我有一个CSV文件,看起来像这样(当使用
read_csv()将其导入pandas Dataframe时,它看起来也是这样的)。
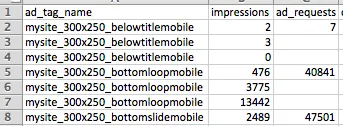
我希望根据以下逻辑更新列ad_requests中的值:
对于给定的行,如果ad_requests有一个值,则保持不变。否则,将其设置为上一行的ad_requests值减去上一行的impressions值。因此,在第一个示例中,我们希望最终得到:
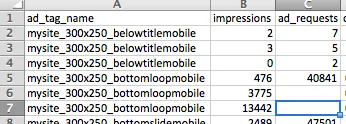
我部分地到达了那里:
df["ad_requests"] = [i if not pd.isnull(i) else ??? for i in df["ad_requests"]]
这就是我卡住的地方。在 else 后面,我想要“返回”并访问之前的“行”,尽管我知道这不是 pandas 的正确用法。
还有一点需要注意的是,行始终以列 ad_tag_name 为三个一组。如果我使用 pd.groupby["ad_tag_name"],那么我就可以将其转换为一个列表,并开始切片和索引,但我认为在 pandas 中必须有更好的方法(因为有很多东西)。
Python: 2.7.10
Pandas: 0.18.0
df.ad_requests.ffill() - df.impressions.cumsum().shift()可以帮助你完成部分工作。 - John Zwinck