使用透视变换对图像进行倾斜

1
一个更好的方法是通过反向映射来实现。
本质上,您想要“扭曲”图像,对吧?这意味着源图像中的每个像素都会到达预定义点 - 预定义是一个变换矩阵,告诉您如何旋转、缩放、平移、剪切等图像,这实际上是将图像上的某些坐标(x,y)取出,并说:“好的,这个像素的新位置是(f(x),g(y))。”
这就是“扭曲”的本质。
现在,考虑缩放图像...比如将其放大十倍。这意味着像素点(1,1)变成了新图像中的像素点(10,10),然后下一个像素点(1,2)变成了新图像中的像素点(10,20)。但是如果你继续这样做,你将没有一个像素点(13,13)的值,因为在原始图像中(1.3,1.3)是未定义的,你的新图像中会有一堆空洞 - 你必须使用新图像中周围的四个像素点进行插值,即(10,10)、(10,20)、(20,10)、(200,2) - 这被称为双线性插值。
但是这里还有另一个问题,假设你的变换不是简单的缩放,而是仿射变换(就像你发布的示例图像)-那么(1,1)将变成类似于(2.34,4.21)的东西,然后您必须在输出图像中将它们舍入为(2,4),然后您必须对新图像进行双线性插值以填充空洞或更复杂的插值-混乱对吧?
现在,没有办法避免插值,但我们可以通过仅执行一次双线性插值来摆脱它。怎么做?简单,使用反向映射。
不要把它看作源图像到新图像的过程,而是考虑新图像的数据将从源图像的哪里获取!因此,在新图像中的(1,1)将来自源图像中的某些反向映射,例如(3.4,2.1),然后在源图像上进行双线性插值以找出相应的值!
变换矩阵
好的,那么如何为仿射变换定义转换矩阵呢?这个网站告诉你如何通过合成旋转、剪切等不同的变换矩阵来实现。
变换:
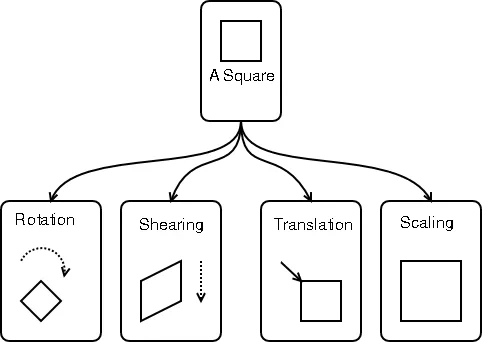
(来源:mathieu at people.gnome.org)
合成:
最终矩阵可以通过按顺序组合每个矩阵并将其反转来获得逆映射 - 使用此方法计算源图像中像素的位置并进行插值。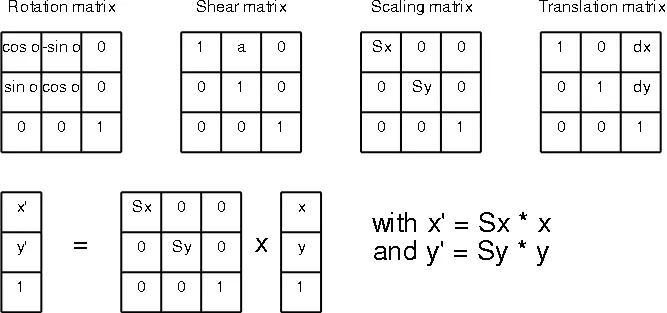
{kind=link}
{kind=link}
{kind=link}
1
正如KennyTM所评论的那样,您只需要一个仿射变换,它是通过将每个像素乘以矩阵M并将结果加到平移向量V中获得的线性映射。这是简单的数学。
end_pixel_position = M*start_pixel_position + V
其中M是由旋转或缩放等简单变换组成的复合变换,V是一个向量,通过为每个像素添加固定系数来平移图像的每个点。
例如,如果您想旋转图像,则可以定义一个旋转矩阵:
| cos(a) -sin(a) |
M = | |
| sin(a) cos(a) |
其中 a 是您想要旋转图像的角度。
而缩放使用以下形式的矩阵:
| s1 0 |
M = | |
| 0 s2 |
其中s1和s2是两个轴上的缩放因子。
翻译时,您只需要考虑向量V:
| t1 |
V = | |
| t2 |
该技术涉及到添加t1和t2到像素坐标中的矩阵变换。
然后,您可以将这些矩阵组合成一个单一的变换。例如,如果您有缩放、旋转和平移,则最终会得到以下内容:
| x2 | | x1 |
| | = M1 * M2 * | | + T
| y2 | | y1 |
其中:
x1和y1是应用变换前的像素坐标,x2和y2是应用变换后的像素坐标,M1和M2是用于缩放和旋转的矩阵(记住:矩阵的组合不是可交换的!通常情况下,M1 * M2 * Vect != M2 * M1 * Vect),T是用于将每个像素平移的平移向量。
原文链接