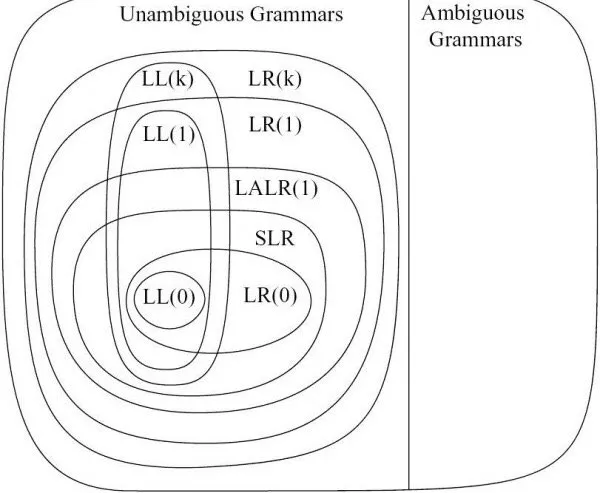
在上面的答案基础上,底部向上LR解析器类中各个解析器之间的区别在于它们生成解析表时是否会产生移位/规约或规约/规约冲突。冲突越少,语法就越强大(LR(0) < SLR(1) < LALR(1) < CLR(1))。
例如,考虑以下表达式语法:
E → E + T
E → T
T → F
T → T * F
F → ( E )
F → id
它不是LR(0),但是是SLR(1)。使用以下代码,我们可以构建LR0自动机并构建解析表(我们需要扩充语法,计算具有闭包的DFA,计算操作和转移集):
from copy import deepcopy
import pandas as pd
def update_items(I, C):
if len(I) == 0:
return C
for nt in C:
Int = I.get(nt, [])
for r in C.get(nt, []):
if not r in Int:
Int.append(r)
I[nt] = Int
return I
def compute_action_goto(I, I0, sym, NTs):
I1 = {}
for NT in I:
C = {}
for r in I[NT]:
r = r.copy()
ix = r.index('.')
if ix >= len(r)-1 or r[ix+1] != sym:
continue
r[ix:ix+2] = r[ix:ix+2][::-1]
C = compute_closure(r, I0, NTs)
cnt = C.get(NT, [])
if not r in cnt:
cnt.append(r)
C[NT] = cnt
I1 = update_items(I1, C)
return I1
def construct_LR0_automaton(G, NTs, Ts):
I0 = get_start_state(G, NTs, Ts)
I = deepcopy(I0)
queue = [0]
states2items = {0: I}
