我目前正在尝试理解如何重用VGG19(或其他架构),以改进我的小型图像分类模型。 我将图像(在这种情况下是绘画)分类为3个类别(假设是15世纪、16世纪和17世纪的绘画)。 我有一个相当小的数据集,每个类别有1800个训练示例,在验证集中,每个类别有250个。
我有以下实现:
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras import backend as K
from keras.callbacks import ModelCheckpoint
from keras.regularizers import l2, l1
from keras.models import load_model
# set proper image ordering for TensorFlow
K.set_image_dim_ordering('th')
batch_size = 32
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# this is a generator that will read pictures found in
# subfolers of 'data/train', and indefinitely generate
# batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'C://keras//train_set_paintings//', # this is the target directory
target_size=(150, 150), # all images will be resized to 150x150
batch_size=batch_size,
class_mode='categorical')
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'C://keras//validation_set_paintings//',
target_size=(150, 150),
batch_size=batch_size,
class_mode='categorical')
model = Sequential()
model.add(Conv2D(16, (3, 3), input_shape=(3, 150, 150)))
model.add(Activation('relu')) # also tried LeakyRelu, no improvments
model.add(MaxPooling2D(pool_size=(2, 3), data_format="channels_first"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 3), data_format="channels_first"))
model.add(Flatten())
model.add(Dense(64, kernel_regularizer=l2(.01)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam', # also tried SGD, it doesn't perform as well as adam
metrics=['accuracy'])
fBestModel = 'best_model_final_paintings.h5'
best_model = ModelCheckpoint(fBestModel, verbose=0, save_best_only=True)
hist = model.fit_generator(
train_generator,
steps_per_epoch=2000 // batch_size,
epochs=100,
validation_data=validation_generator,
validation_steps=200 // batch_size,
callbacks=[best_model],
workers=8 # cpu generation is run in parallel to the gpu training
