这是一个关于如何操纵一艘能够在三维空间中进行平移和旋转的宇宙飞船的非常困难的问题,用于太空游戏。
该飞船有n个喷气装置,位于各种位置和方向。
i号喷气装置相对于飞船质心的变换是恒定的=Ti。
- 变换是一个位置和方向的元组(四元数或3x3矩阵或不太优选的欧拉角)。
- 变换也可以用单个4x4矩阵表示。
换句话说,所有的喷气装置都附着在飞船上,不能旋转。
喷气装置只能朝着其轴(绿色)的方向对飞船施加力。由于粘合作用,轴随着飞船一起旋转。

所有喷射器都可以施加力(向量,Fi)以一定的大小(标量,fi):
第i个喷射器只能在范围min_i<= fi <=max_i内施加力(Fi= axis x fi)。
min_i和max_i均为已知常数。
需要明确的是,min_i、fi和max_i的单位均为牛顿。
例如:如果范围不包括0,则表示不能关闭喷射器。
飞船的质量=m,惯性张量=I。
飞船当前的变换=Tran0,速度=V0,角速度=W0。
I is different for each direction, but for simplicity, it has the same value for every direction (sphere-like). Thus, I can be thought of as a scalar instead of a matrix 3x3.
Question: How to control all jets (all fi) to land the ship with position=0 and angle=0? Mathematically, find a function of fi(time) that takes minimum time to reach position=(0,0,0), orient=identity with final angularVelocity and velocity = zero. What are the names of the techniques or related algorithms to solve this problem?
My research (1 dimension):
如果宇宙是一维的(因此没有旋转),问题将很容易解决。 (感谢Gavin Lock,https://dev59.com/F5zha4cB1Zd3GeqPAB1W#40359322)
首先,找到值
MIN_BURN=sum{min_i}/m和MAX_BURN=sum{max_i}/m。其次,反过来思考,假设
x=0(位置)和v=0在t=0,
然后创建两个抛物线,其中x''=MIN_BURN和x''=MAX_BURN。
(二阶导数被假定为在一段时间内恒定,因此是抛物线。)唯一剩下的工作就是将两个抛物线连接起来。 红色虚线是它们连接的地方。

x''=MAX_BURN 的时间段内,所有的 fi=max_i。
在 x''=MIN_BURN 的时间段内,所有的 fi=min_i。这对于一维问题非常有效,但在三维问题中,问题要难得多。
注意: 只需给我一个大致的指导方向即可。 我不需要完美的人工智能,例如它可以比最优解花费更多的时间。 我思考了1周以上,仍然没有头绪。
其他尝试/意见
我不认为像神经网络这样的机器学习方法适用于这种情况。
边界约束最小二乘优化可能有用,但我不知道如何将我的两个双曲线拟合到该问题的形式中。
