我正在学习编译器的概念,但是有些困惑......通过谷歌搜索也没有得到明确的答案。
SLR和LR(0)解析器是否相同?如果不同,有什么区别?
我正在学习编译器的概念,但是有些困惑......通过谷歌搜索也没有得到明确的答案。
SLR和LR(0)解析器是否相同?如果不同,有什么区别?
最近,一种名为GLR(0)(“广义LR(0)”)的新解析算法变得越来越受欢迎。与尝试解决LR(0)解析器中出现的冲突不同,GLR(0)解析器通过并行尝试所有可能的选项来工作。使用一些聪明的技巧,这可以使许多语法非常高效地运行。此外,GLR(0)可以解析任何上下文无关文法,即使是任何k的LR(k)解析器也无法解析的文法。其他解析器也能够做到这一点(例如Earley解析器或CYK解析器),但在实践中GLR(0)往往更快。
如果您有兴趣了解更多信息,去年夏天我教授了一门入门级编译器课程,并花了将近两个星期讨论解析技术。如果您想要更严格的LR(0)、SLR(1)和其他强大的解析技术介绍,您可能会喜欢我的关于解析的演讲幻灯片和作业。所有课程材料都可以在我的个人网站上找到。
from copy import deepcopy
import pandas as pd
def update_items(I, C):
if len(I) == 0:
return C
for nt in C:
Int = I.get(nt, [])
for r in C.get(nt, []):
if not r in Int:
Int.append(r)
I[nt] = Int
return I
def compute_action_goto(I, I0, sym, NTs):
#I0 = deepcopy(I0)
I1 = {}
for NT in I:
C = {}
for r in I[NT]:
r = r.copy()
ix = r.index('.')
#if ix == len(r)-1: # reduce step
if ix >= len(r)-1 or r[ix+1] != sym:
continue
r[ix:ix+2] = r[ix:ix+2][::-1] # read the next symbol sym
C = compute_closure(r, I0, NTs)
cnt = C.get(NT, [])
if not r in cnt:
cnt.append(r)
C[NT] = cnt
I1 = update_items(I1, C)
return I1
def construct_LR0_automaton(G, NTs, Ts):
I0 = get_start_state(G, NTs, Ts)
I = deepcopy(I0)
queue = [0]
states2items = {0: I}
items2states = {str(to_str(I)):0}
parse_table = {}
cur = 0
while len(queue) > 0:
id = queue.pop(0)
I = states[id]
# compute goto set for non-terminals
for NT in NTs:
I1 = compute_action_goto(I, I0, NT, NTs)
if len(I1) > 0:
