有不同的方法
对数据集进行分块(节省未来的时间但需要初始时间投入)
分块可以使您轻松完成许多操作,例如洗牌等。
确保每个子集/块都代表整个数据集。每个块文件应具有相同数量的行。
这可以通过将一行附加到另一个文件来完成。很快,您就会意识到,在读写同一驱动器时打开每个文件并写入一行效率低下。
-> 添加适合内存的写入和读取缓冲区。
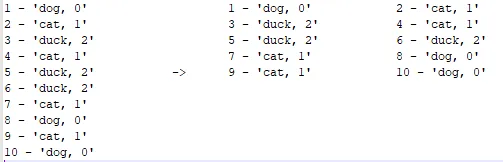
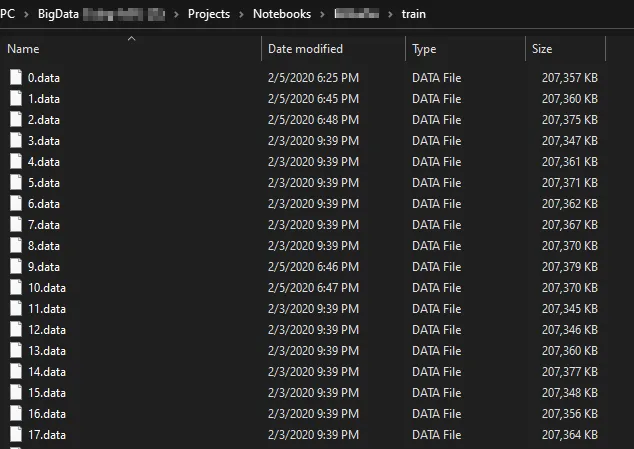
选择适合您需求的块大小。我选择这个特定的大小,因为我的默认文本编辑器仍然可以相当快速地打开它。
较小的块可以提高性能,特别是如果您想获取类分布之类的指标,因为您只需要通过一个代表性文件循环即可获得整个数据集的估计值,这可能就足够了。
较大的块文件在每个文件中都具有更好的整体数据集表示,但是您也可以浏览x个较小的块文件。
我使用c#来完成这个任务,因为我在那里经验更丰富,因此我可以使用完整的功能集,例如将任务分割为不同的线程:读取/处理/写入。
如果您熟练掌握使用python或r,则应该也有类似的功能。并行化可能是处理如此庞大的数据集的重要因素。
可以将分块数据集建模为一个交错的数据集,您可以使用张量处理单元进行处理。 这可能会产生最佳性能之一,并且可以在大型机器上本地执行以及在云端执行。 但这需要在tensorflow上学习很多知识。
使用读取器逐步读取文件
与其像 all_of_it = file.read()那样做,你想使用某种类型的流读取器。以下函数逐行读取一个块文件(或整个300gb数据集),以计算文件内的每个类别。通过一次处理一行,程序不会溢出内存。
您可能需要添加一些进度指示,例如X行/秒或X MBbs,以便估计总处理时间。
def getClassDistribution(path):
classes = dict()
with open(path, "r",encoding="utf-8",errors='ignore') as f:
line = f.readline()
while line:
if line != '':
labelstring = line[-2:-1]
if labelstring == ',':
labelstring = line[-1:]
label = int(labelstring)
if label in classes:
classes[label] += 1
else:
classes[label] = 1
line = f.readline()
return classes

我使用分块数据集和估计的组合。
性能陷阱:
尽可能避免嵌套循环。每个内部循环都会将复杂度乘以n。尽可能避免逐一处理数据。每个后续循环都会增加n的复杂度。- 如果您的数据以csv格式呈现,请避免预制函数,例如
cells = int(line.Split(',')[8]),否则会很快导致内存吞吐量瓶颈。可以在getClassDistribution中找到一个正确的例子,其中我只想获取标签。
以下C#函数将csv行快速拆分成元素。
ThreadPool.QueueUserWorkItem((c) => AnalyzeLine("05.02.2020,12.20,10.13").Wait());
private async Task AnalyzeLine(string line)
temp = "";
counter++;
}
else temp += c;
}
Observate(elementToAdd);
}
创建数据库并加载数据
处理类似csv的数据时,可以将数据加载到数据库中。
数据库专门用于容纳大量数据,并且您可以期望非常高的性能。
数据库可能会占用比原始数据更多的磁盘空间。这是我放弃使用数据库的原因之一。
硬件优化
如果您的代码已经进行了优化,那么瓶颈很可能是硬盘吞吐量。
- 如果数据适合本地硬盘,请在本地使用,这样可以消除网络延迟(想象一下每个记录在本地网络中需要2-5毫秒,在远程位置需要10-100毫秒)。
- 使用现代硬盘。1TB NVME SSD今天的成本约为130美元(Intel 600p 1TB)。 NVME SSD使用PCIe,比普通SSD快5倍,比普通硬盘快50倍,特别是在快速写入不同位置(分块数据)时。在最近几年中,SSD在容量方面已经取得了巨大进展,对于这样的任务来说,它将非常有效。
以下屏幕截图提供了Tensorflow在相同机器上使用相同数据进行训练的性能比较。在一个本地标准SSD上保存一次,另一次保存在连接到局域网的网络附加存储(普通硬盘)。