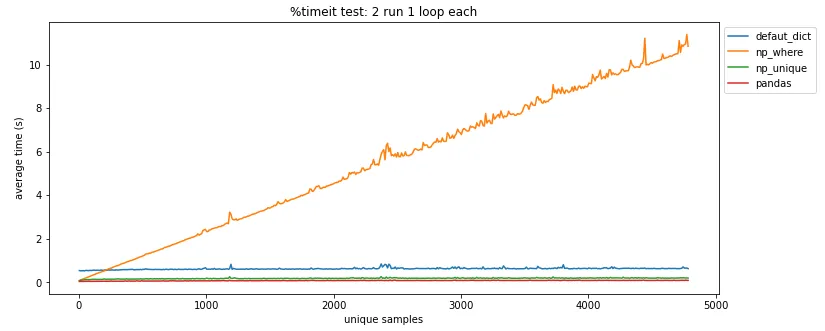
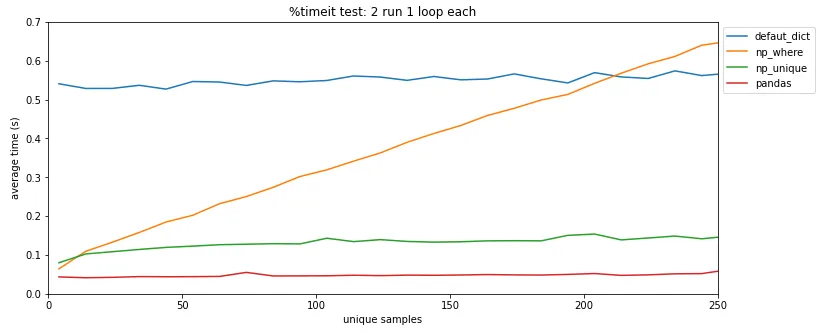
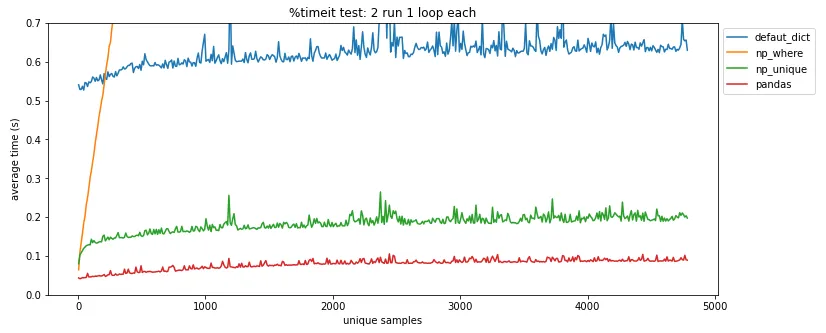
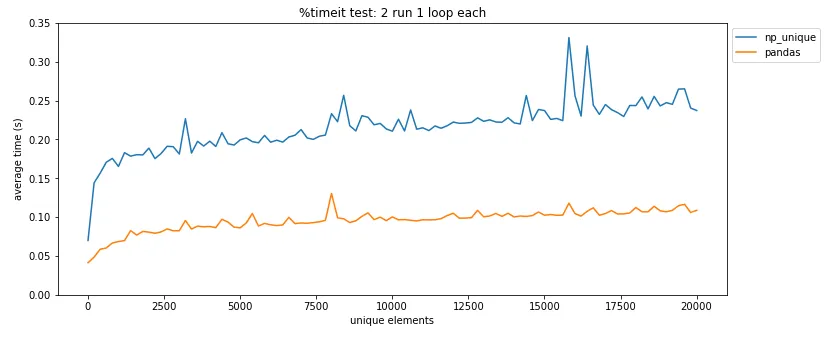
