我正在尝试将数据中的一些空列表替换为NaN值。但如何在表达式中表示一个空列表?
import numpy as np
import pandas as pd
d = pd.DataFrame({'x' : [[1,2,3], [1,2], ["text"], []], 'y' : [1,2,3,4]})
d
x y
0 [1, 2, 3] 1
1 [1, 2] 2
2 [text] 3
3 [] 4
d.loc[d['x'] == [],['x']] = d.loc[d['x'] == [],'x'].apply(lambda x: np.nan)
d
ValueError: Arrays were different lengths: 4 vs 0
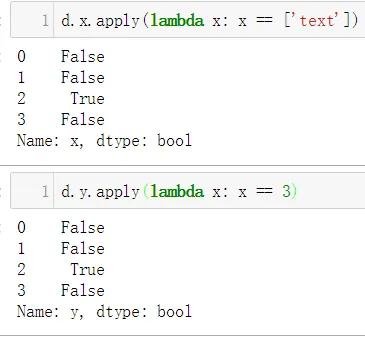
而且,我想使用d[d['x'] == ["text"]]选择[text],但是会出现ValueError: Arrays were different lengths: 4 vs 1的错误。但是,使用d[d['y'] == 3]选择3是正确的。为什么呢?
d.x = d.x.apply(lambda y: np.nan if len(y)==0 else y)是如何工作的? - Abdou