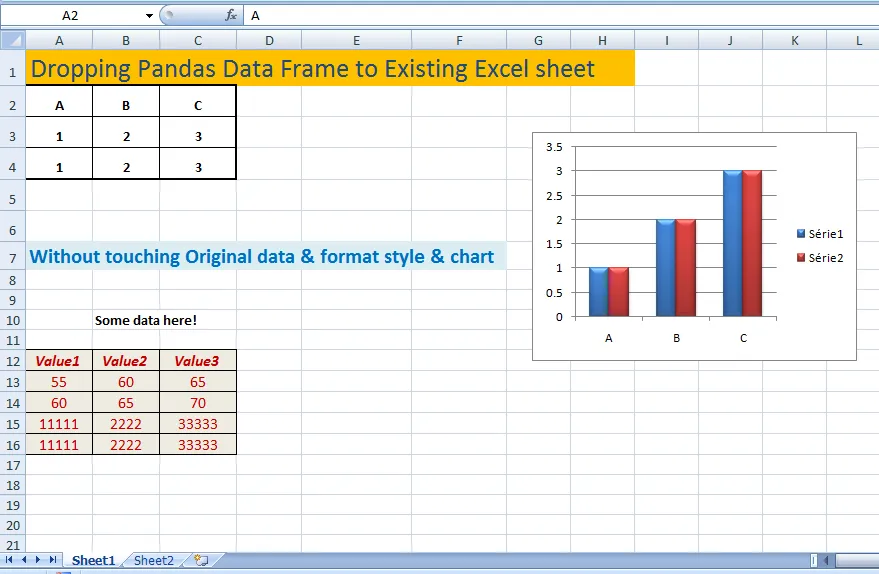
Pandas允许您将数据框写入Excel并指定要从哪一列和行开始。因此,在您的情况下,可以提及:
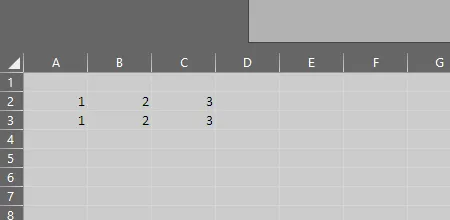
df.to_excel(writer, sheet_name='Sheet1', header=None, index=False,
startcol=1, startrow=2)
需要相应地更新sheet_name
因此,您的整个代码可能如下所示:
import pandas as pd
from openpyxl import load_workbook
fn = r'C:\YourFolder\doc.xlsx'
book = load_workbook(fn)
df = pd.DataFrame([[1,2,3],[1,2,3]], columns=list('ABC'))
writer = pd.ExcelWriter(fn, engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(writer, sheet_name='Sheet1', header=None, index=False,
startcol=1, startrow=2)
writer.save()