items2states = {str(to_str(I)):0}
parse_table = {}
cur = 0
while len(queue) > 0:
id = queue.pop(0)
I = states[id]
for NT in NTs:
I1 = compute_action_goto(I, I0, NT, NTs)
if len(I1) > 0:
state = str(to_str(I1))
if not state in statess:
cur += 1
queue.append(cur)
states2items[cur] = I1
items2states[state] = cur
parse_table[id, NT] = cur
else:
parse_table[id, NT] = items2states[state]
return states2items, items2states, parse_table
states, statess, parse_table = construct_LR0_automaton(G, NTs, Ts)
其中文法G、非终结符和终结符符号定义如下
G = {}
NTs = ['E', 'T', 'F']
Ts = {'+', '*', '(', ')', 'id'}
G['E'] = [['E', '+', 'T'], ['T']]
G['T'] = [['T', '*', 'F'], ['F']]
G['F'] = [['(', 'E', ')'], ['id']]
这里还有几个我为LR(0)语法分析表生成实现的有用函数:
def augment(G, S):
G[S + '1'] = [[S, '$']]
NTs.append(S + '1')
return G, NTs
def compute_closure(r, G, NTs):
S = {}
queue = [r]
seen = []
while len(queue) > 0:
r = queue.pop(0)
seen.append(r)
ix = r.index('.') + 1
if ix < len(r) and r[ix] in NTs:
S[r[ix]] = G[r[ix]]
for rr in G[r[ix]]:
if not rr in seen:
queue.append(rr)
return S
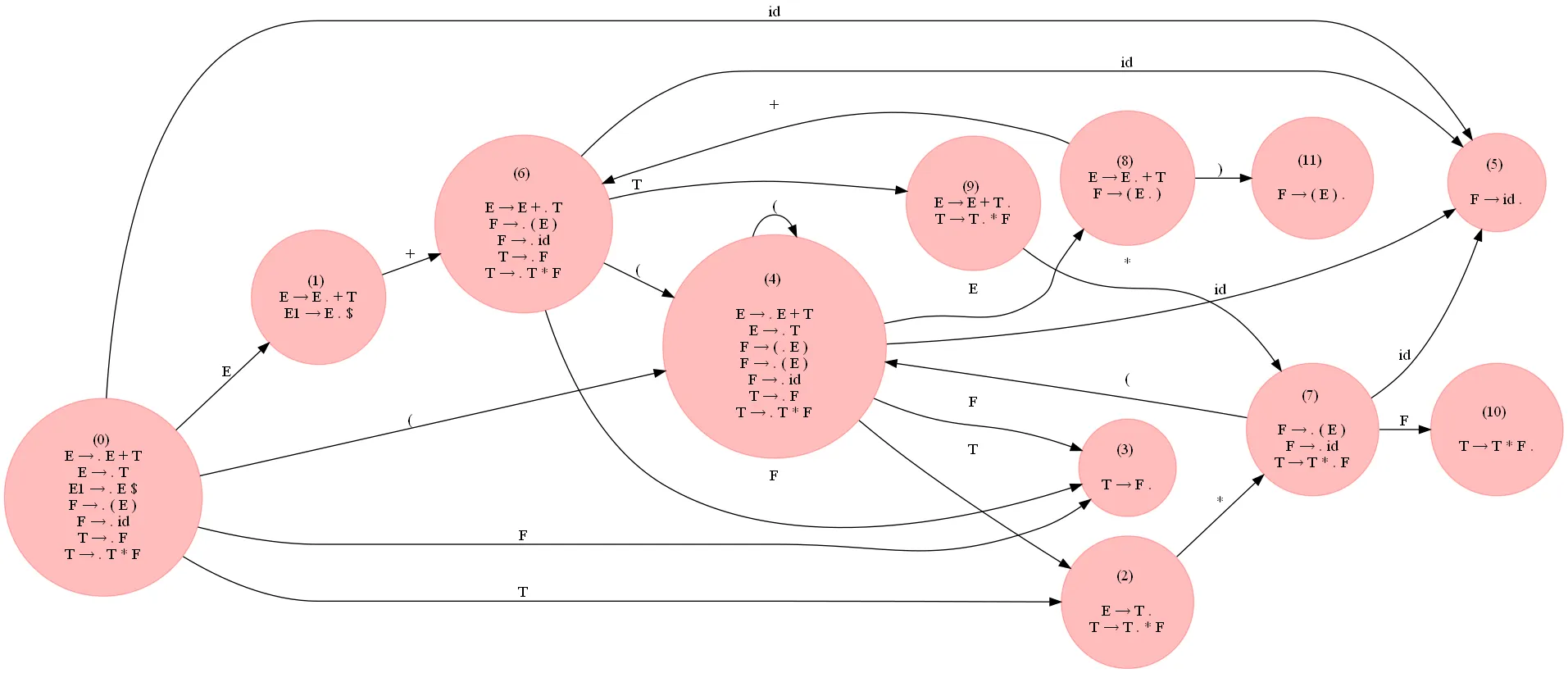
下图(展开查看)显示了使用上述代码构建的语法LR0 DFA:
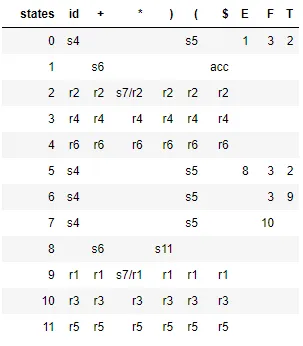
下表显示了作为Pandas数据帧生成的LR(0)分析表,注意到有一些移进/规约冲突,这表明语法不是LR(0)。
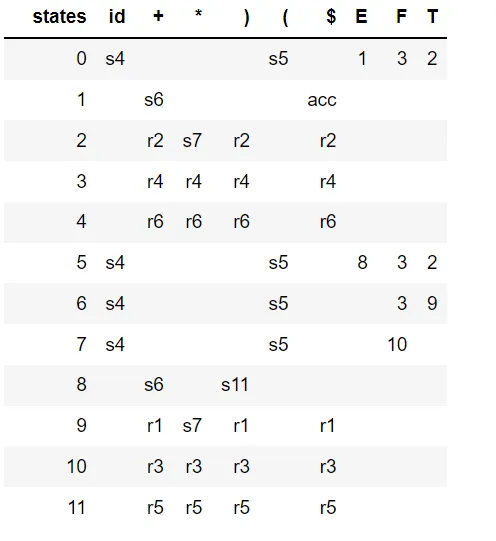
SLR(1)解析器通过仅在下一个输入标记是被规约的非终结符的Follow集成员时才进行规约,从而避免了上述的移位/规约冲突。以下解析表由SLR生成:
以下动画展示了如何使用上述SLR(1)语法解析输入表达式:

问题中的语法也不是LR(0):
G = {}
NTs = ['S', 'A']
Ts = {'a', 'b', 'c', 'd'}
G['S'] = [['A', 'a'], ['b', 'A', 'c'], ['d', 'c'], ['b', 'd', 'a']]
G['A'] = [['d']]
从下一个LR0 DFA和解析表中可以看出:
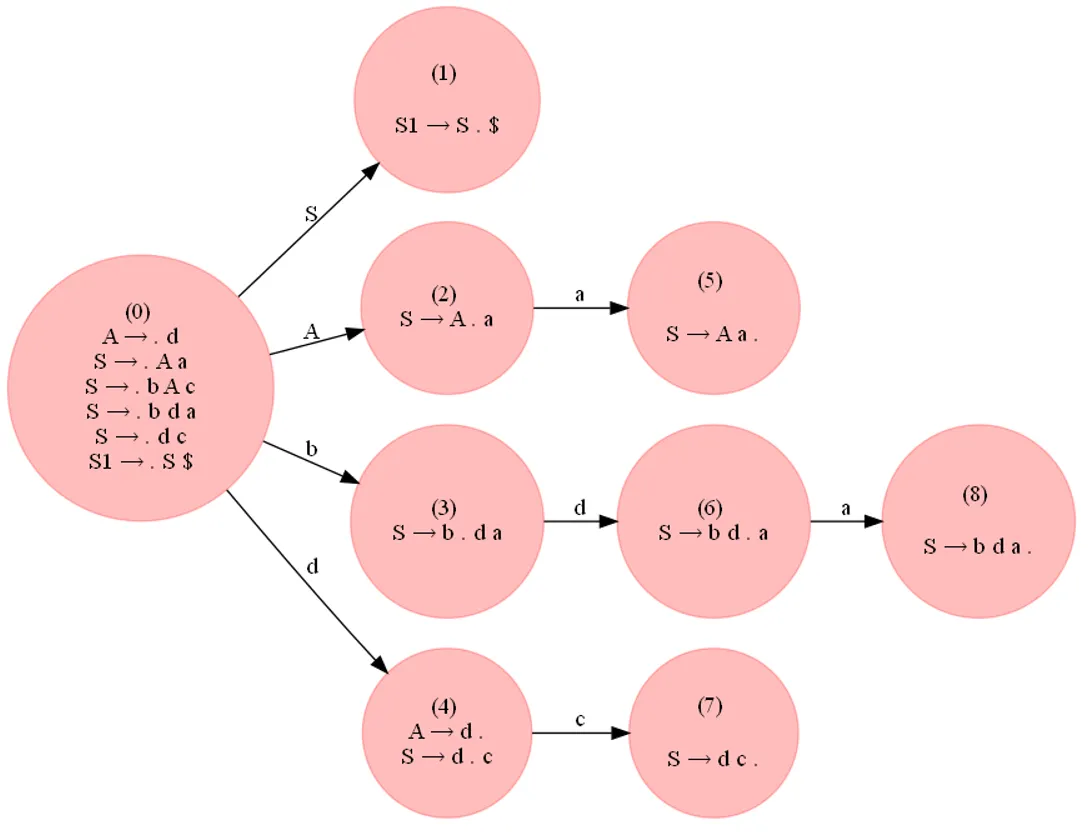
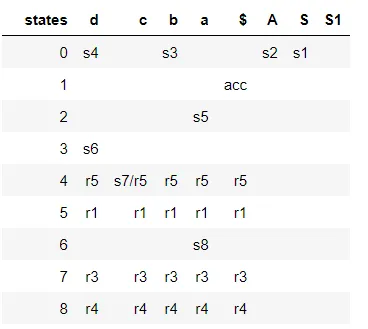
又出现了一次移位/规约冲突:
但是,接受形式为a^ncb^n,n≥1的字符串的以下语法是LR(0):
A → a A b
A → c
S → A
G = {}
NTs = ['S', 'A']
Ts = {'a', 'b', 'c'}
G['S'] = [['A']]
G['A'] = [['a', 'A', 'b'], ['c']]
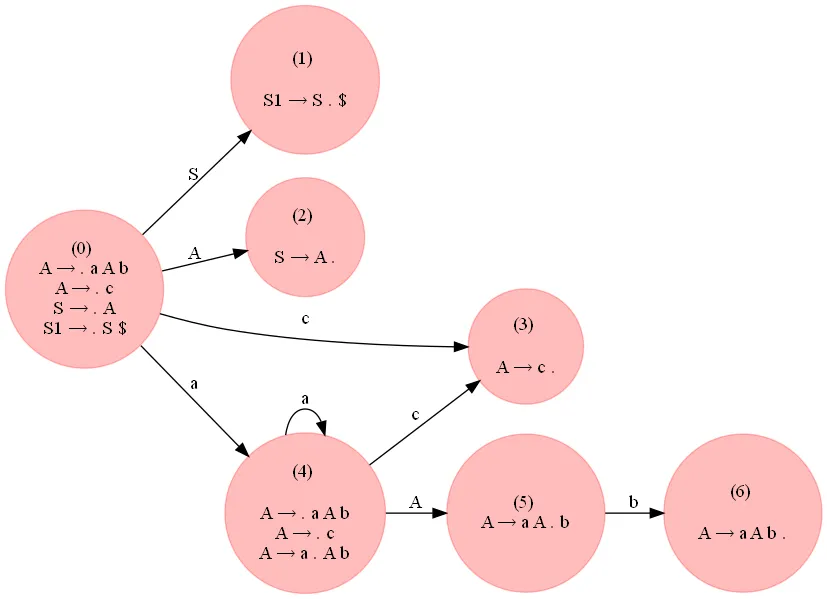
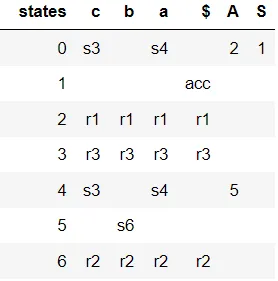
从下图可以看出,生成的分析表中没有冲突。
这是如何使用上述 LR(0) 解析表,使用以下代码解析输入字符串
a^2cb^2 的方法:
def parse(input, parse_table, rules):
input = 'aaacbbb$'
stack = [0]
df = pd.DataFrame(columns=['stack', 'input', 'action'])
i, accepted = 0, False
while i < len(input):
state = stack[-1]
char = input[i]
action = parse_table.loc[parse_table.states == state, char].values[0]
if action[0] == 's':
stack.append(char)
stack.append(int(action[-1]))
i += 1
elif action[0] == 'r':
r = rules[int(action[-1])]
l, r = r['l'], r['r']
char = ''
for j in range(2*len(r)):
s = stack.pop()
if type(s) != int:
char = s + char
if char == r:
goto = parse_table.loc[parse_table.states == stack[-1], l].values[0]
stack.append(l)
stack.append(int(goto[-1]))
elif action == 'acc':
accepted = True
df2 = {'stack': ''.join(map(str, stack)), 'input': input[i:], 'action': action}
df = df.append(df2, ignore_index = True)
if accepted:
break
return df
parse(input, parse_table, rules)
下一个动画展示了如何使用上述代码,使用LR(0)解析器解析输入字符串
a^2cb^2: