我一直在使用GPU,但没有质疑过它,现在我很好奇。
为什么GPU可以比CPU更快地进行矩阵乘法?是因为并行处理吗?但我没有编写任何并行处理代码。它会自动执行吗?
非常感谢任何直觉/高层次的解释!
我一直在使用GPU,但没有质疑过它,现在我很好奇。
为什么GPU可以比CPU更快地进行矩阵乘法?是因为并行处理吗?但我没有编写任何并行处理代码。它会自动执行吗?
非常感谢任何直觉/高层次的解释!
GPU能够进行大量的并行计算,比CPU更多。例如,让我们看一下向量加法的示例,假设有1百万个元素。
使用CPU时,您最多可以运行100个线程(100是非常少的,但暂且这样假设)。
在典型的多线程示例中,假设您将所有线程上的加法并行化。
这就是我的意思:
c[0] = a[0] + b[0] # let's do it on thread 0
c[1] = a[1] + b[1] # let's do it on thread 1
c[101] = a[101] + b[101] # let's do it on thread 1
我们之所以能做到这一点,是因为c [0]的值仅取决于a [0]和b [0],而不依赖于任何其他值。因此,每个加法都是独立的。因此,我们能够轻松地并行化任务。
正如您在上面的示例中看到的,同时进行100个不同元素的所有加法,可以节省时间。通过这种方式,需要1M / 100 = 10,000步才能添加所有元素。
现在考虑具有约2048个线程的GPU,所有线程都可以在恒定时间内独立执行2048个不同操作。因此具有提升作用。
在矩阵乘法的情况下,您可以并行计算,因为GPU具有更多线程,并且在每个线程中有多个块。因此大量计算被并行化,导致快速计算。
但我没有为我的GTX1080编写任何并行处理!它会自己做吗?
几乎所有机器学习框架都使用了所有可能操作的并行化实现。这是通过CUDA编程实现的,CUDA是NVIDIA GPU上进行并行计算的API。您不需要显式编写它,在低级别完成所有操作,甚至您都不会知道。
是的,并不意味着您编写的C ++程序将自动并行化,只因为您有一个GPU。不,您需要使用CUDA编写它,才能并行化,但大多数编程框架都已经具备了这种功能,因此无需从您的端进行配置。
实际上,这个问题促使我从华盛顿大学(Luis Ceze博士)学习计算机体系结构课程。现在我可以回答这个问题。
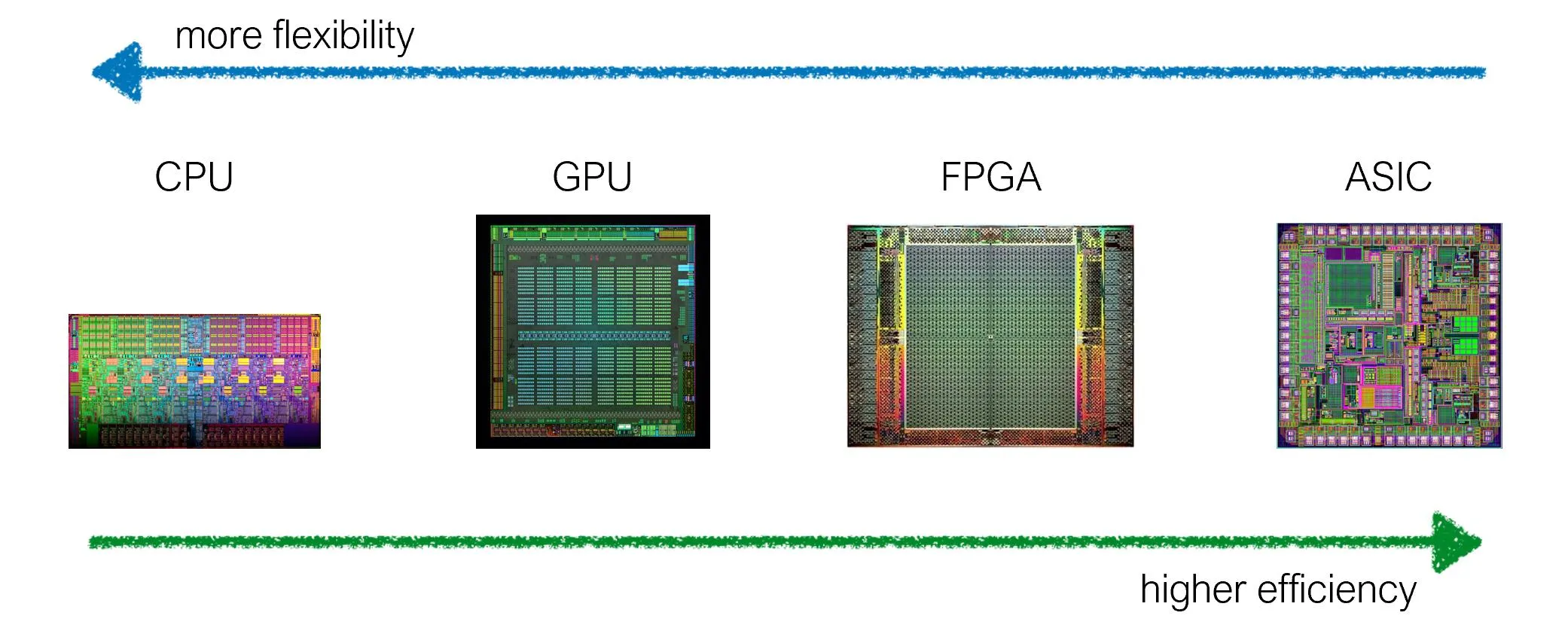
总的来说,这是由于硬件专业化。我们可以量身定制芯片架构来平衡专业化和效率(更灵活 vs 更有效率)。例如,GPU高度专门用于并行处理,而CPU则设计为处理许多不同类型的操作。
此外,FPGA、ASIC比GPU更加专业化。(你看到了用于处理单元的块吗?)
