在启用单行模式的情况下,这两个正则表达式模式
a.*?b和a[^b]*b有什么区别?它们在性能方面有什么不同吗?a.*?b 必须在每个已消费的字符上检查是否匹配模式(即下一个字符是否为b)。这就是所谓的回溯。
对于字符串a12b,执行过程如下:
ab吗?不是。a1)。下一个是b吗?不是。a12)。下一个是b吗?是的!ba[^b]*b 消耗任何不是b的内容而无需自问自答,因此在处理较长字符串时速度更快。
对于字符串a12b,执行过程如下:
ab的字符。(a12)bRegexHero 有一个基准测试功能,可以演示 .NET 正则表达式引擎的性能差异。
除了性能差异之外,在您的示例中它们匹配相同的字符串。
但是,在字符串aa111b111b中有一些情况存在差异:
(?<=aa.*?)b 匹配两个 b,而(?<=aa[^b]*)b 只匹配第一个。
我已经测试了您的两个正则表达式,将它们命名为:
NONGREEDY = /a.*?b/;
GREEDY = /a[^b]*b/;
我将负面正则表达式称为GREEDY,但这只是一个名称。
您可以在JsPerf上检查test-non-greedy-vs-greedy-performance并运行测试以自行查看。随意修改字符串以执行不同的测试用例。