state = str(to_str(I1))
if not state in statess:
cur += 1
queue.append(cur)
states2items[cur] = I1
items2states[state] = cur
parse_table[id, NT] = cur
else:
parse_table[id, NT] = items2states[state]
# compute actions for terminals similarly
# ... ... ...
return states2items, items2states, parse_table
states, statess, parse_table = construct_LR0_automaton(G, NTs, Ts)
G = {}
NTs = ['E', 'T', 'F']
Ts = {'+', '*', '(', ')', 'id'}
G['E'] = [['E', '+', 'T'], ['T']]
G['T'] = [['T', '*', 'F'], ['F']]
G['F'] = [['(', 'E', ')'], ['id']]
def augment(G, S): # start symbol S
G[S + '1'] = [[S, '$']]
NTs.append(S + '1')
return G, NTs
def compute_closure(r, G, NTs):
S = {}
queue = [r]
seen = []
while len(queue) > 0:
r = queue.pop(0)
seen.append(r)
ix = r.index('.') + 1
if ix < len(r) and r[ix] in NTs:
S[r[ix]] = G[r[ix]]
for rr in G[r[ix]]:
if not rr in seen:
queue.append(rr)
return S
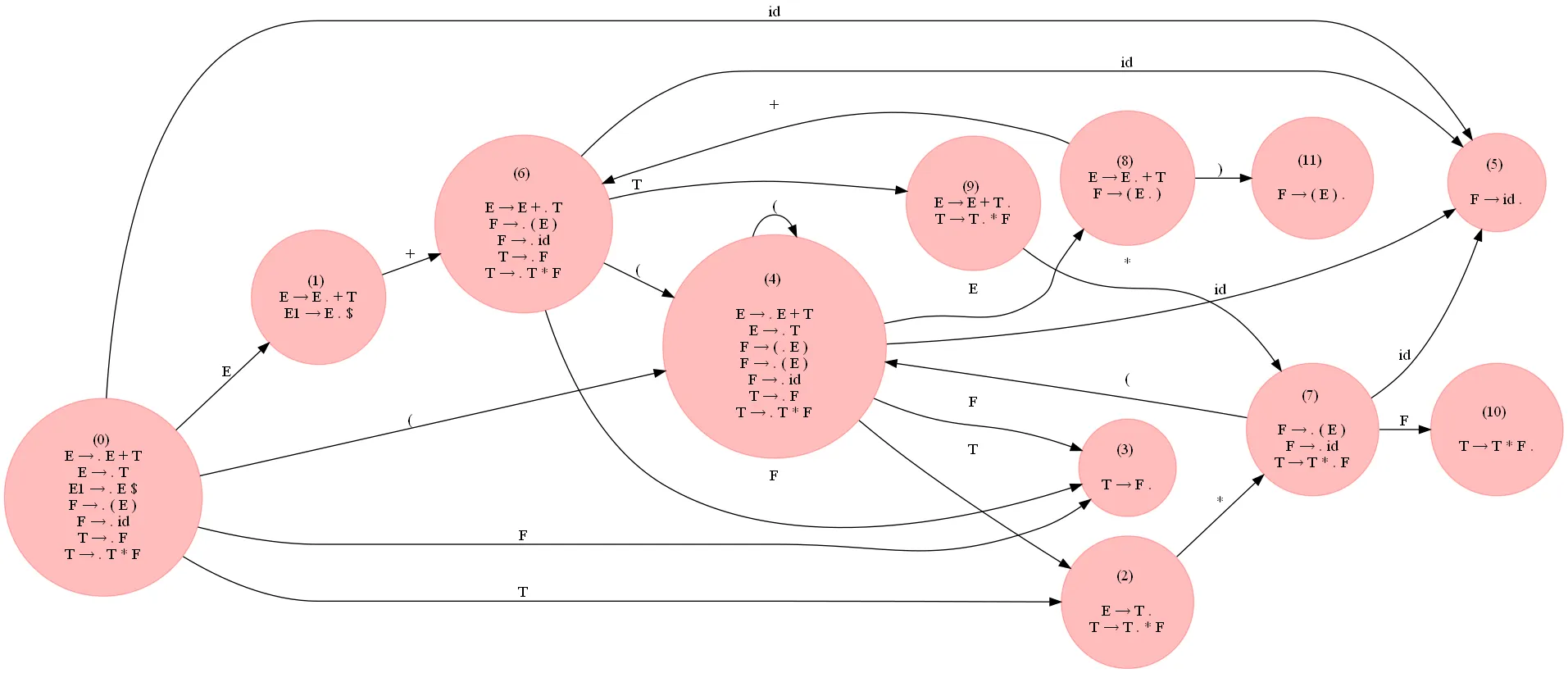
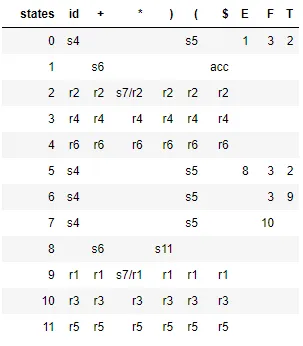
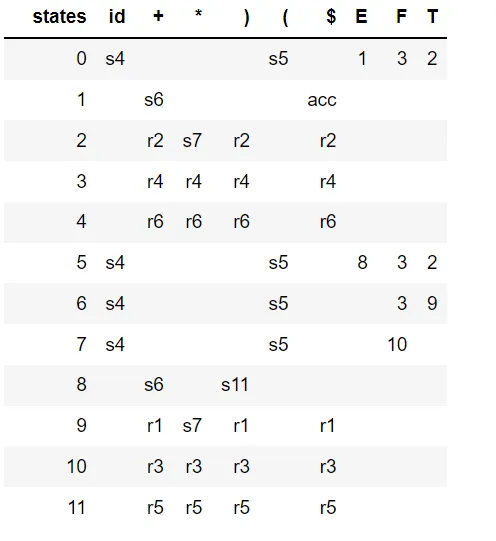

a^ncb^n,n≥1的字符串的以下语法是LR(0):# S --> A
# A --> a A b | c
G = {}
NTs = ['S', 'A']
Ts = {'a', 'b', 'c'}
G['S'] = [['A']]
G['A'] = [['a', 'A', 'b'], ['c']]
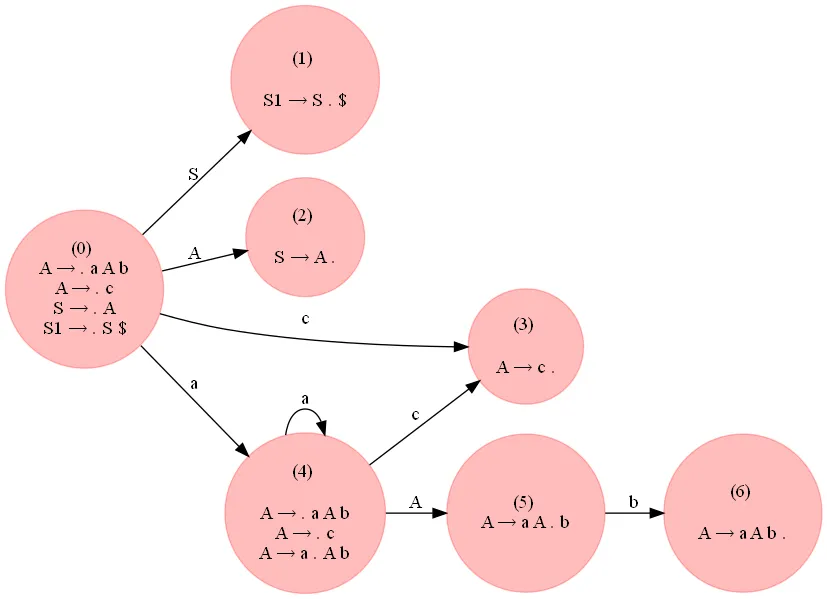
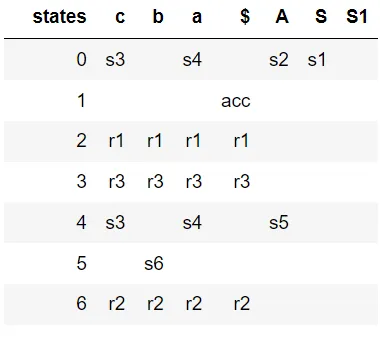
以下是我学到的内容。通常LR(0)分析器可能存在歧义,即表格中的一个框可以有多个值(或者更好地说:该分析器导致具有相同输入的两个最终状态)。因此创建SLR分析器以消除这种歧义。为了构建它,请找出所有导致转移状态的产生式,找出左侧产生式符号的Follow集,并仅包括那些在Follow集中出现过的转移状态。这反过来意味着您不会包括使用原始语法不可能的产生式(因为该状态不在Follow集中)。