)
print("Maximum train accuracy:", max(hist.history["acc"]))
print("Maximum train accuracy on epoch:", hist.history["acc"].index(max(hist.history["acc"]))+1)
print("Maximum validation accuracy:", max(hist.history["val_acc"]))
print("Maximum validation accuracy on epoch:", hist.history["val_acc"].index(max(hist.history["val_acc"]))+1)
在防止过拟合方面,我已经控制得比较平衡:
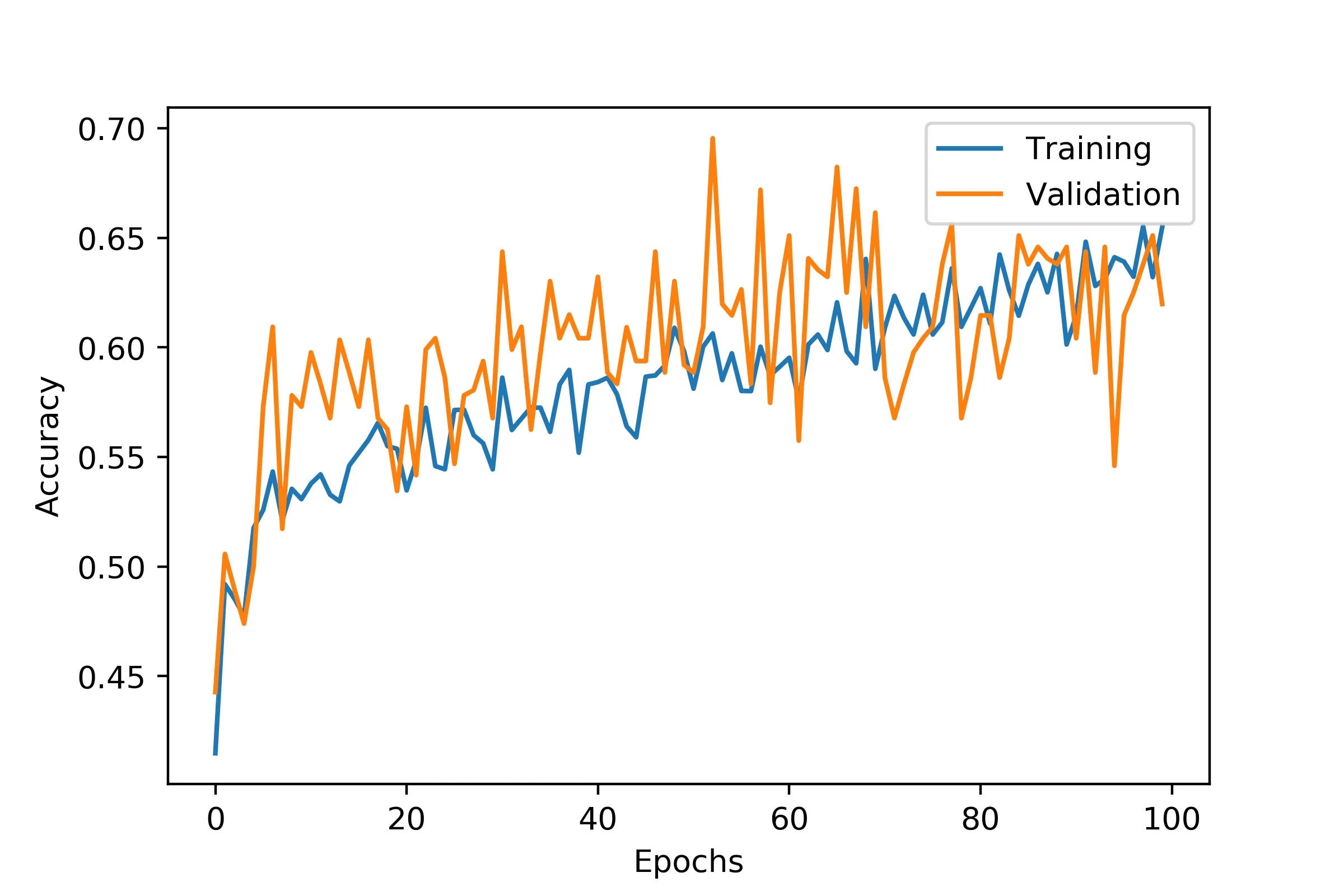
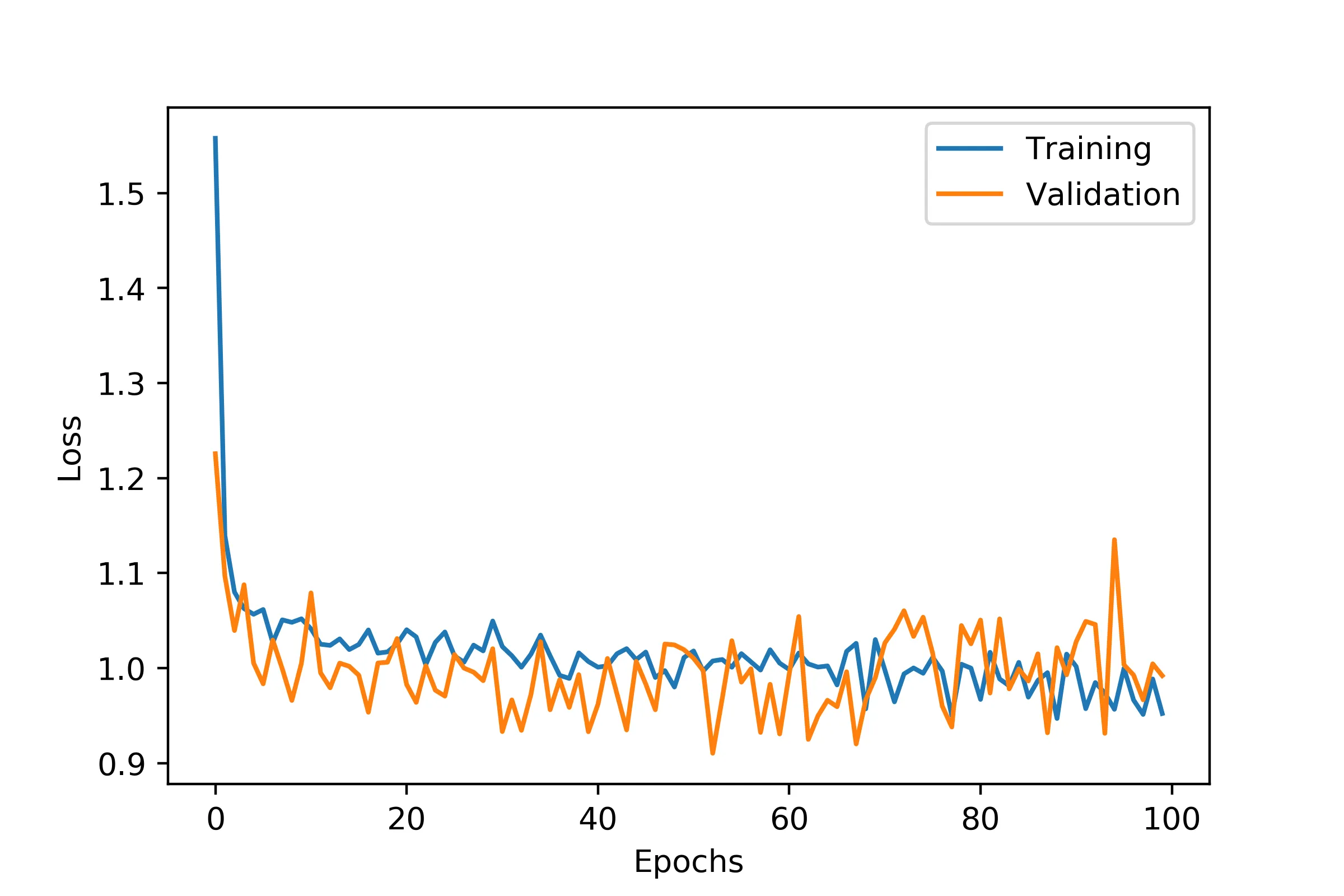
如果我将架构变得更深,它要么会过拟合得很严重,要么会像疯子一样跳来跳去,即使我更加严格地正则化它,甚至有一次达到了100%:
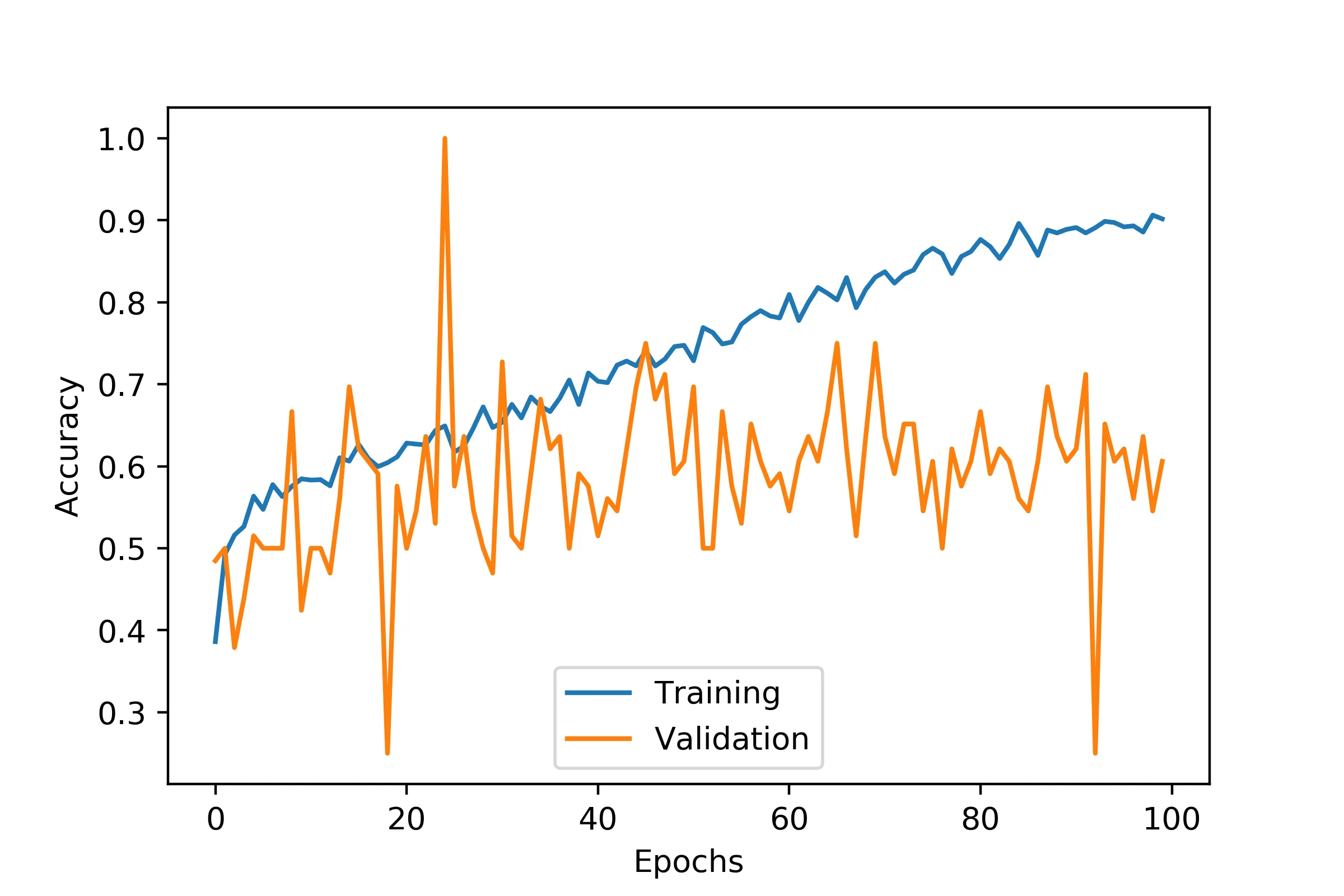
我也尝试使用批量标准化,但是模型几乎没有学习,训练集的准确率不到50%。我尝试了带和不带dropout。
我正在寻找除了过度修改架构之外改进模型的其他方法。我看到其中一个选项是重复使用具有其权重的现有体系结构并将其插入到我的模型中。但是我找不到任何真正的例子来说明如何做到这一点。我主要是按照这篇博客文章进行的: https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
它讨论了重复使用VGG19以提高准确性,但实际上并没有解释如何做到这一点。是否有其他示例可以遵循?我应该如何将其适应到我的当前实现中?我找到了完整的模型架构,但在我的硬件上无法运行,因此我正在寻找一种重复使用已经训练好的模型权重并将其适应于我的问题的方法。
此外,我不理解博客中VGG部分所谈论的“瓶颈特征”的概念。如果有人能解释一下就好了。