如果你想提取图像中的每个单独字符,你可以使用
regionprops轻松实现。只需使用
BoundingBox属性提取每个字符周围的边界框。之后,我们可以将每个字符放置在一个
cell数组中进行进一步处理。如果你想将其存储到
26 x N数组中,你首先需要识别每个字母,以便选择该字母应该放置在第一维度的位置。因为你想先分割出字符,所以我们将专注于这方面。因此,让我们将图像加载到MATLAB中。请注意,原始图像是GIF格式的,当我在电脑上加载它时...它看起来很混乱。我已经将图像重新保存为PNG格式,并在下面显示:
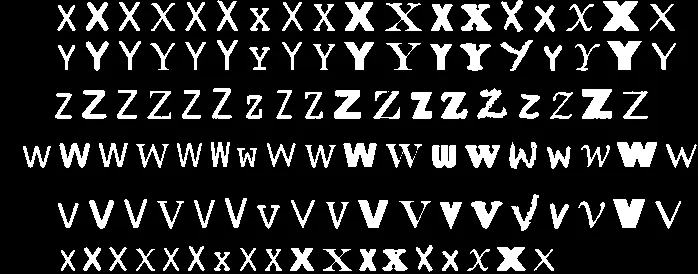
让我们将其读入MATLAB中:
im = imread('http://i.stack.imgur.com/q7cnA.png');
你可能会注意到一些字母之间存在断裂。我们可以执行形态学开运算来关闭这些间隙。但是,我们不会使用这个图像来提取实际字符是什么。我们只是用它来获取字母的边界框:
se = strel('square', 7);
im_close = imclose(im, se);
现在,您可以像这样调用regionprops来查找图像中所有边界框(应用形态学后):
s = regionprops(im_close, 'BoundingBox');
s返回的是一个结构体,其中每个元素都包含一个边界框,该边界框封装了图像中检测到的一个对象。在我们的情况下,这是一个单字符。每个对象的BoundingBox属性是一个由4个元素组成的数组,格式如下:
[x y w h]
(x,y) 是边界框左上角的列和行坐标,w 和 h 是边界框的宽度和高度。接下来要做的是创建一个四列矩阵,将所有这些边界框属性封装在一起,其中每行表示一个边界框:
bb = round(reshape([s.BoundingBox], 4, []).');
必须将值四舍五入,因为如果想从图像中提取字母,我们必须在整数坐标系中进行操作,因为这是图像的自然定义方式。如果您想获得这些边界框的良好说明,下面的代码将在每个检测到的字符周围绘制一个红色框:
imshow(im);
for idx = 1 : numel(s)
rectangle('Position', bb(idx,:), 'edgecolor', 'red');
end
这就是我们得到的结果:

最后的任务是提取所有字符并将它们放入一个 cell 数组中。我使用了一个 cell 数组因为字符大小不均,所以将其放入一个 cell 数组中可以适应不同的大小。因此,只需循环处理每个边界框,然后提取像素边界框以获取每个字符并将其放入一个 cell 数组中即可。
chars = cell(1, numel(s));
for idx = 1 : numel(s)
chars{idx} = im(bb(idx,2):bb(idx,2)+bb(idx,4)-1, bb(idx,1):bb(idx,1)+bb(idx,3)-1);
end
如果您想要一个字符,只需执行 ch = chars{idx};,其中idx是从1到我们拥有的字符数量的任意数字。 您还可以通过执行imshow(ch);来查看此字符的外观。
这应该足以让您开始入手。祝你好运!
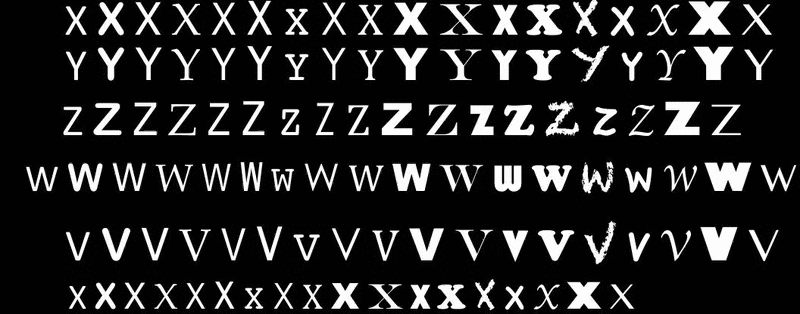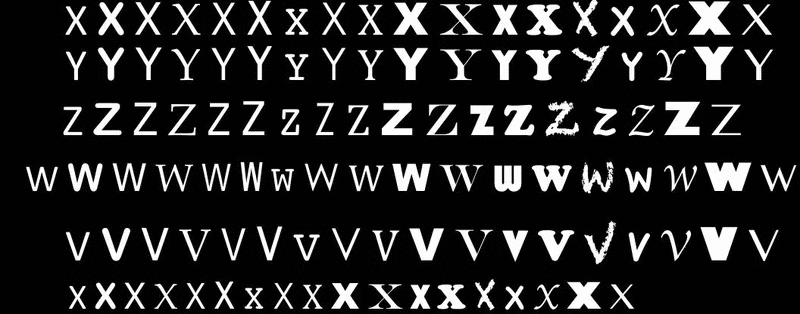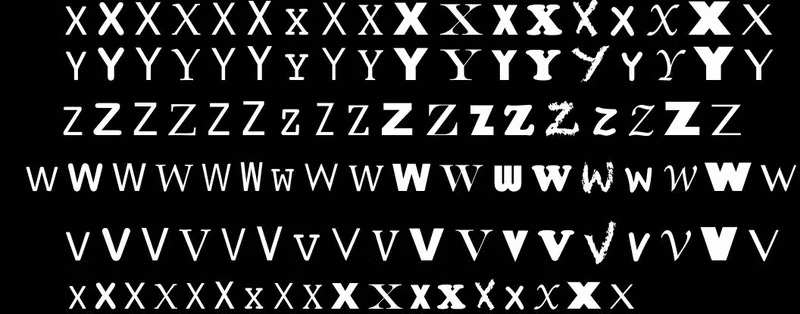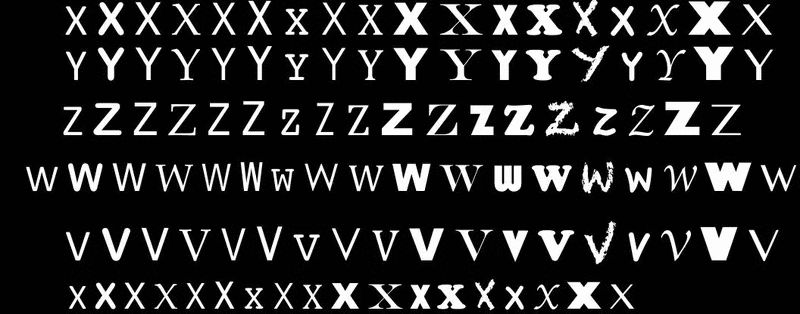 我需要一种有效的方法来将每个字母分割成单独的图像,这样我就会得到一个26Xn数组,其中26是字母表中的每个字母,n是包含单个字母的图像数据变量数。手动从每个训练图像中分割字母或尝试通过指定长度来分割字母将非常繁琐,因为字母之间的间隔并不总是相等的。
我需要一种有效的方法来将每个字母分割成单独的图像,这样我就会得到一个26Xn数组,其中26是字母表中的每个字母,n是包含单个字母的图像数据变量数。手动从每个训练图像中分割字母或尝试通过指定长度来分割字母将非常繁琐,因为字母之间的间隔并不总是相等的。