更新
现在已正式由 keras-cv 支持。
在生成具有
CutMix 或 MixUp 增强类型的类标签时,我们可以使用像 np.random.beta 或 scipy.stats.beta 这样的 beta 函数,并对两个标签执行以下步骤:label = label_one*beta + (1-beta)*label_two
但是如果我们有超过两张图片呢?在YoLo4中,他们尝试了一种有趣的增强叫做Mosaic Augmentation,用于解决目标检测问题。与CutMix或MixUp不同,这种增强会创建带有4张图像的增强样本。在目标检测案例中,我们可以计算每个实例坐标的偏移量,从而可能获得适当的真实值,这里。但对于仅图像分类案例,我们该怎么办呢?
这里是一个入门。
import tensorflow as tf
import matplotlib.pyplot as plt
import random
(train_images, train_labels), (test_images, test_labels) = \
tf.keras.datasets.cifar10.load_data()
train_images = train_images[:10,:,:]
train_labels = train_labels[:10]
train_images.shape, train_labels.shape
((10, 32, 32, 3), (10, 1))
这是我们为此增强编写的一个函数;(使用“内部-外部循环”太丑陋了!如果可以高效地完成,请提出建议。)
def mosaicmix(image, label, DIM, minfrac=0.25, maxfrac=0.75):
'''image, label: batches of samples
'''
xc, yc = np.random.randint(DIM * minfrac, DIM * maxfrac, (2,))
indices = np.random.permutation(int(image.shape[0]))
mosaic_image = np.zeros((DIM, DIM, 3), dtype=np.float32)
final_imgs, final_lbs = [], []
# Iterate over the full indices
for j in range(len(indices)):
# Take 4 sample for to create a mosaic sample randomly
rand4indices = [j] + random.sample(list(indices), 3)
# Make mosaic with 4 samples
for i in range(len(rand4indices)):
if i == 0: # top left
x1a, y1a, x2a, y2a = 0, 0, xc, yc
x1b, y1b, x2b, y2b = DIM - xc, DIM - yc, DIM, DIM # from bottom right
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, 0, DIM , yc
x1b, y1b, x2b, y2b = 0, DIM - yc, DIM - xc, DIM # from bottom left
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = 0, yc, xc, DIM
x1b, y1b, x2b, y2b = DIM - xc, 0, DIM, DIM-yc # from top right
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, DIM, DIM
x1b, y1b, x2b, y2b = 0, 0, DIM-xc, DIM-yc # from top left
# Copy-Paste
mosaic_image[y1a:y2a, x1a:x2a] = image[i,][y1b:y2b, x1b:x2b]
# Append the Mosiac samples
final_imgs.append(mosaic_image)
return final_imgs, label
目前带有错误标签的增强样本。
data, label = mosaicmix(train_images, train_labels, 32)
plt.imshow(data[5]/255)

然而,这里有一些更多的例子来激励你。数据来自Cassava Leaf比赛。

(来源:googleapis.com)

(来源: googleapis.com)
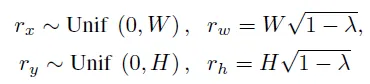
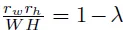
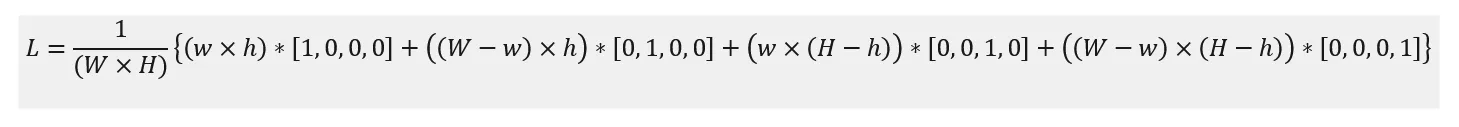
.png?generation=1607625768667914&alt=media){kind=link}
.png?generation=1607625855803714&alt=media){kind=link}