我有以下的pandas数据框:
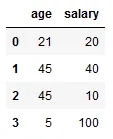
import pandas as pd
import numpy as np
d = {'age' : [21, 45, 45, 5],
'salary' : [20, 40, 10, 100]}
df = pd.DataFrame(d)
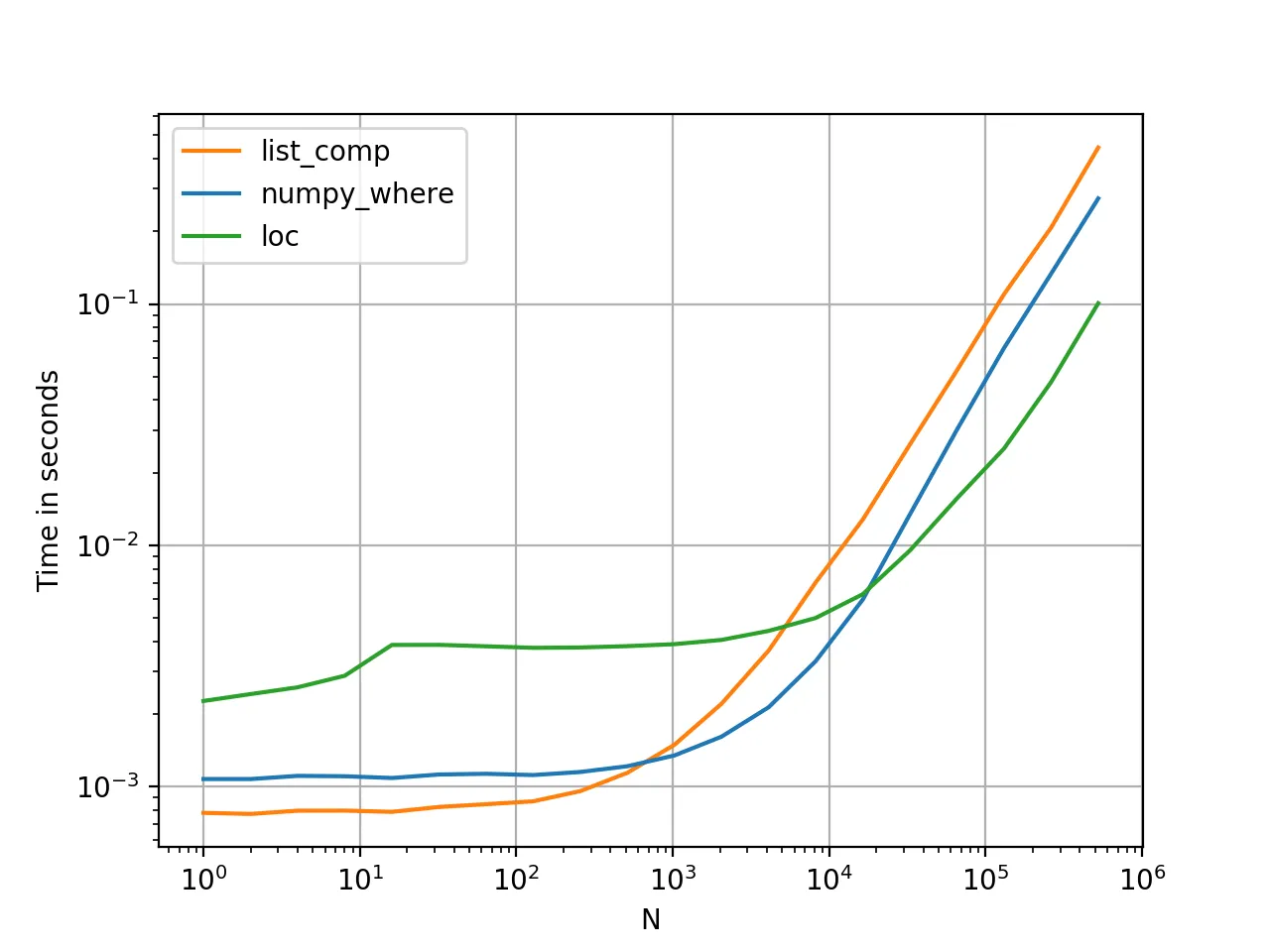
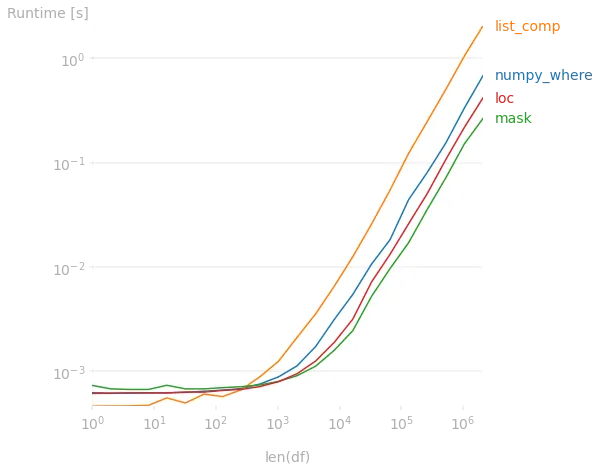
我希望添加一个额外的列,名为“is_rich”,根据一个人的工资来确定他/她是否富裕。我找到了多种实现方法:
# method 1
df['is_rich_method1'] = np.where(df['salary']>=50, 'yes', 'no')
# method 2
df['is_rich_method2'] = ['yes' if x >= 50 else 'no' for x in df['salary']]
# method 3
df['is_rich_method3'] = 'no'
df.loc[df['salary'] > 50,'is_rich_method3'] = 'yes'
导致:

然而我不明白哪种方法是首选。根据您的应用程序,所有方法是否都同样好?