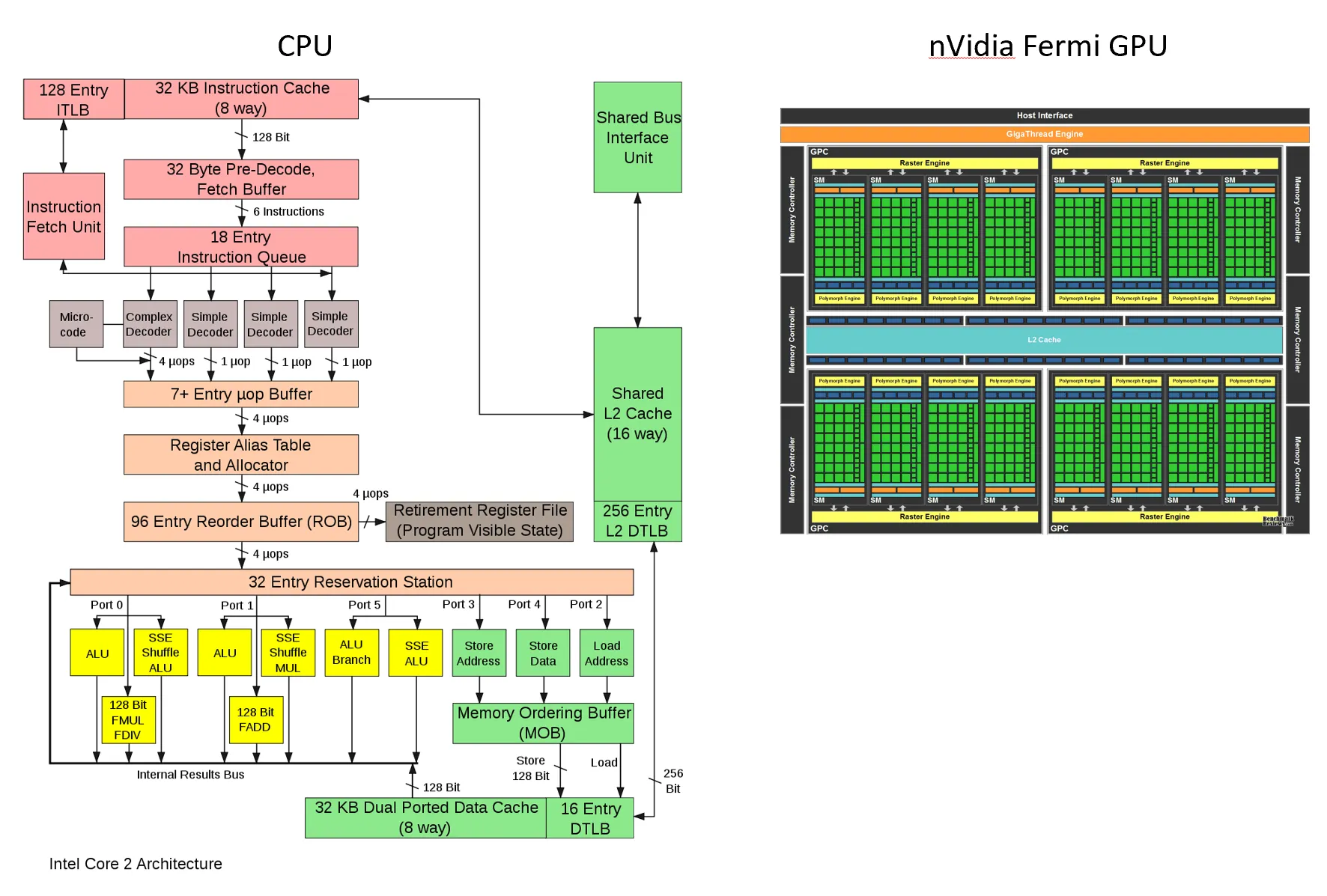
GPU 设计传统上侧重于最大化浮点单位和执行多维数组操作。它们最初是为图形设计的,线性数学非常有用。
CPU 优化用于通用计算和单线程执行。每个执行单元都很大且复杂。