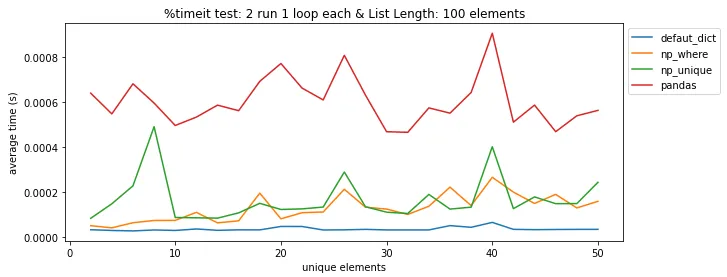
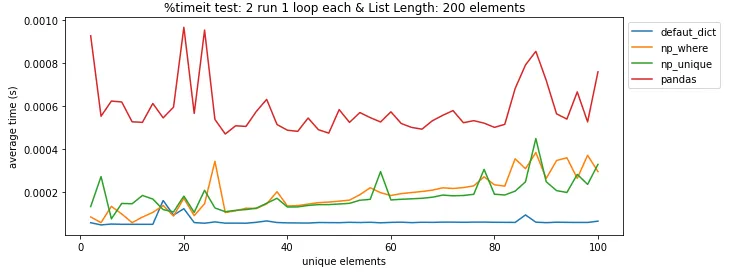
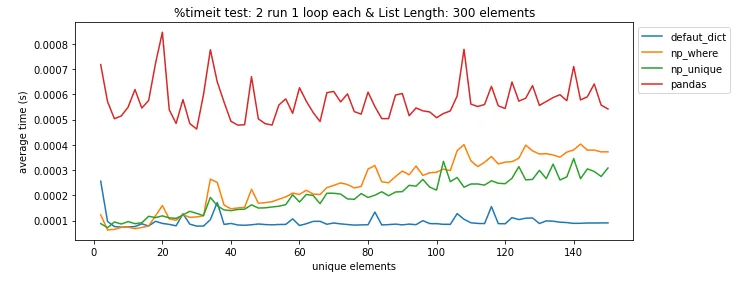
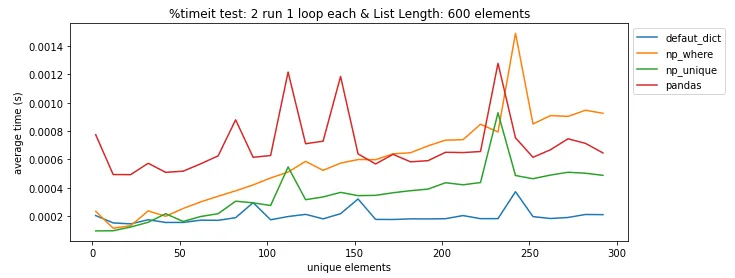
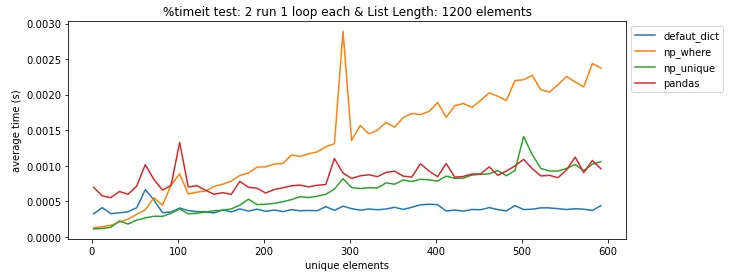
