如果你能使用
Cython并且愿意的话,你可以创建一个易读(至少如果你不介意输入)和快速的解决方案。
在这里,我正在使用Cython的IPython绑定将其编译为Jupyter笔记本:
%load_ext cython
%%cython
cimport cython
cimport numpy as cnp
import numpy as np
@cython.boundscheck(False)
@cython.wraparound(False)
cpdef cnp.int_t[:, :] mseifert(list a, int nrow, int ncol):
cdef cnp.int_t[:, :] out = np.zeros([nrow, ncol], dtype=int)
cdef list subl
cdef int row_idx
cdef int col_idx
for row_idx, subl in enumerate(a):
for col_idx in subl:
out[row_idx, col_idx] = 1
return out
为了比较这里介绍的解决方案的性能,我使用了我的库
simple_benchmark:
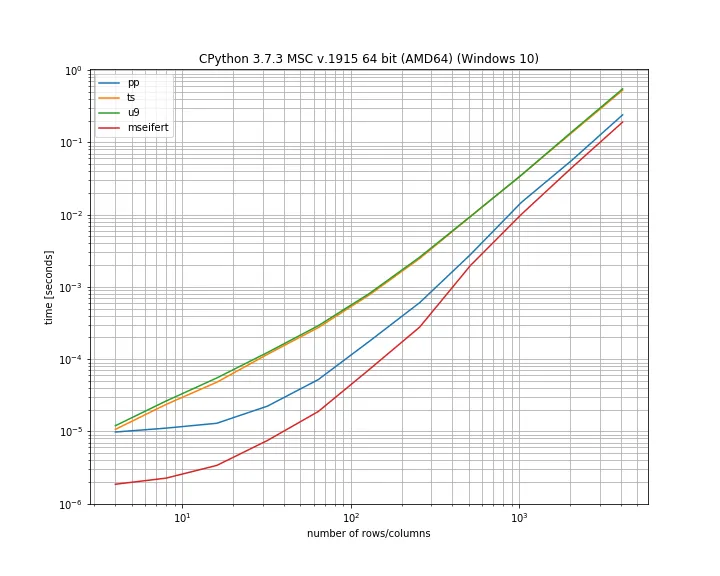
请注意,这里使用对数轴同时显示小和大数组的差异。根据我的基准测试,我的函数实际上是解决方案中最快的,然而也值得指出的是,所有解决方案的差距并不太大。
以下是我用于基准测试的完整代码:
import numpy as np
from simple_benchmark import BenchmarkBuilder, MultiArgument
import itertools
b = BenchmarkBuilder()
@b.add_function()
def pp(a, nrow, ncol):
sz = np.fromiter(map(len, a), int, nrow)
out = np.zeros((nrow, ncol), int)
out[np.arange(nrow).repeat(sz), np.fromiter(itertools.chain.from_iterable(a), int, sz.sum())] = 1
return out
@b.add_function()
def ts(a, nrow, ncol):
out = np.zeros((nrow, ncol), int)
for i, ix in enumerate(a):
out[i][ix] = 1
return out
@b.add_function()
def u9(a, nrow, ncol):
out = np.zeros((nrow, ncol), int)
for i, (x, y) in enumerate(zip(a, out)):
y[x] = 1
out[i] = y
return out
b.add_functions([mseifert])
@b.add_arguments("number of rows/columns")
def argument_provider():
for n in range(2, 13):
ncols = 2**n
a = [
sorted(set(np.random.randint(0, ncols, size=np.random.randint(0, ncols))))
for _ in range(ncols)
]
yield ncols, MultiArgument([a, ncols, ncols])
r = b.run()
r.plot()
a是一个不规则列表,所以它不容易进行向量化处理。 - cs95