我正在尝试找到一种通用的方法,从一个扁平的 Pandas DataFrame 实例创建(可能是深层的)嵌套字典。
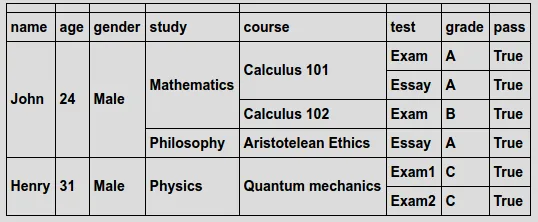
假设我有以下的DataFrame:
dat = pd.DataFrame({'name' : ['John', 'John', 'John', 'John', 'Henry', 'Henry'],
'age' : [24, 24, 24, 24, 31, 31],
'gender' : ['Male','Male','Male','Male','Male','Male'],
'study' : ['Mathematics', 'Mathematics', 'Mathematics', 'Philosophy', 'Physics', 'Physics'],
'course' : ['Calculus 101', 'Calculus 101', 'Calculus 102', 'Aristotelean Ethics', 'Quantum mechanics', 'Quantum mechanics'],
'test' : ['Exam', 'Essay','Exam','Essay', 'Exam1','Exam2'],
'pass' : [True, True, True, True, True, True],
'grade' : ['A', 'A', 'B', 'A', 'C', 'C']})
dat = dat[['name', 'age', 'gender', 'study', 'course', 'test', 'grade', 'pass']] #re-order columns to better reflect data structure
我想创建一个深度嵌套的字典(或嵌套字典列表),以“尊重”数据的基础结构。也就是说,成绩是关于测试的信息,而测试又是课程的一部分,课程又是研究的一部分,而这些研究是人所做的。此外,年龄和性别是有关同一人的信息。
一个期望的输出示例如下:
[{'John': {'age': 24,
'gender': 'Male',
'study': {'Mathematics': {'Calculus 101': {'Exam': {'grade': 'B',
'pass': True}}},
'Philosophy': {'Aristotelean Ethics': {'Essay': {'grade': 'A',
'pass': True}}}}}},
{'Henry': {'age': 31,
'gender': 'Male',
'study': {'Physics': {'Quantum mechanics': {'Exam1': {'Grade': 'C',
'Pass': True},
'Exam2': {'Grade': 'C',
'Pass': True}}}}}}]
(虽然可能有其他类似的方法来组织这样的数据)。
我尝试使用groupby,例如将'grade'和'pass'嵌套在'test'下面,将'test'嵌套在'course'下面,将'course'嵌套在'study'下面,将'study'嵌套在'name'下面,这样很容易实现。但是,我不知道如何将'gender'和'age'也添加到'name'下面?以下是我能想出的最好方案:
dic = {}
for ind, row in dat.groupby(['name', 'study', 'course', 'test'])['grade', 'pass']:
#this is ugly and not very generic, but just as an example
if not ind[0] in dic:
dic[ind[0]] = {}
if not ind[1] in dic[ind[0]]:
dic[ind[0]][ind[1]] = {}
if not ind[2] in dic[ind[0]][ind[1]]:
dic[ind[0]][ind[1]][ind[2]] = {}
if not ind[3] in dic[ind[0]][ind[1]][ind[2]]:
dic[ind[0]][ind[1]][ind[2]][ind[3]] = {}
dic[ind[0]][ind[1]][ind[2]][ind[3]]['grade'] = row['grade'].values[0]
dic[ind[0]][ind[1]][ind[2]][ind[3]]['pass'] = row['pass'].values[0]
但在这种情况下,“年龄”和“性别”不是嵌套在“姓名”下面。 我似乎无法想到如何解决这个问题...
另一种选择是设置MultiIndex并进行.to_dict('index')调用。 但我仍然看不到如何将两个dicts和非dicts嵌套在单个键下...
我的问题类似于这个问题: 将pandas DataFrame转换为嵌套字典,但我正在寻找更复杂的嵌套(例如,并不只是最后一列应该嵌套在所有其他列下面)。 Stackoverflow上的大多数其他问题都要求反向操作:从深度嵌套的字典创建(可能是MultiIndex)DataFrame。
编辑:该问题与此问题类似:Pandas将Dataframe转换为嵌套Json,但在那个问题中,只有最后一列(例如,列n)应嵌套在所有其他列(n-1,n-2等;完全递归嵌套)下。 在我的问题中,列n和n-1应嵌套在n-2下,但是列n-2和n-3应嵌套在n-4下(因此,重要的是n-2不是嵌套在n-3下而是嵌套在n-4下)。Mohammad Yusuf Ghazi提供的MultiIndex部分解决方案很好地描述了这种结构。