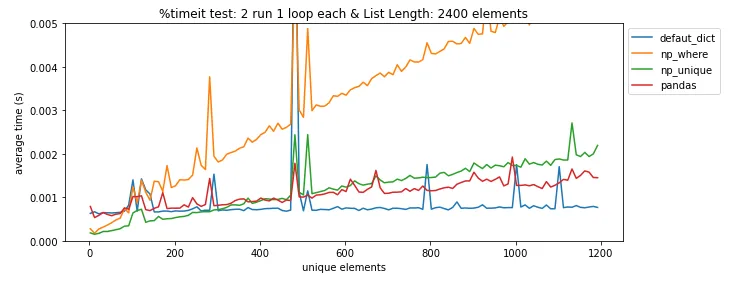
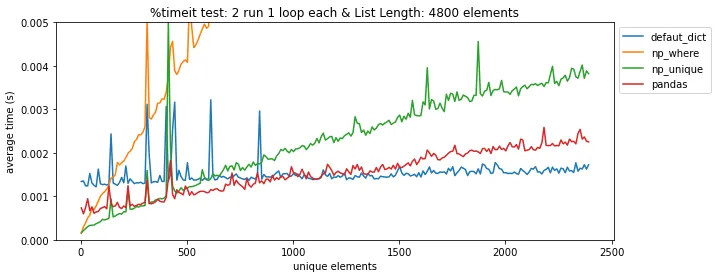
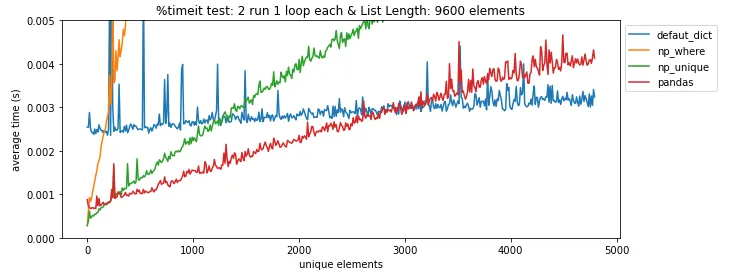
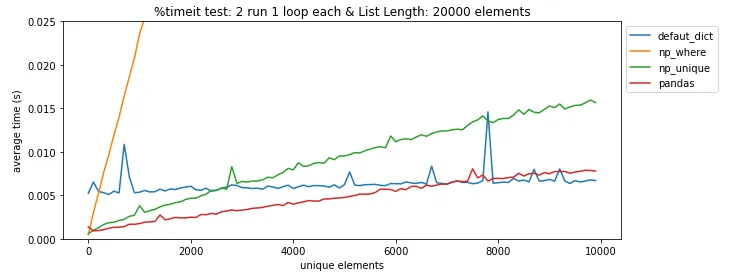
