我需要从字符串@anything_here@dhhhd@shdjhjs@中匹配@anything_here@。所以我使用以下正则表达式。
^@.*?@
或者
^@[^@]*@
两种方法都可以,但我想知道哪一种是更好的解决方案。使用非贪婪重复的正则表达式还是使用否定字符类的正则表达式?
我需要从字符串@anything_here@dhhhd@shdjhjs@中匹配@anything_here@。所以我使用以下正则表达式。
^@.*?@
或者
^@[^@]*@
两种方法都可以,但我想知道哪一种是更好的解决方案。使用非贪婪重复的正则表达式还是使用否定字符类的正则表达式?
如果可能的话,通常应优先使用否定字符类而不是懒惰匹配。
如果正则表达式成功,^@[^@]*@ 可以在一步中匹配 @ 之间的内容,而 ^@.*?@ 需要为 @ 之间的每个字符扩展。
当失败时(对于没有结尾 @ 的情况),大多数正则表达式引擎会施加一些魔法,并在内部将 [^@]* 视为 [^@]*+,因为 @ 和非 @ 之间有明确的分界线,因此它将匹配到字符串的末尾,识别缺少的 @ 并不回溯,而是立即失败。 .*? 将像往常一样逐个扩展字符。
在更大的上下文中使用时,[^@]* 也永远不会超出结束 @ 的边界,而这对于懒惰匹配来说是非常可能的。例如,^@[^@]*a[^@]*@ 不会匹配 @bbbb@a@,而 ^@.*?a.*?@ 会。
请注意,[^@] 也将匹配换行符,而 . 不会(在大多数正则表达式引擎中,除非在单行模式下使用)。您可以通过将换行符添加到否定中来避免这种情况 - 如果不想要它。
很明显,使用^@[^@]*@模式更好。
否定字符类被贪婪地匹配,这意味着正则表达式引擎立即抓取0个或多个不是@的字符,尽可能多地匹配。请参见此正则表达式演示和匹配:
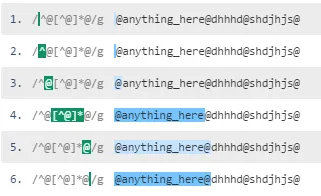
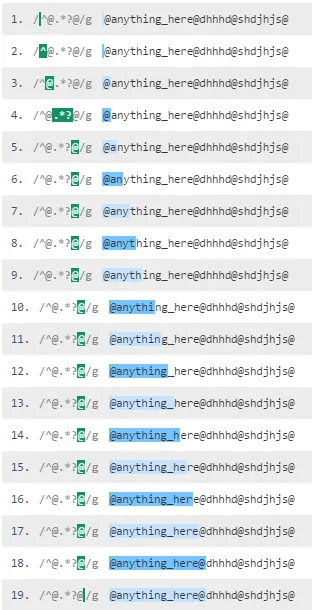
当您使用惰性点匹配模式时,引擎匹配@,然后尝试匹配尾随的@(跳过.*?)。它在索引1处没有找到@,因此.*?匹配a字符。该.*?模式展开了许多次,直到第一个@之前有除@以外的字符。
请参见此基于惰性点匹配的模式演示,以下是匹配步骤:
^@[^@]*@选项更好。 - Wiktor Stribiżew