我有以下代码:
大约需要2秒钟,
import pandas as pd
import time
def enrich_str(str):
val1 = f'{str}_1'
val2 = f'{str}_2'
val3 = f'{str}_3'
time.sleep(3)
return val1, val2, val3
def enrich_row(passed_row):
col_name = str(passed_row['colName'])
my_string = str(passed_row[col_name])
val1, val2, val3 = enrich_str(my_string)
passed_row['enriched1'] = val1
passed_row['enriched2'] = val2
passed_row['enriched3'] = val3
return passed_row
df = pd.DataFrame({'numbers': [1, 2, 3, 4, 5], 'colors': ['red', 'white', 'blue', 'orange', 'red']},
columns=['numbers', 'colors'])
df['colName'] = 'colors'
tic = time.perf_counter()
enriched_df = df.apply(enrich_row, col_name='colors', axis=1)
toc = time.perf_counter()
print(f"{df.shape[0]} rows enriched in {toc - tic:0.4f} seconds")
enriched_df
获取如下数据框的输出需要15秒钟:
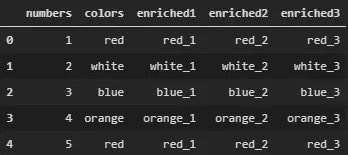
现在我想使用多线程在我的机器上并行执行丰富操作。我尝试了很多解决方案,例如 Dask、numba,但似乎都不是很直接。
然后我偶然发现了 multiprocessing 库及其 pool.imaps() 方法。因此,我尝试运行以下代码:
import multiprocessing as mp
tic = time.perf_counter()
pool = mp.Pool(5)
result = pool.imap(enrich_row, df.itertuples(), chunksize=1)
pool.close()
pool.join()
toc = time.perf_counter()
print(f"{df.shape[0]} rows enriched in {toc - tic:0.4f} seconds")
result
大约需要2秒钟,
result不是Pandas数据框架。我无法找出我的错误所在。
apply()方法处理用read_csv()读取的数据(120行)。但是这个过程没有进行并行化,而且我也不明白为什么。后来我发现这是因为dataframe的npartitions为1所导致的。通过对dataframe进行重新分区,使用repartition(npartitions=os.cpu_count()*2)方法解决了这个问题。 - lucazav