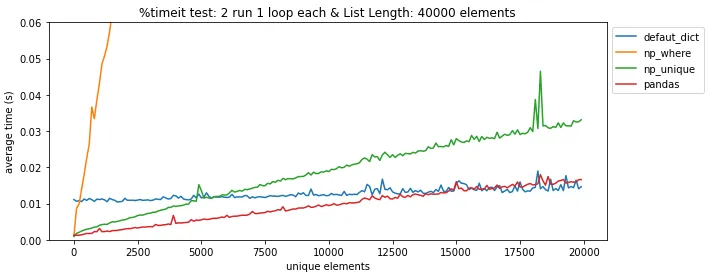
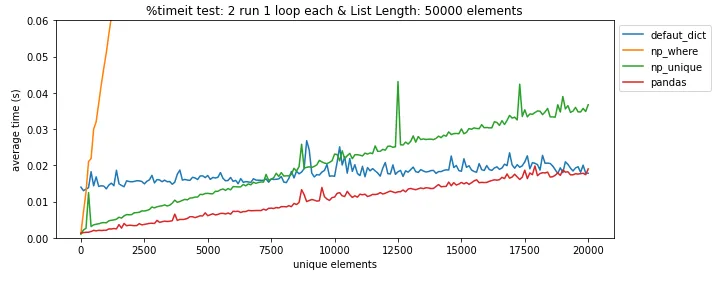
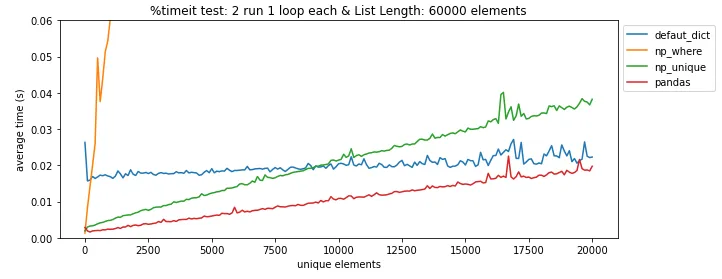
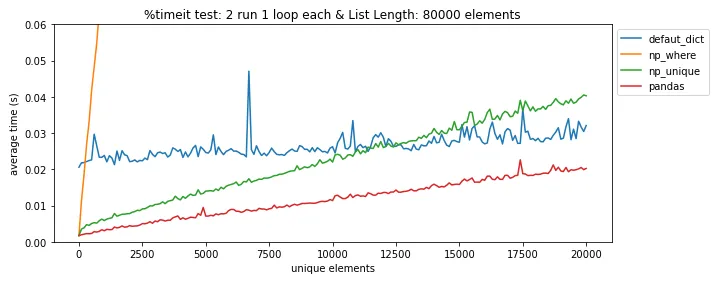
