df = pd.DataFrame(dict(
list(
zip(["A", "B", "C"],
[np.array(["id %02d" % i for i in range(1, 11)]).repeat(10),
pd.date_range("2018-01-01", periods=100).strftime("%Y-%m-%d"),
[i for i in range(10, 110)]])
)
))
df = df.groupby(["A", "B"]).sum()
df["D"] = df["C"].shift(1).rolling(2).mean()
df
这段代码会生成以下内容:
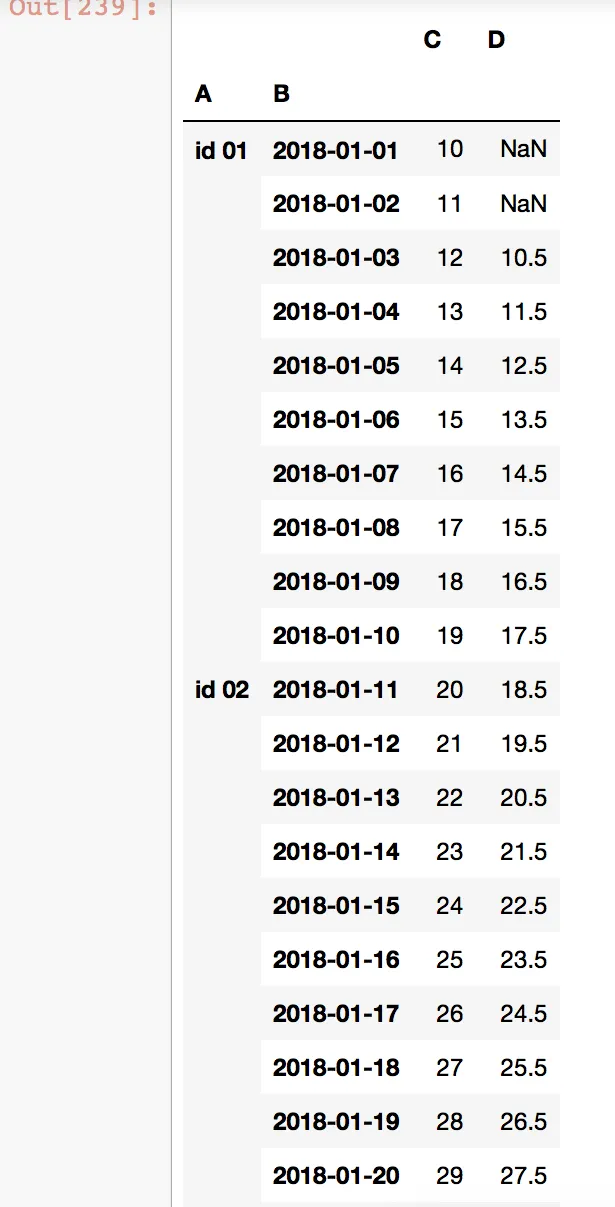
ID 02使用了ID 01的最后两个值来计算平均值。如何实现这一点?
group_keys=False参数,它仍然可以工作。我真的需要这个吗? - Nilzone-