当我在谷歌上搜索关于Python列表推导的信息时,我被提供了一个谷歌foobar挑战,为了好玩我已经慢慢地在过去的几天里进行了挑战。最新的挑战:
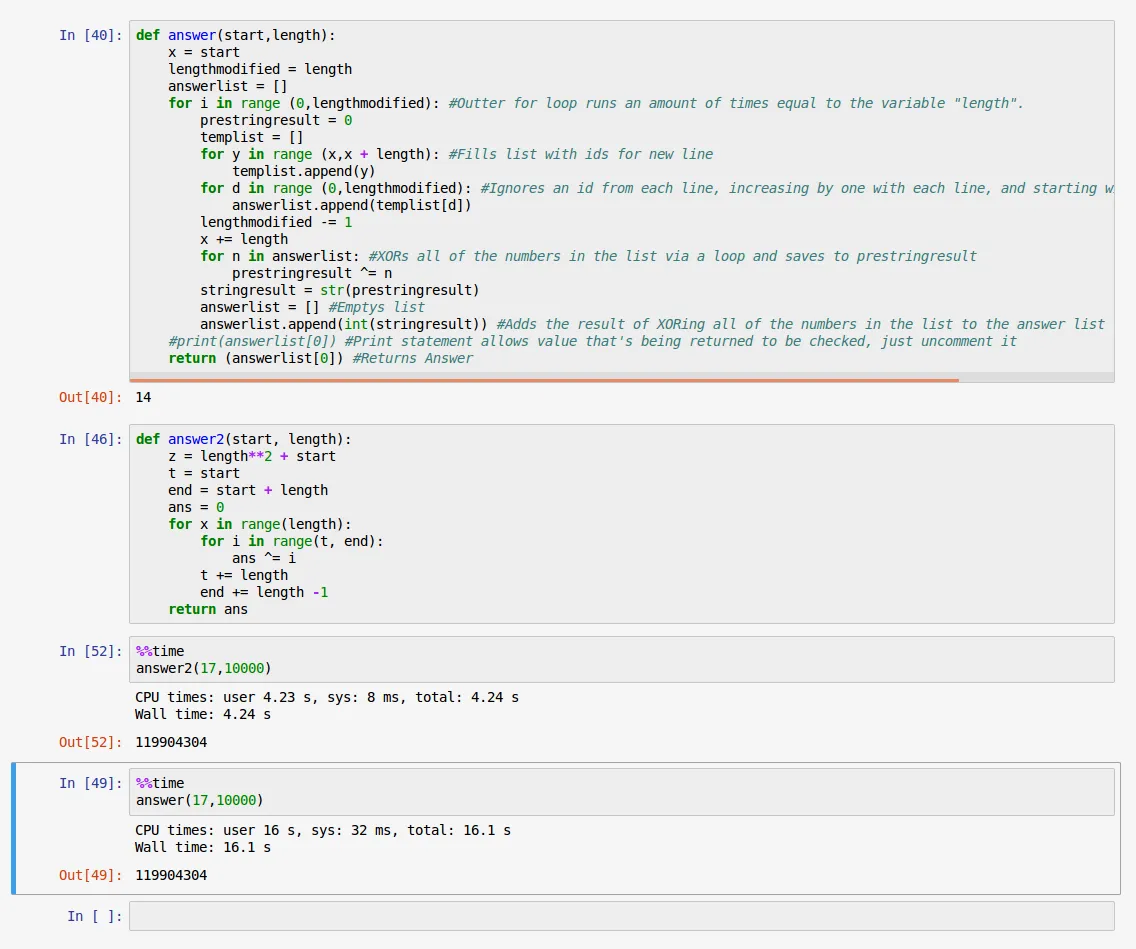
这段代码要求有效地生成一个ID列表,忽略每个新行中逐渐增加的ID,直到只剩下一个ID。然后,您应该使用XOR(^)对这些ID进行运算以生成校验和。我创建了一个输出正确答案的可行程序,但它的效率不足以通过所有测试用例(6/10),在规定的时间内完成50000长度的计算,需要不到20秒,但是它需要320秒。
有没有人可以指导我走向正确的方向,但请不要替代我完成代码,我正在通过这个挑战来锻炼自己。也许我可以实现一种数据结构或算法来加快计算时间?
代码背后的逻辑:
首先,输入起始ID和长度
生成一个ID列表,忽略每个新行开始忽略的ID数量,从第一行开始忽略0个ID。
使用for循环对ID列表中的所有数字进行XOR运算
将答案返回为int型
import timeit
def answer(start,length):
x = start
lengthmodified = length
answerlist = []
for i in range (0,lengthmodified): #Outter for loop runs an amount of times equal to the variable "length".
prestringresult = 0
templist = []
for y in range (x,x + length): #Fills list with ids for new line
templist.append(y)
for d in range (0,lengthmodified): #Ignores an id from each line, increasing by one with each line, and starting with 0 for the first
answerlist.append(templist[d])
lengthmodified -= 1
x += length
for n in answerlist: #XORs all of the numbers in the list via a loop and saves to prestringresult
prestringresult ^= n
stringresult = str(prestringresult)
answerlist = [] #Emptys list
answerlist.append(int(stringresult)) #Adds the result of XORing all of the numbers in the list to the answer list
#print(answerlist[0]) #Print statement allows value that's being returned to be checked, just uncomment it
return (answerlist[0]) #Returns Answer
#start = timeit.default_timer()
answer(17,4)
#stop = timeit.default_timer()
#print (stop - start)