这可以通过使用许多迭代来解决,但是怎么做呢?
我已经在NASA的网站上搜索过了,但没有找到任何有用的信息。
这个功能可能存在于“太空工程师”游戏中。 Logman的评论: 机械工程方面的知识可能有所帮助。 AndyG的评论: 这是一个非完整约束的运动规划问题。它可以通过快速探索随机树(RRTs)、李雅普诺夫方程理论以及线性二次调节器来解决。 John Coleman的评论: 这似乎更像最优控制而不是人工智能。
编辑: "近似为0的假设"(可选)
- 在大多数情况下,AI(待设计)会持续运行(即每个时间步调用一次)。
- 因此,随着AI的调整,
Tran0通常接近于恒等,V0和W0通常与0不太不同,例如|Seta0|<30度,|W0|<每个时间步5度。 - 我认为基于这种假设的AI在大多数情况下都能正常工作。虽然不完美,但可以视为正确的解决方案(我开始认为如果没有这个假设,这个问题可能太难了)。
- 我模糊地感觉这个假设可能会使用一些“线性”逼近的技巧。
第二个备选问题 - "调整12个变量"(更容易)
上述问题也可以理解为:
我想要将所有六个值和六个值'(一阶导数)都调整为0,使用最少的时间步长。
下面是一个表格,展示了AI可能会面临的情况:
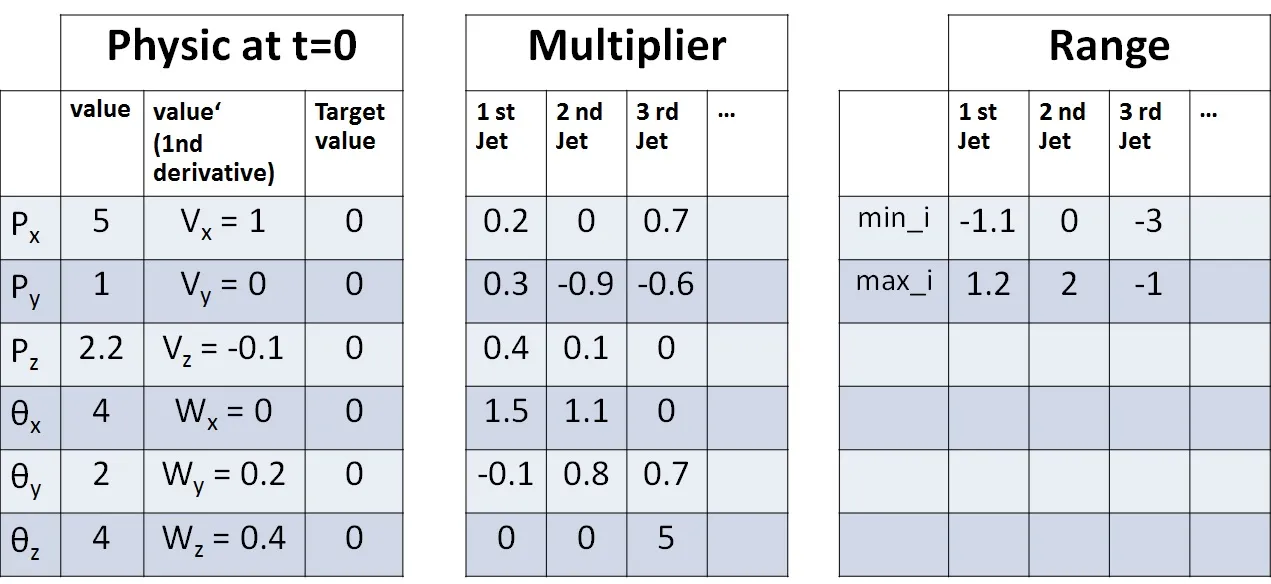
惯性^-1 * r和质量^-1。
Multiplier和Range是常数。每个时间步长,AI将被要求选择一个元组值
fi,该值必须在每个i+1喷口的范围[min_i,max_i]内。例如,从表中,AI可以选择
(f0=1,f1=0.1,f2=-1)。
然后,调用者将使用fi与乘数表相乘,得到values''。
Px'' = f0*0.2+f1*0.0+f2*0.7
Py'' = f0*0.3-f1*0.9-f2*0.6
Pz'' = ....................
SetaX''= ....................
SetaY''= ....................
SetaZ''= f0*0.0+f1*0.0+f2*5.0
之后,调用程序将使用公式values' += values''更新所有values'。
Px' += Px''
.................
SetaZ' += SetaZ''
values += values'更新所有values。Px += Px'.................SetaZ += SetaZ'
AI每个时间步只会被问一次。AI的目标是返回
fi元组(对于不同的时间步可以不同),使得Px,Py,Pz,SetaX,SetaY,SetaZ,Px',Py',Pz',SetaX',SetaY',SetaZ' = 0(或非常接近),并尽可能少地使用时间步数。
我希望提供问题的另一个视角能够使它更容易理解。
虽然这不是完全相同的问题,但我觉得一个能够解决这个版本的解决方案可以让我离答案更近一步。
这个替代问题的答案可能非常有用。
第三种替代方案 - “调整6个变量”(最简单)
这是前一个替代方案的简化版本,但会有信息损失。
唯一的区别是世界现在是二维的,Fi也是二维的(x,y)。
因此,我只需要调整Px,Py,SetaZ,Px',Py',SetaZ'=0,尽可能少地使用时间步骤。
对于这个最简单的替代问题的答案可以被认为是有用的。