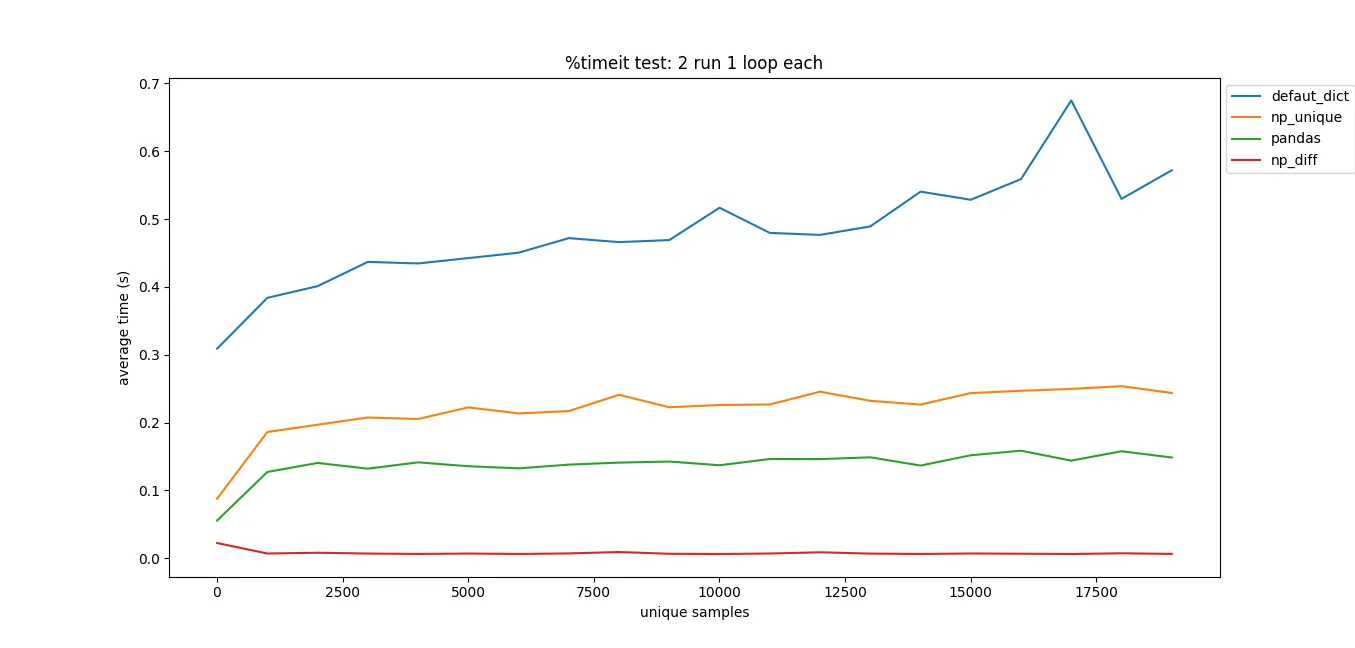
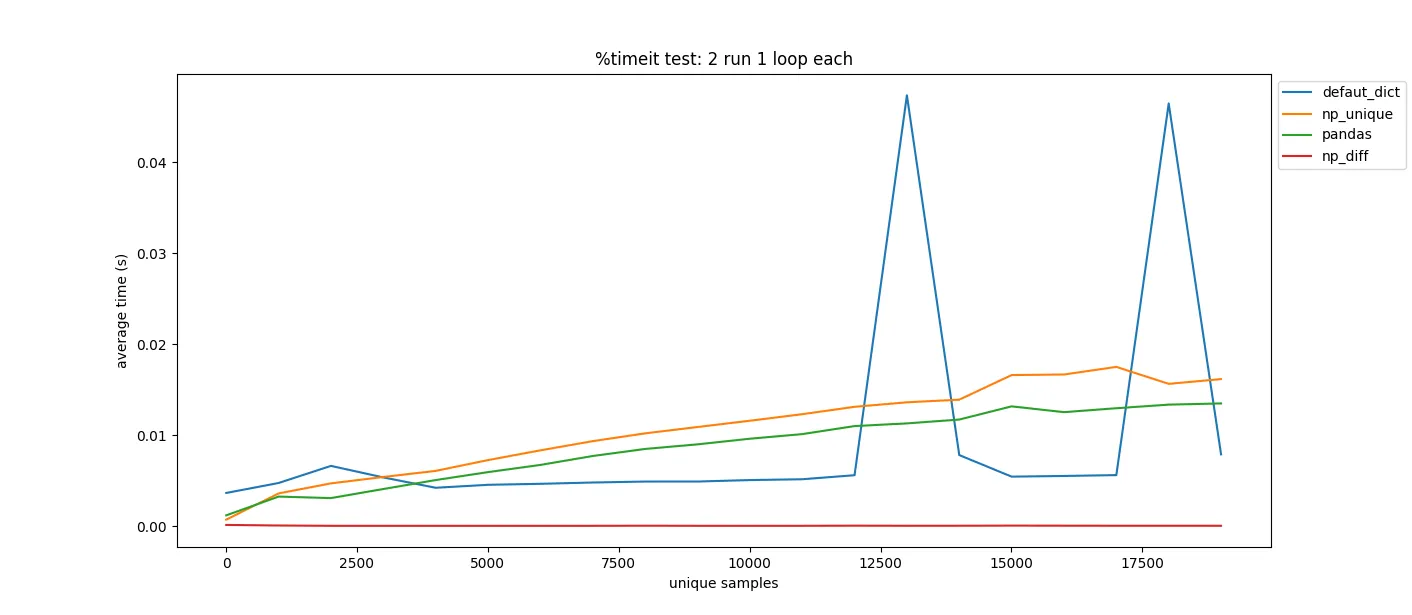
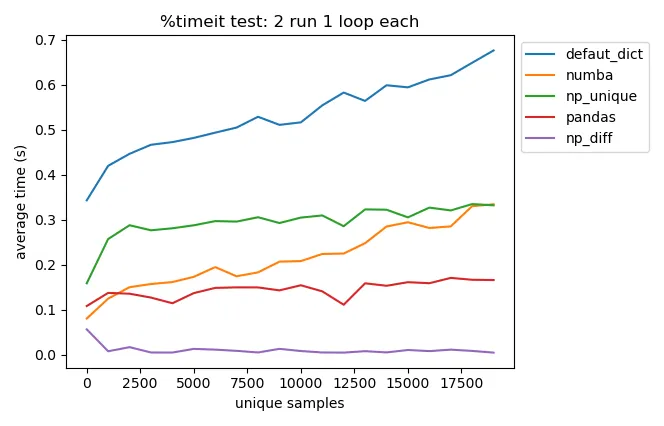
pandas.DataFrame.drop_duplicates()可以帮你省去自己查找重复项的麻烦。 - undefined