您可以检查其他人添加的不同测试,并且基准测试结果取决于输入字符串。
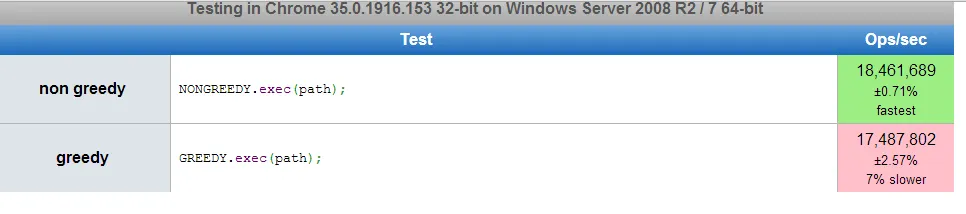
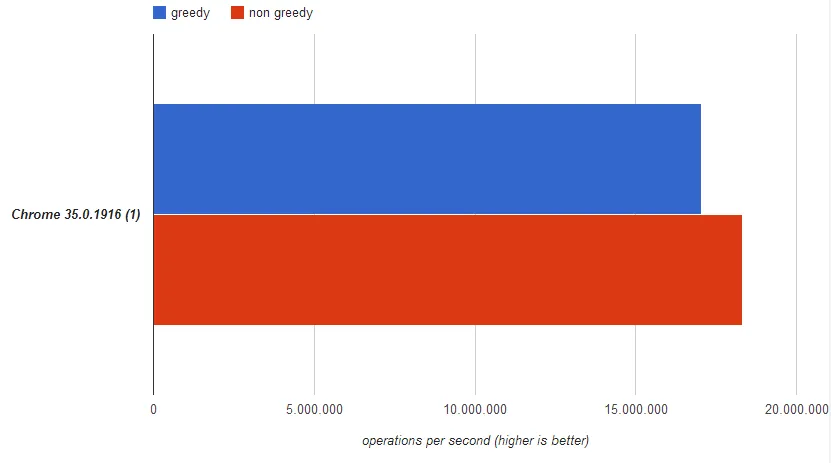
以下测试针对字符串:ab
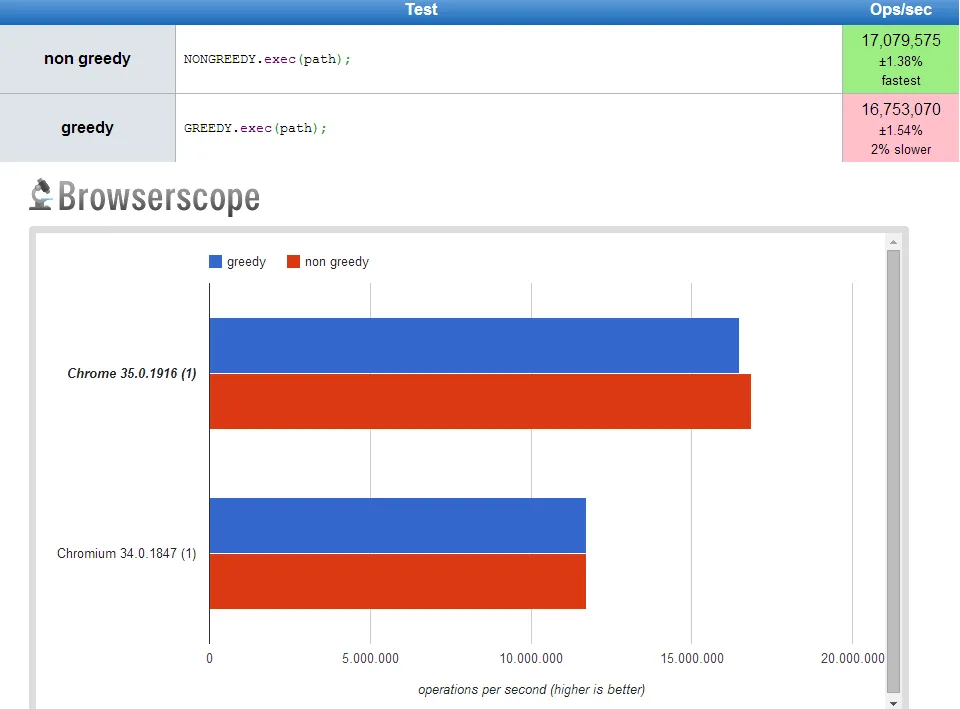 以下测试是针对字符串:afdkjsklfjsdlkfjsdlkfjsdlkjflskdjflsdfjjflksdjfb
以下测试是针对字符串:afdkjsklfjsdlkfjsdlkfjsdlkjflskdjflsdfjjflksdjfb
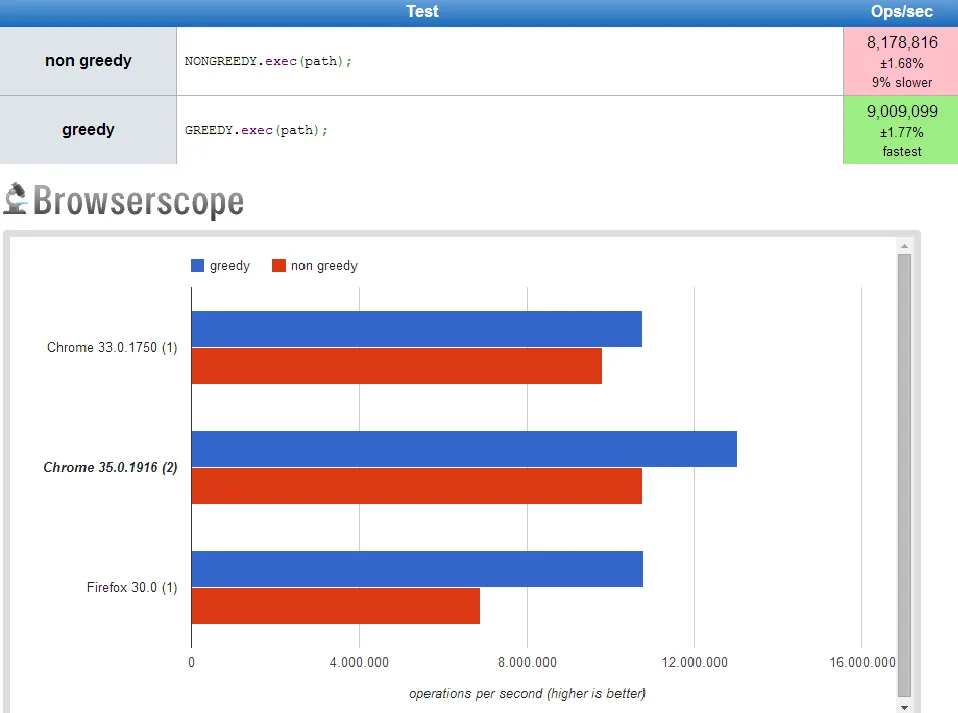 在这些测试之后,性能似乎取决于您正在解析的字符串。
在这些测试之后,性能似乎取决于您正在解析的字符串。
a[^b]*b的得分将优于a.*?b。 - anubhavab。问题是,它是直接按照这种方式进行搜索 - 还是从开头(第一种情况)/ 末尾(第二种情况)检查每个字母。 - raina77owa.*?b中涉及到回溯,因此...... - anubhava